




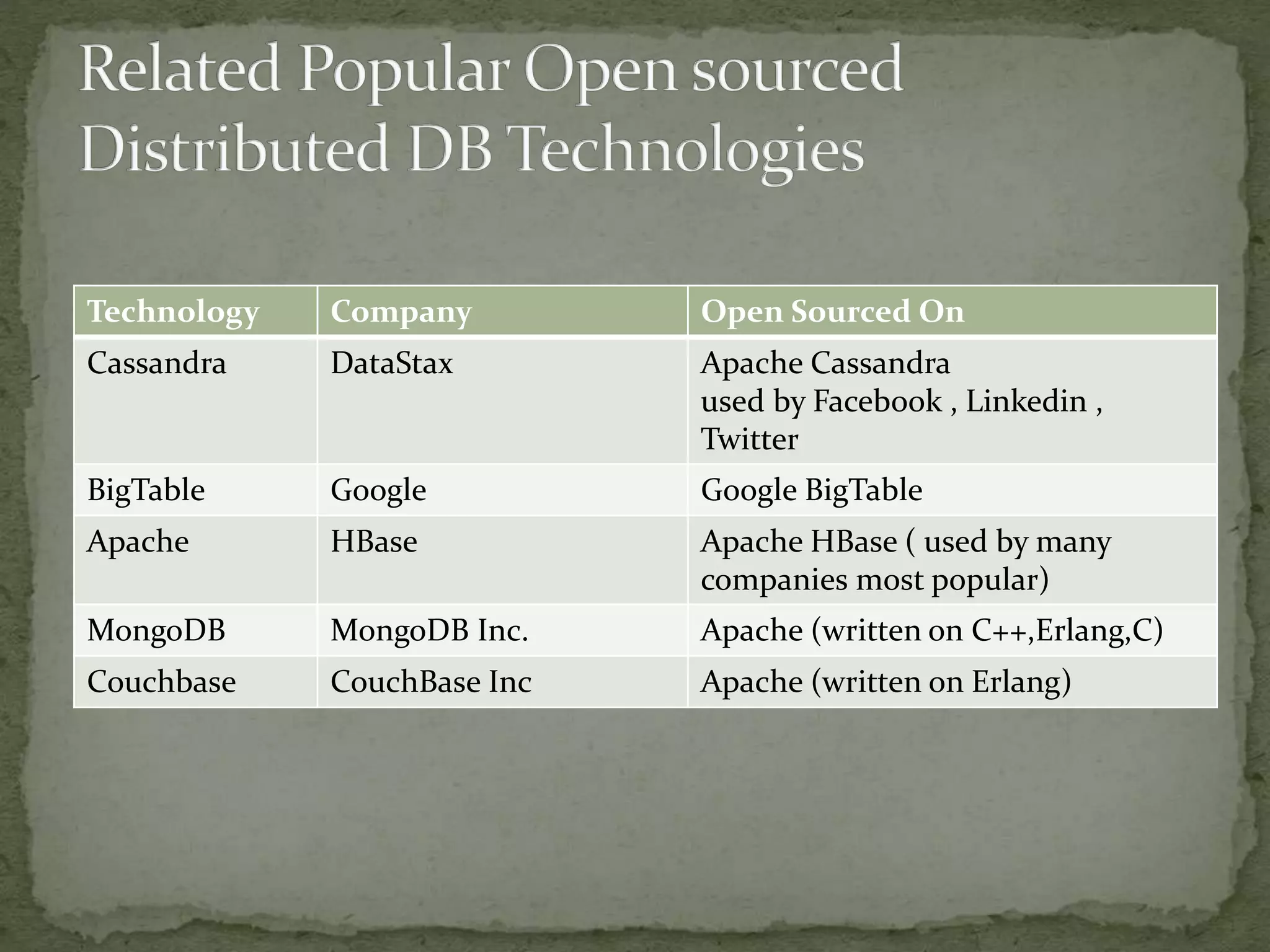




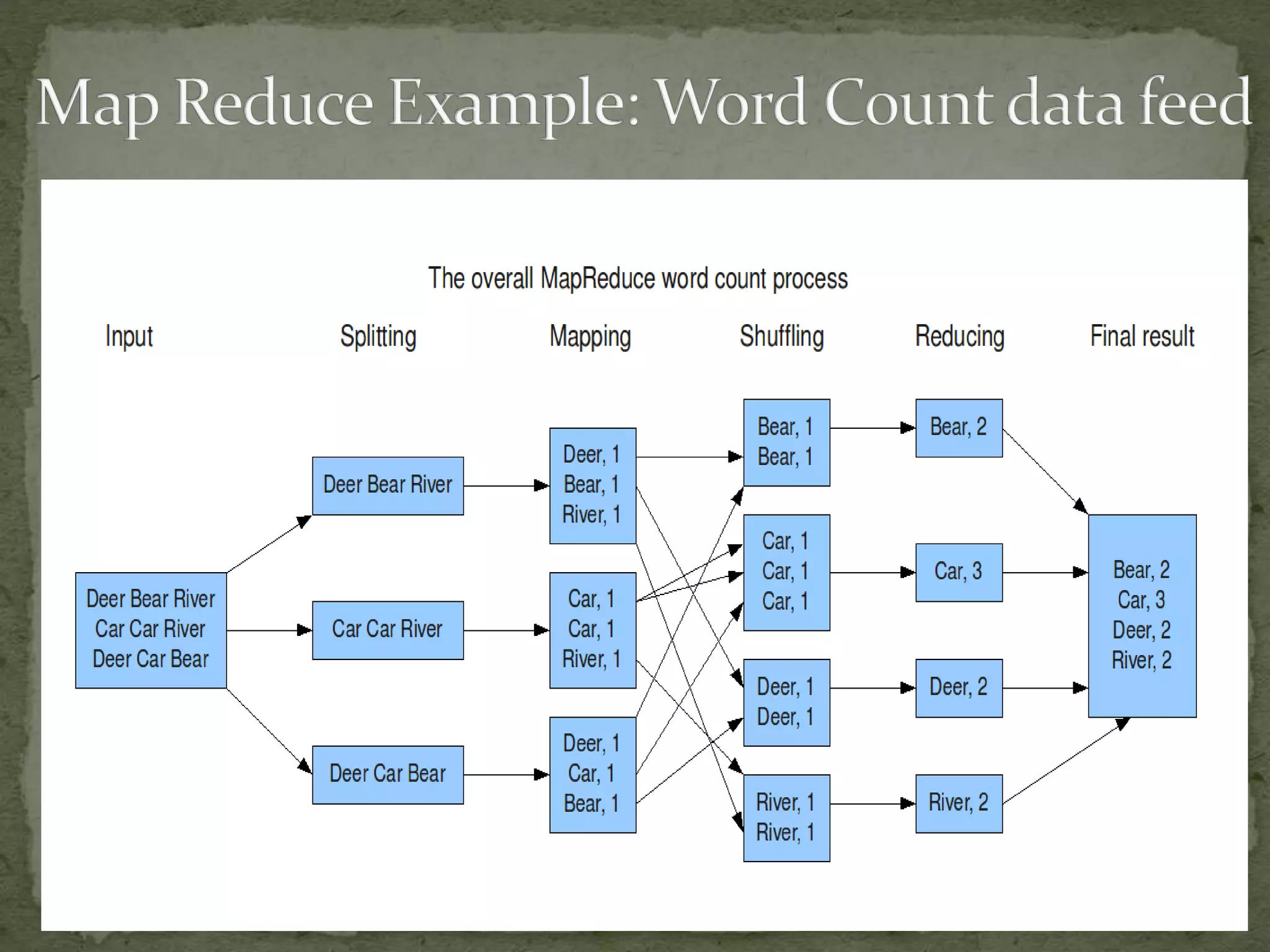


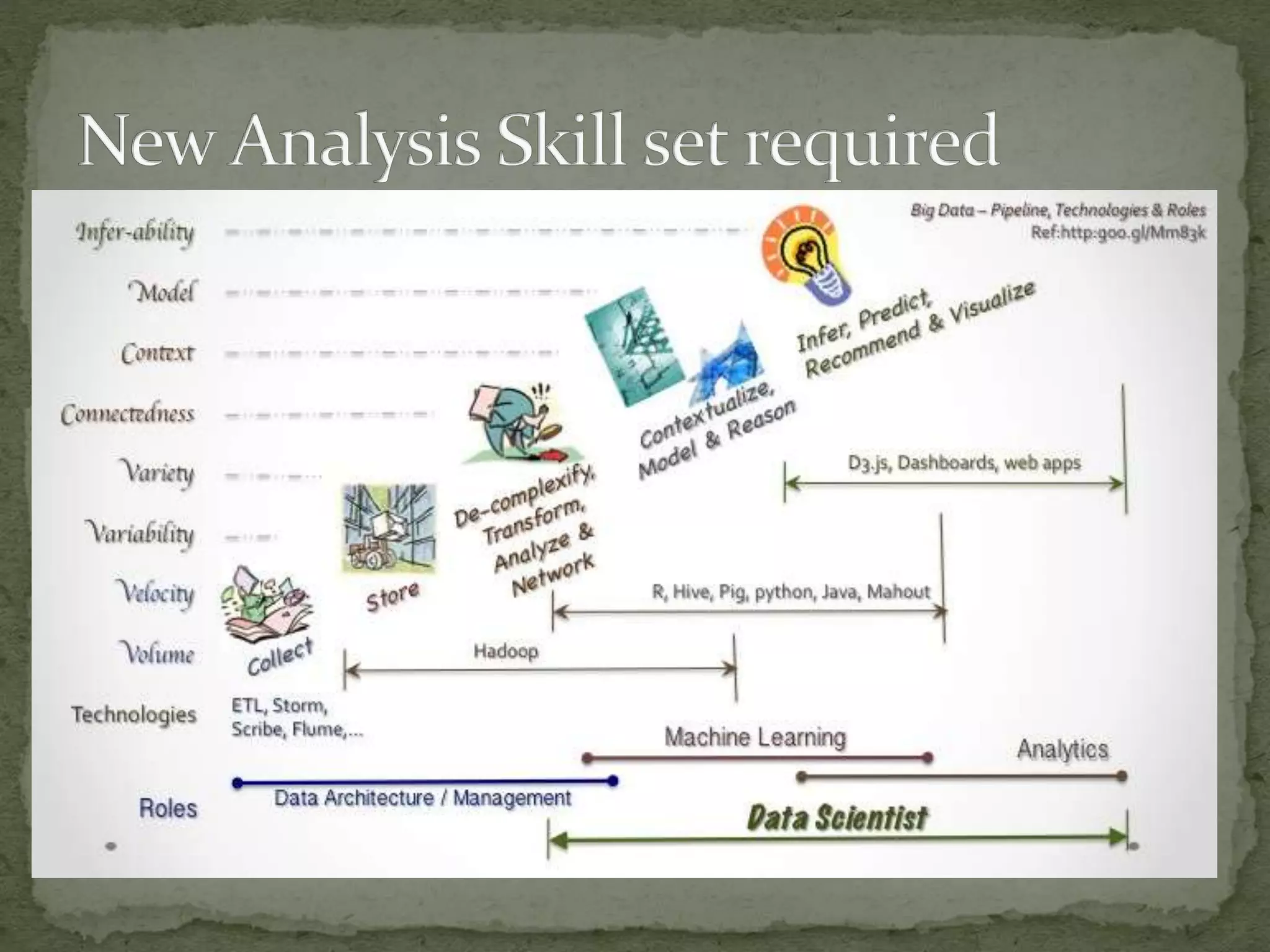







The document discusses the concept of big data characterized by the 5 V's: volume, variety, velocity, variability, and value, highlighting its significance across various platforms like YouTube, Facebook, and Twitter. It explains the shift from traditional relational database management systems (DBMS) to NoSQL databases that handle unstructured data more efficiently, along with technologies such as Hadoop and data science tools like R and Pig for data analysis. Lastly, it emphasizes the importance of big data in sectors like retail and finance, where real-time data analysis is crucial for making informed decisions.























































































