Download to read offline





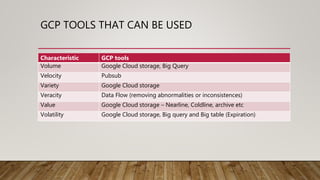
Big data is characterized by large and complex datasets that are difficult to process using traditional software. These massive volumes of data, known by characteristics like volume, velocity, variety, veracity, value, and volatility, can provide insights to address business problems. Google Cloud Platform offers tools like Cloud Storage, Big Query, PubSub, Dataflow, and Cloud Storage storage classes that can handle big data according to these characteristics and help extract value from large and diverse datasets.



































































