



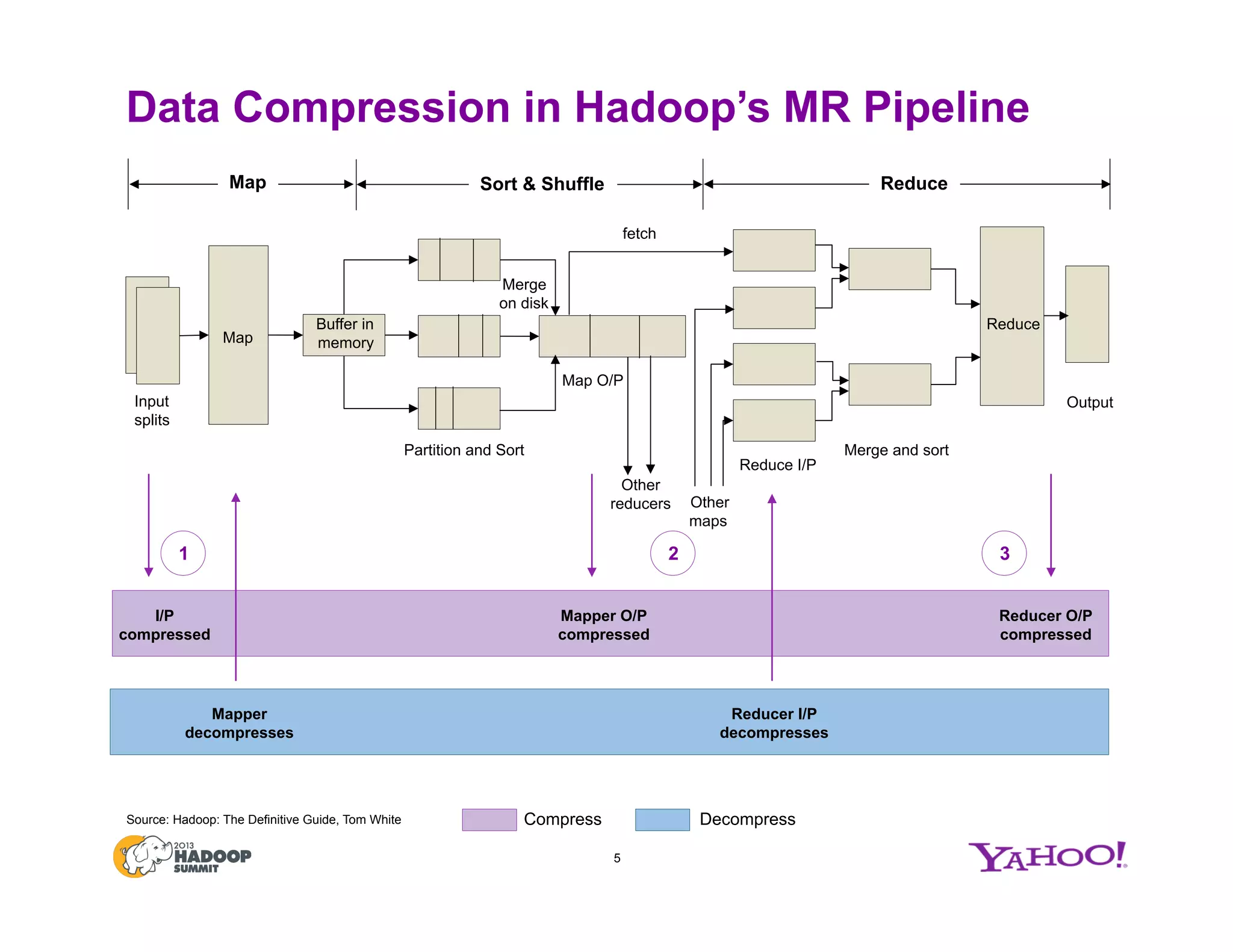
![Space-Time Tradeoff of Compression Options
8
64%, 32.3
71%, 60.0
47%, 4.842%, 4.0
44%, 2.4
0.0
10.0
20.0
30.0
40.0
50.0
60.0
70.0
40% 45% 50% 55% 60% 65% 70% 75%
CPUTimeinSec.
(Compress+Decompress)
Space Savings
Bzip2
Zlib
(Deflate, Gzip)
LZOSnappy
LZ4
Note:
A 265 MB corpus from Wikipedia was used for the performance comparisons.
Space savings is defined as [1 – (Compressed/ Uncompressed)]
Codec Performance on the Wikipedia Text Corpus
High Compression Ratio
High Compression Speed](https://image.slidesharecdn.com/singhjune27425pm210cvfinal-150707045122-lva1-app6891/75/Hadoop-Summit-San-Jose-2013-Compression-Options-in-Hadoop-A-Tale-of-Tradeoffs-8-2048.jpg)
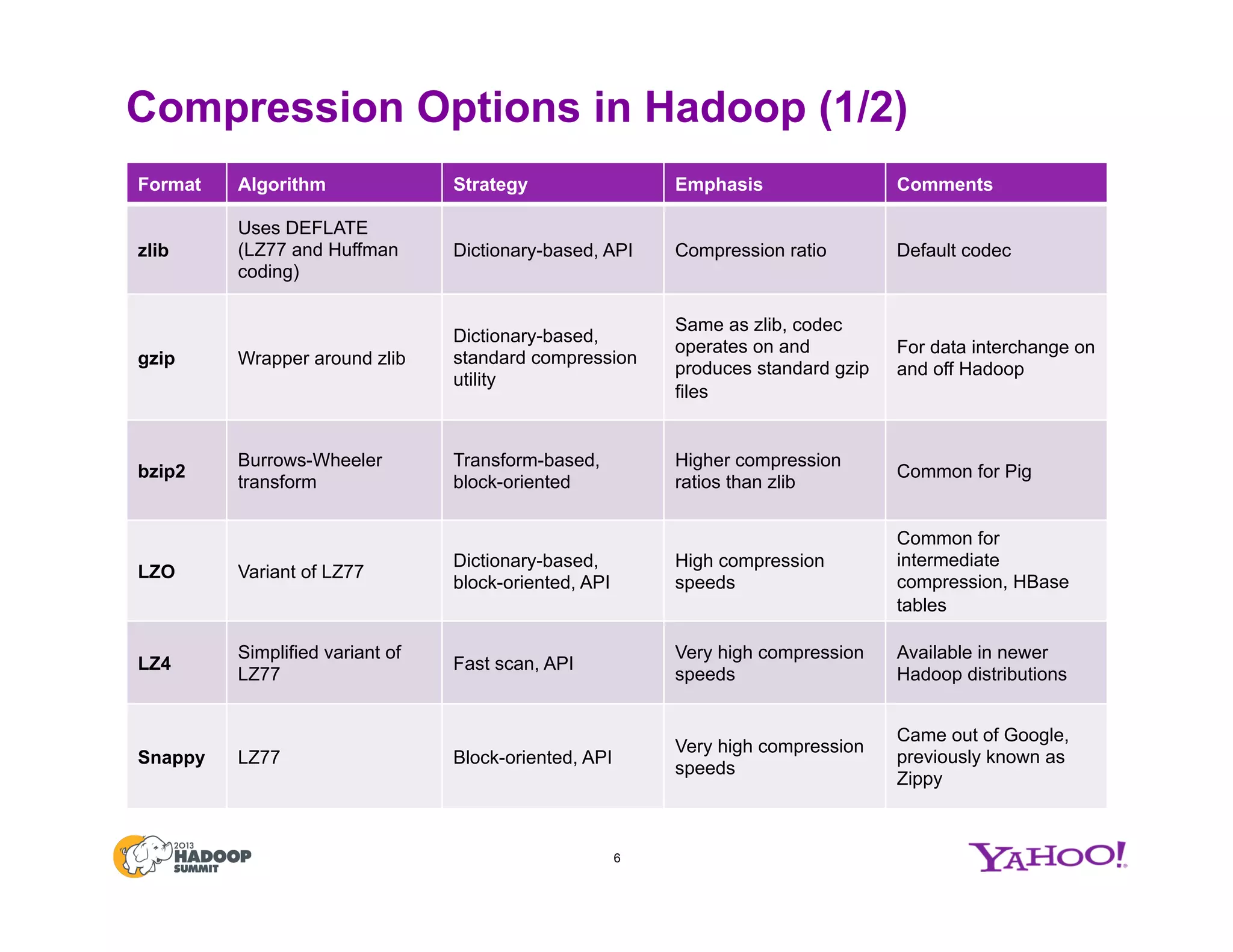
![Using Data Compression in Hadoop
9
Phase in MR
Pipeline
Config Values
Input data to
Map
File extension recognized automatically for
decompression
File extensions for supported formats
Note: For SequenceFile, headers have the
information [compression (boolean), block
compression (boolean), and compression
codec]
One of the supported codecs one defined in io.compression.codecs!
Intermediate
(Map) Output
mapreduce.map.output.compress!
false (default), true
mapreduce.map.output.compress.codec!
!
one defined in io.compression.codecs!
Final
(Reduce)
Output
mapreduce.output.fileoutputformat.
compress!
false (default), true
mapreduce.output.fileoutputformat.
compress.codec!
one defined in io.compression.codecs!
mapreduce.output.fileoutputformat.
compress.type!
Type of compression to use for SequenceFile
outputs: NONE, RECORD (default), BLOCK
1
2
3](https://image.slidesharecdn.com/singhjune27425pm210cvfinal-150707045122-lva1-app6891/75/Hadoop-Summit-San-Jose-2013-Compression-Options-in-Hadoop-A-Tale-of-Tradeoffs-9-2048.jpg)
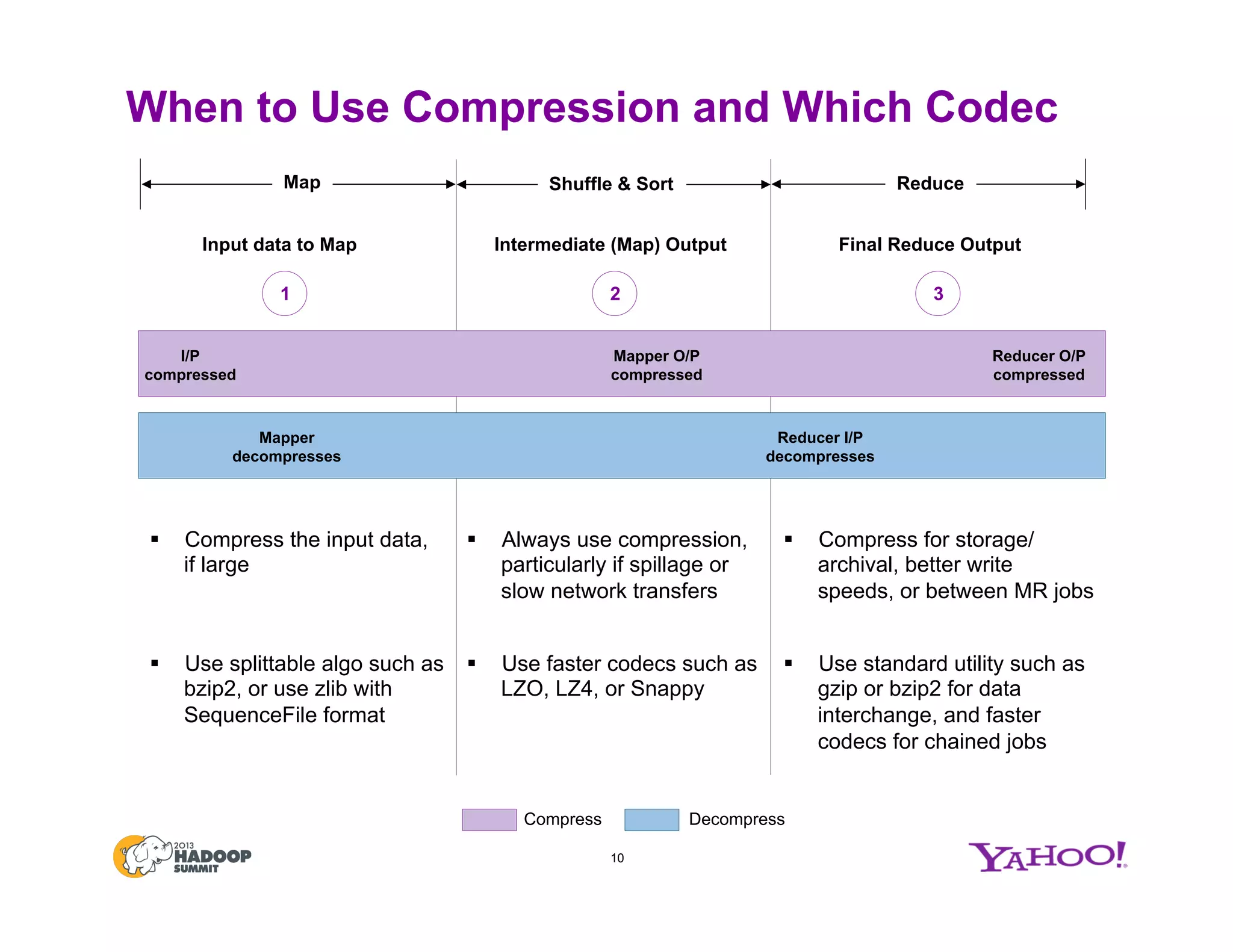

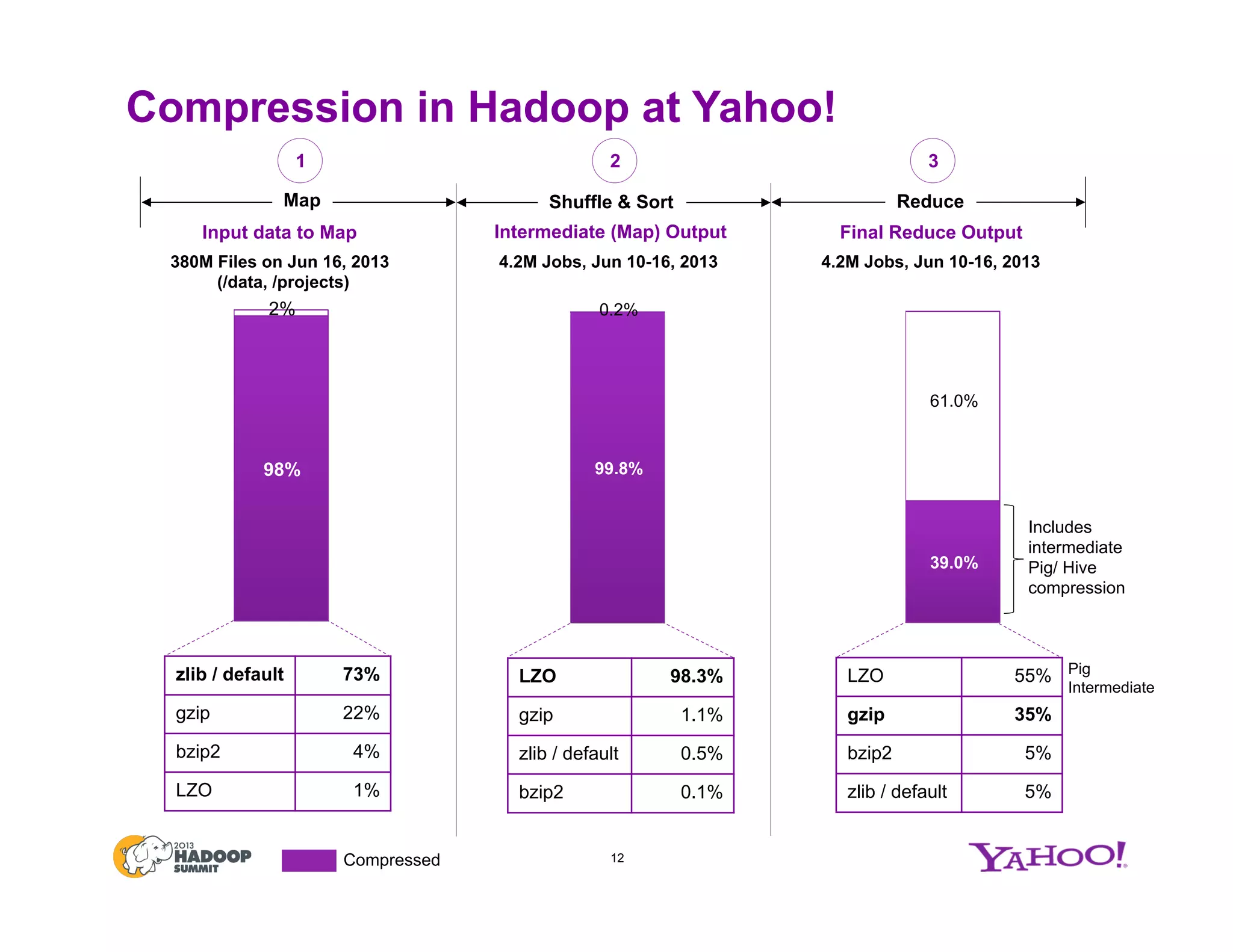




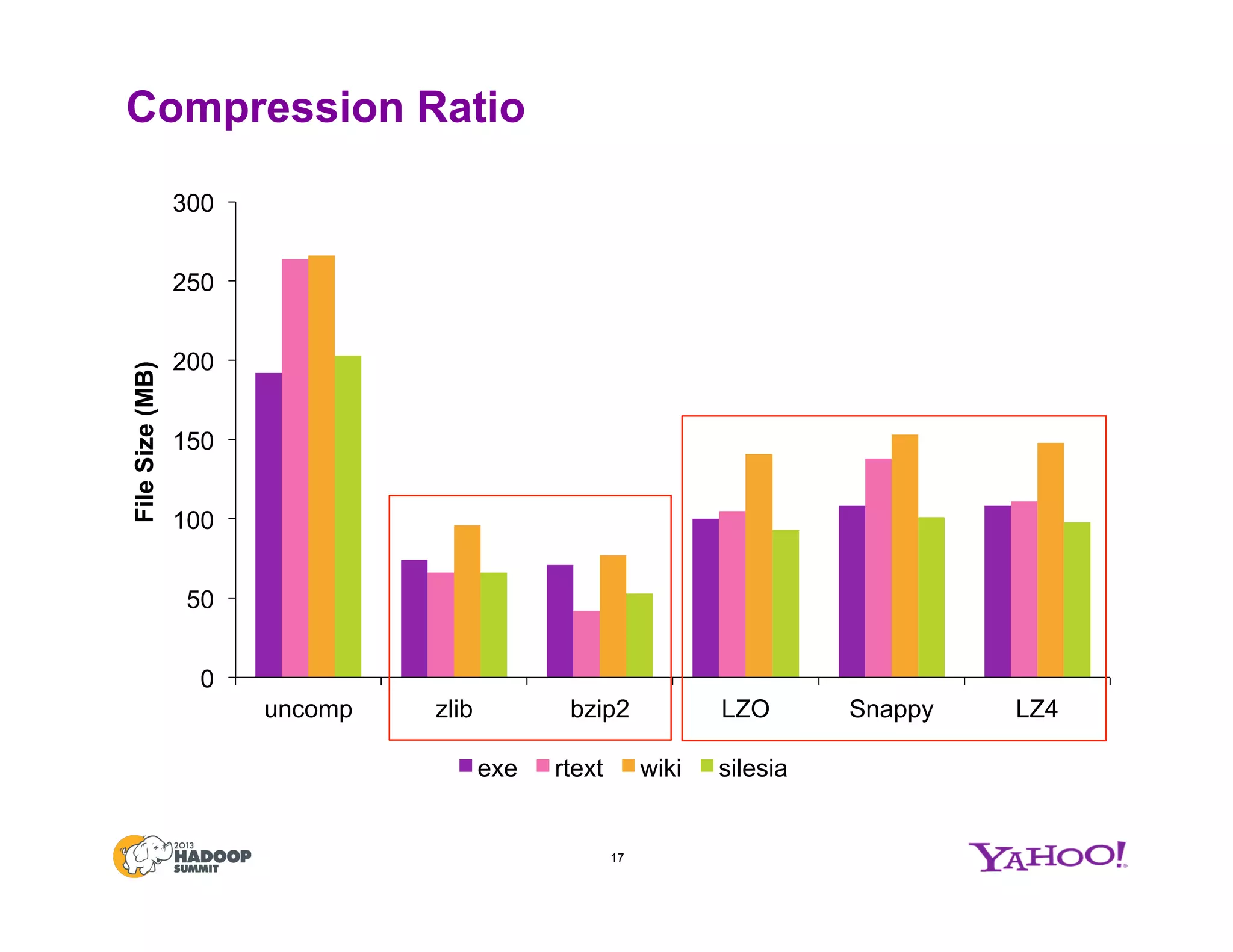
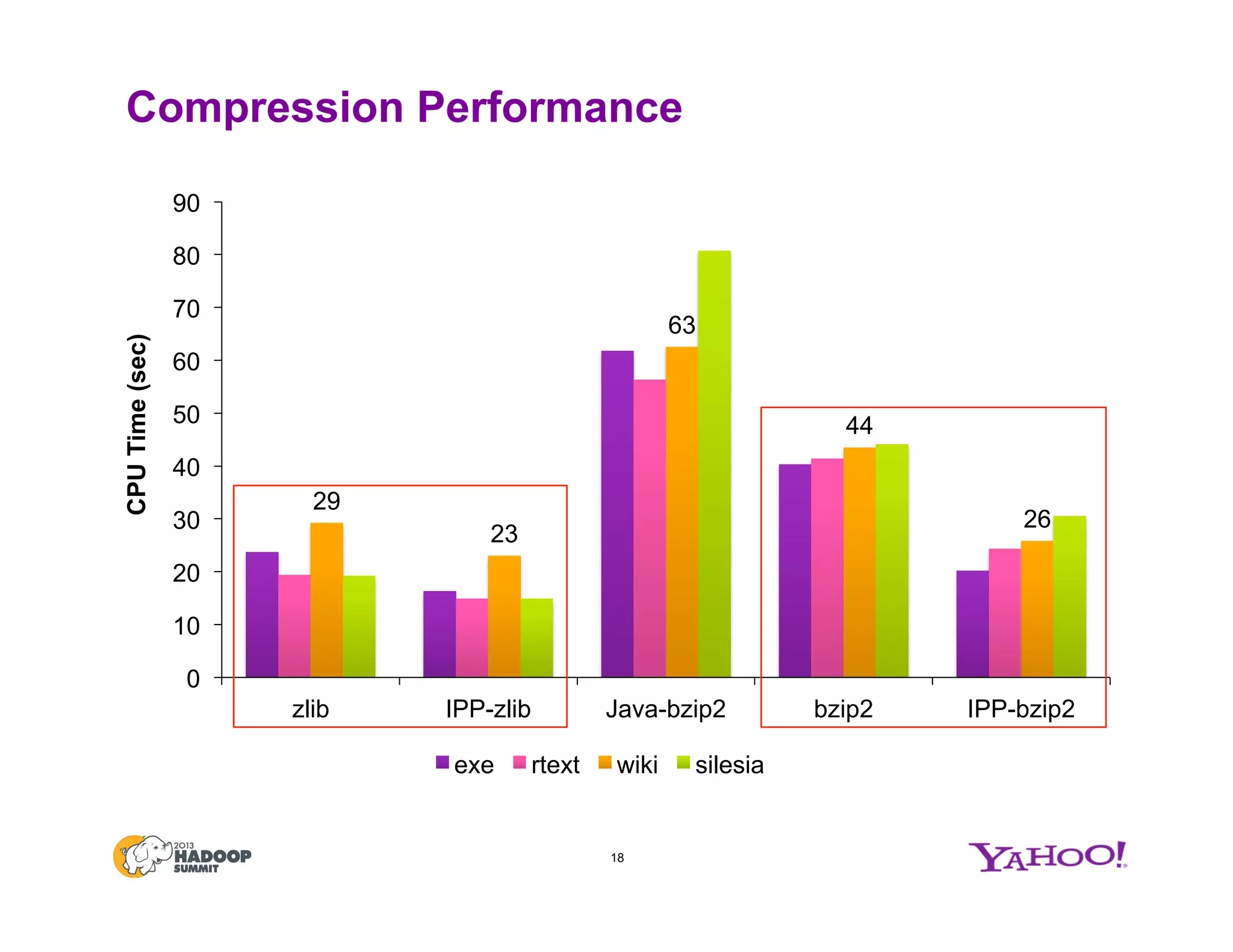
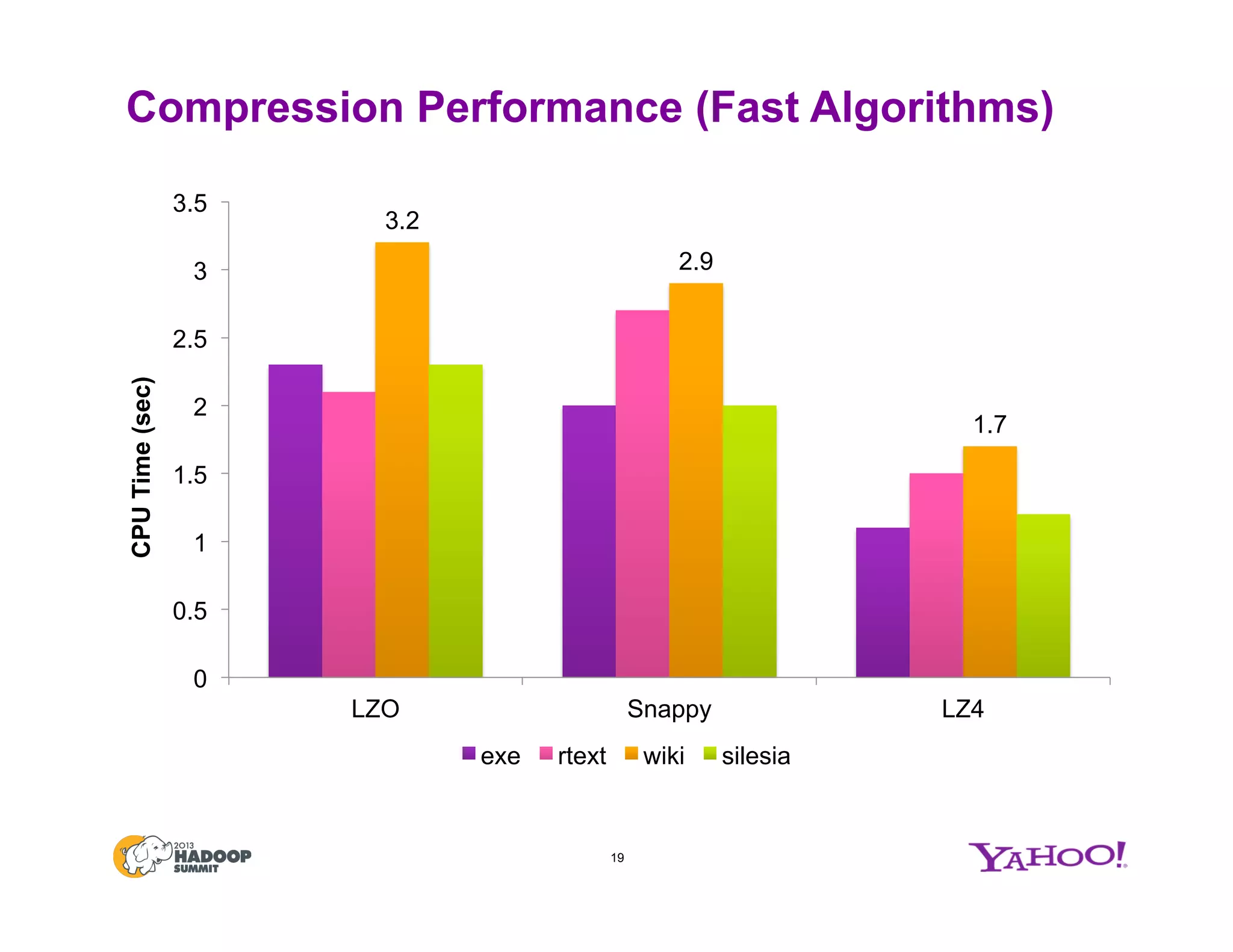
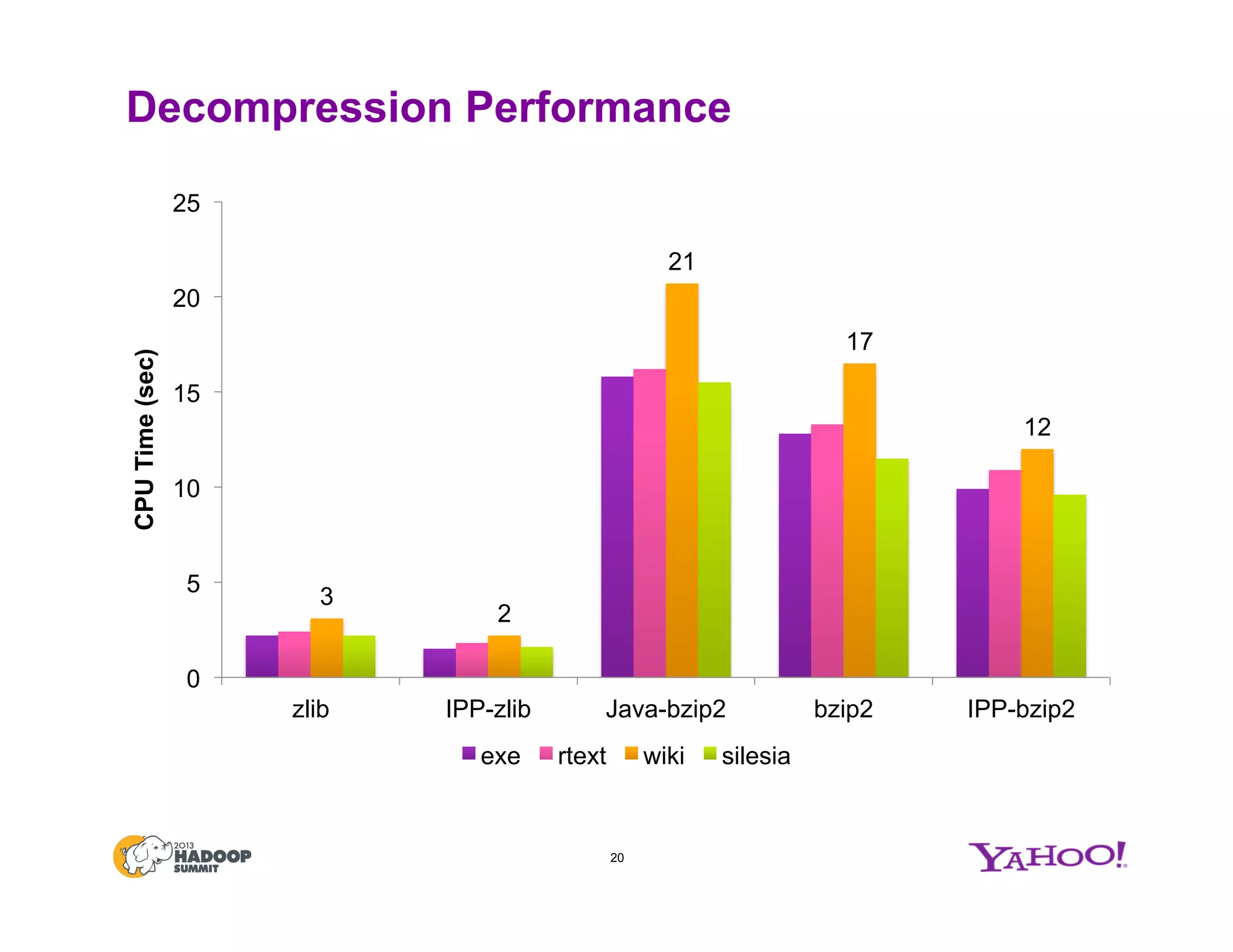
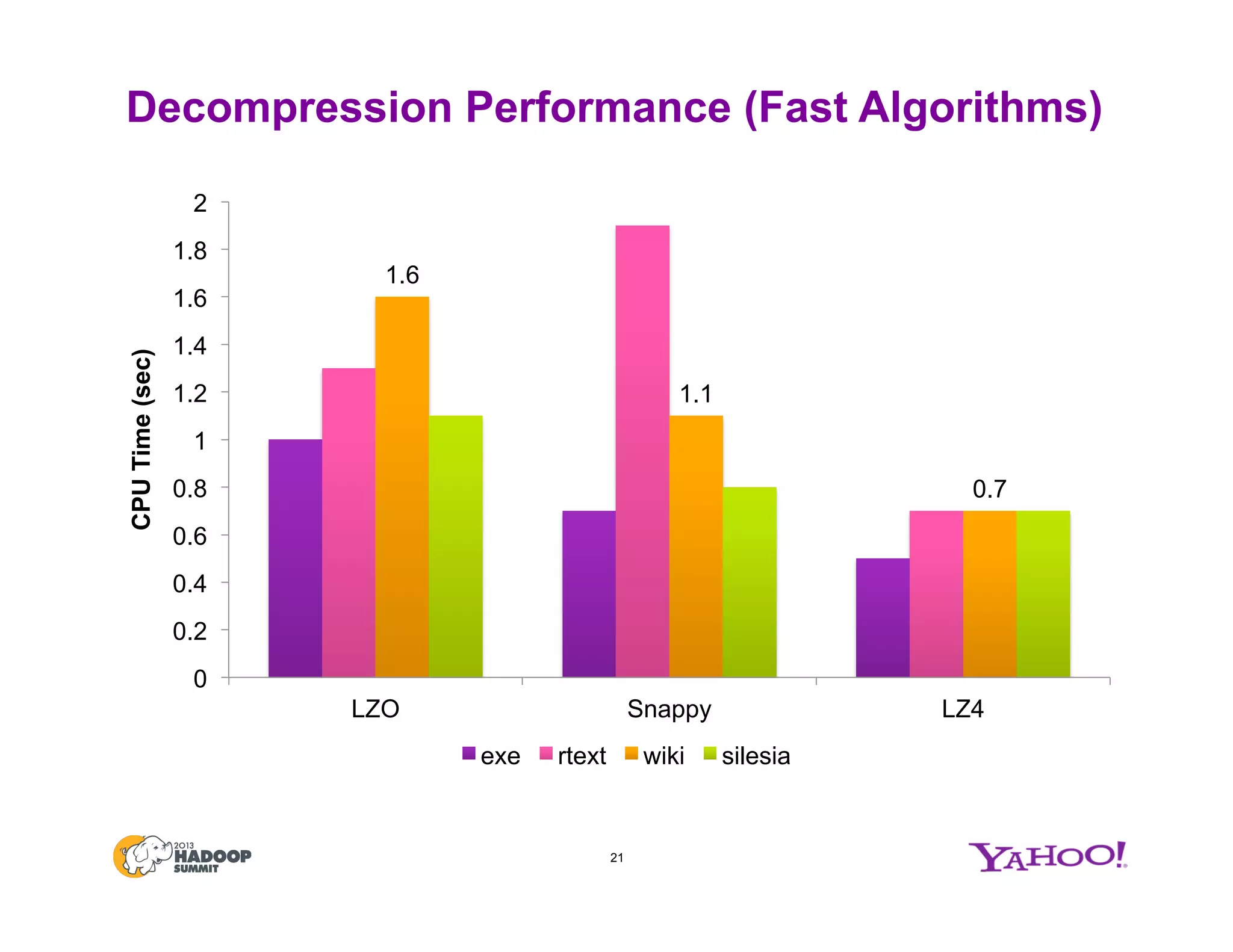


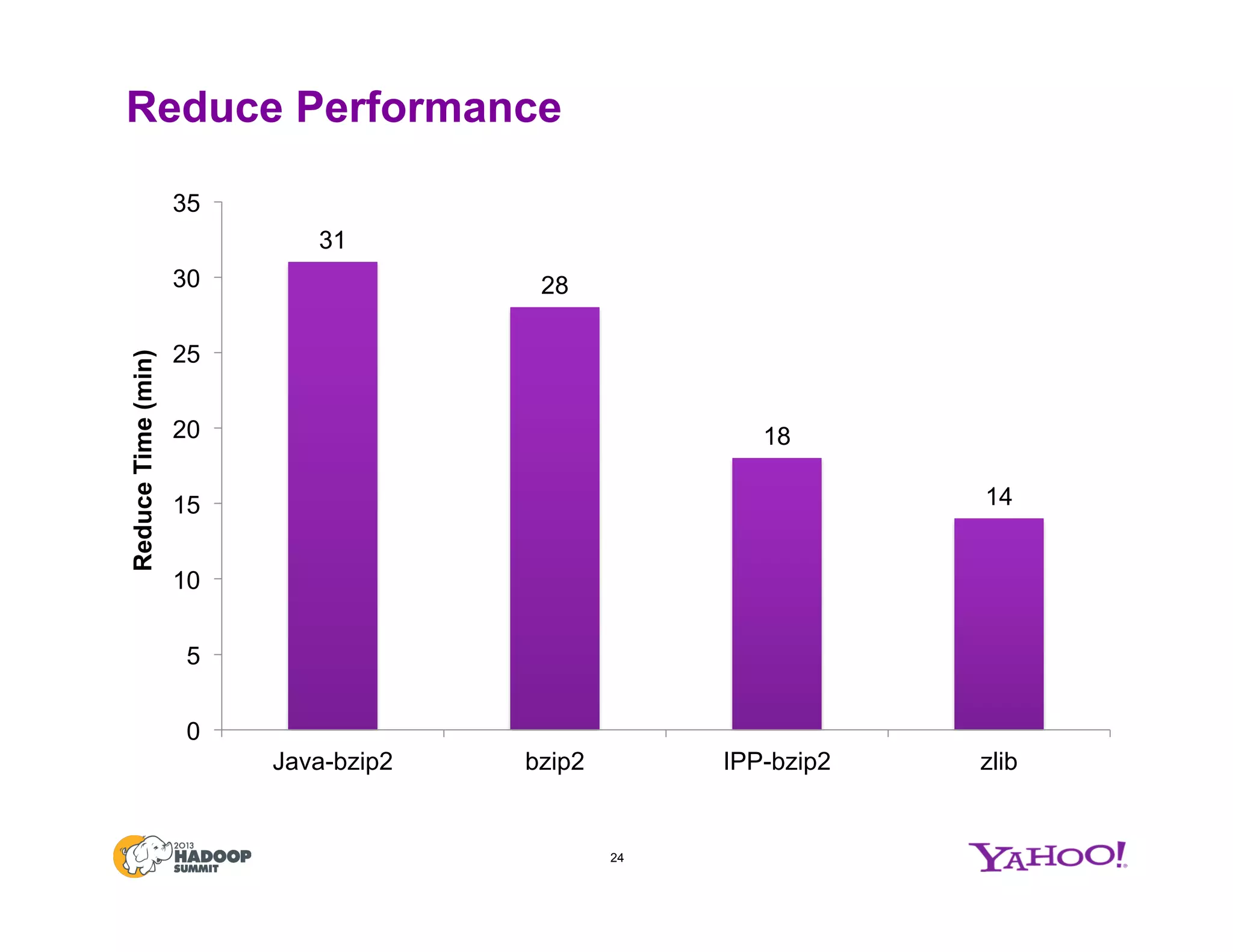
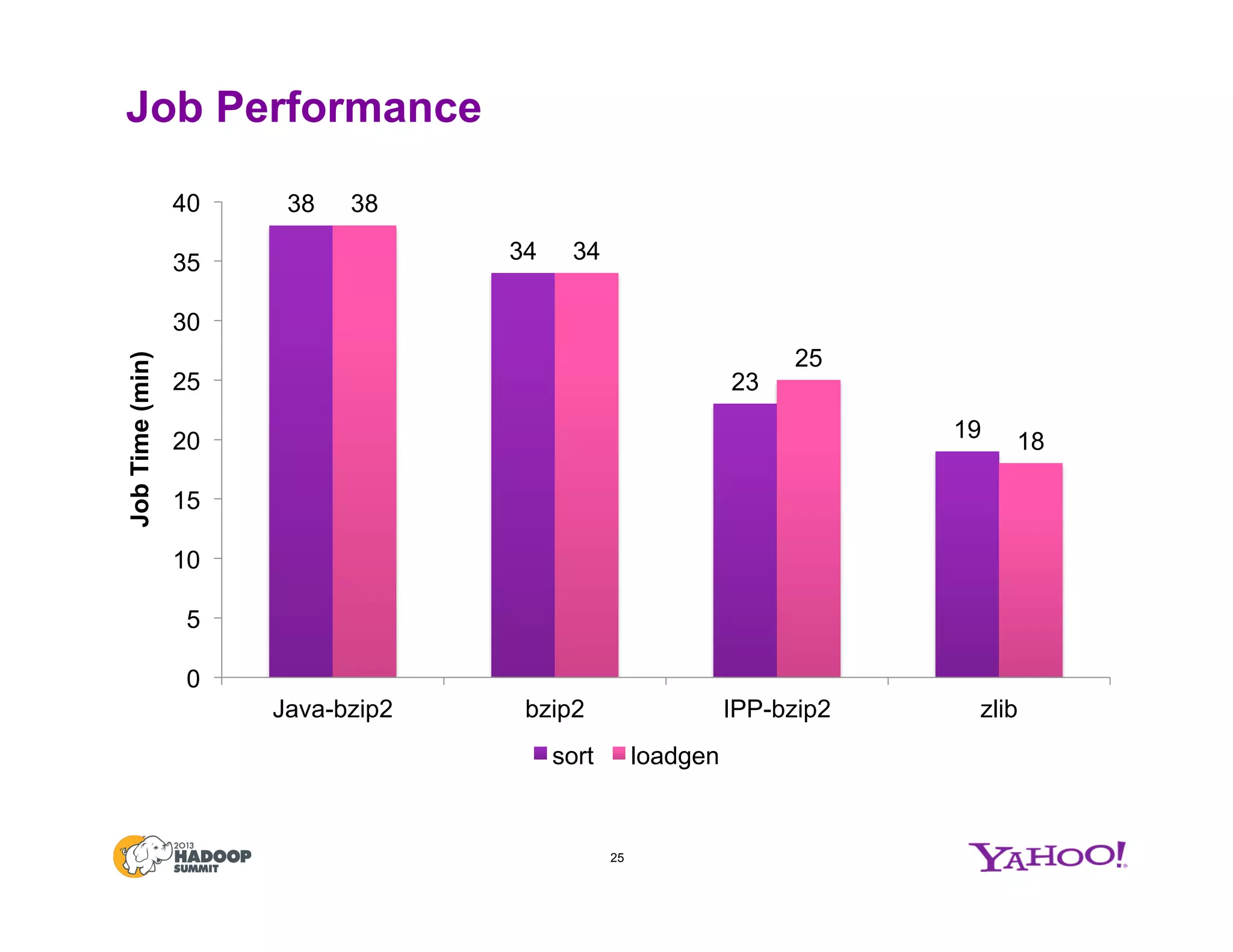




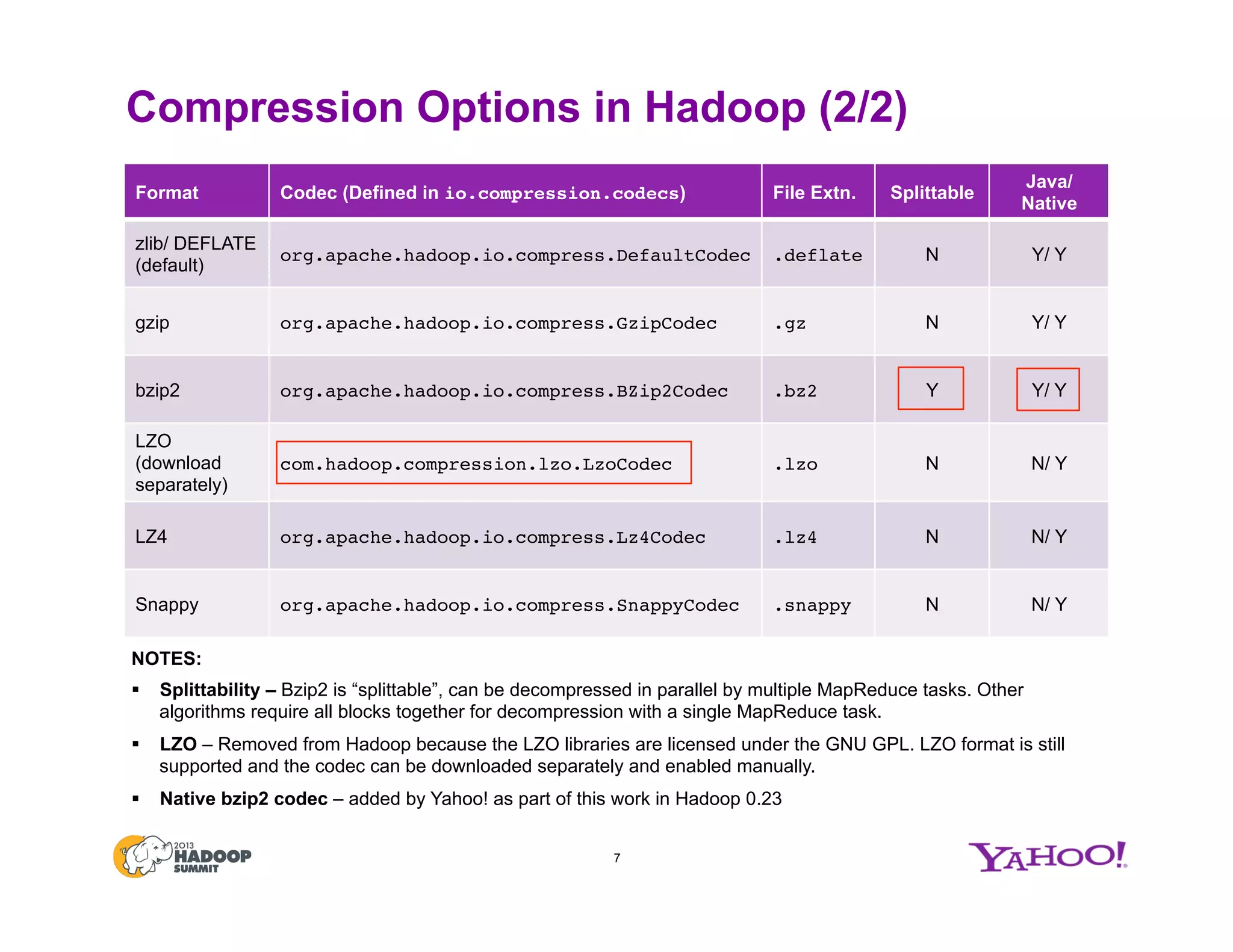
The document discusses various data compression options in Hadoop, emphasizing the trade-offs between compression speed, CPU utilization, and overall performance for data-intensive MapReduce jobs. It outlines the different compression algorithms available, such as zlib, bzip2, lzo, lz4, and snappy, along with their characteristics and use cases within the Hadoop ecosystem. Additionally, the document addresses the current usage and performance evaluations of these codecs at Yahoo!, highlighting the importance of selecting the right compression technique based on specific data and project needs.

















































































