Downloaded 888 times







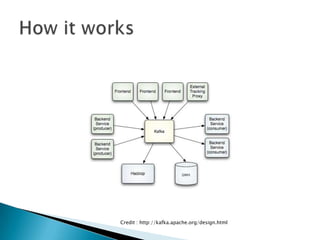
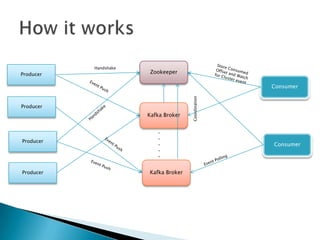
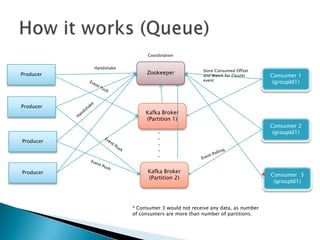

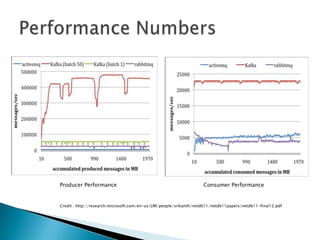



This document discusses Apache Kafka, an open-source distributed event streaming platform. It provides an introduction to Kafka's design and capabilities including: 1) Kafka is a distributed publish-subscribe messaging system that can handle high throughput workloads with low latency. 2) It is designed for real-time data pipelines and activity streaming and can be used for transporting logs, metrics collection, and building real-time applications. 3) Kafka supports distributed, scalable, fault-tolerant storage and processing of streaming data across multiple producers and consumers.


















































































