


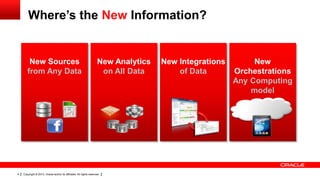




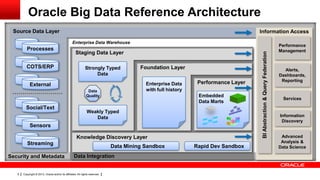
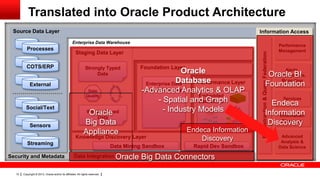

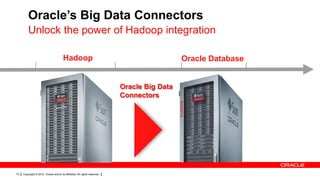
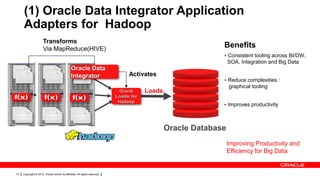
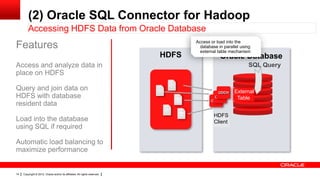
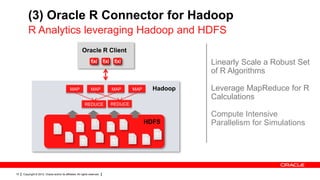

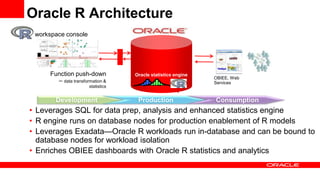

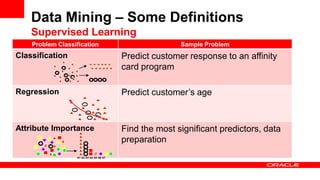
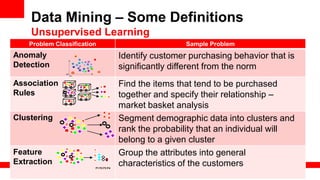
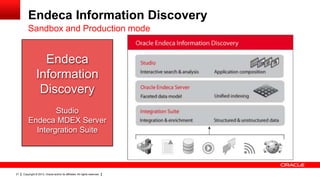
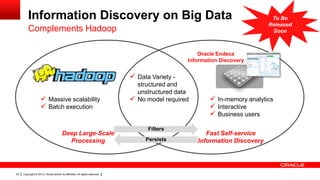




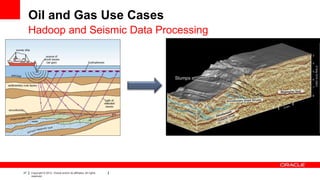





The document discusses big data's significance, its sources, analytics, and integration technologies, particularly highlighting Oracle's role and solutions. It describes the architecture for managing and analyzing big data, including Oracle's data connectors and analytics tools, while addressing industry-specific challenges. Additionally, it examines various use cases in sectors like finance, telecommunications, retail, and healthcare, along with Switzerland's involvement in the big data landscape.











































































































