


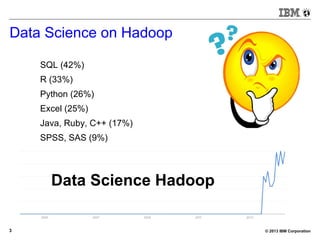




![© 2013 IBM Corporation21
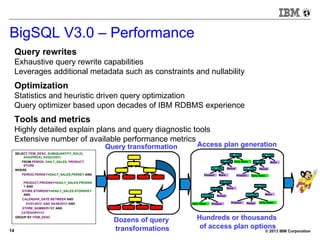
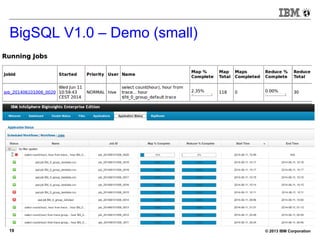
BigSQL V1.0 – Demo (small)
[bivm.ibm.com][biadmin] 1> select count(*) from trace1;
+----------+
| |
+----------+
| 11416740 |
+----------+
1 row in results(first row: 39.78s; total: 39.78s)](https://image.slidesharecdn.com/sqlonhadoopmaster-140704022719-phpapp01/85/SQL-on-Hadoop-21-320.jpg)

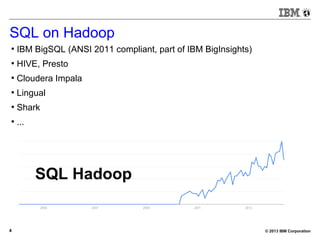
![© 2013 IBM Corporation23
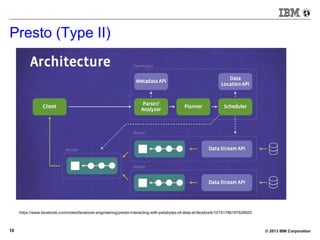
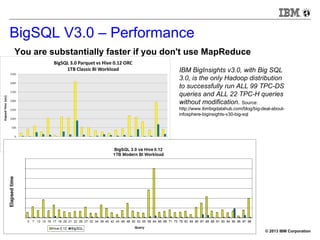
BigSQL V1.0 – Demo (small)
[bivm.ibm.com][biadmin] 1> select count(*) from trace1 t3 inner
join trace2 t4 on t3.hour=t4.hour;
+--------+
| |
+--------+
| 477340 |
+--------+
1 row in results(first row: 32.24s; total: 32.25s)](https://image.slidesharecdn.com/sqlonhadoopmaster-140704022719-phpapp01/85/SQL-on-Hadoop-23-320.jpg)

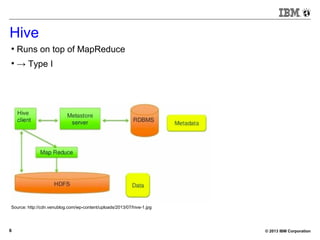
![© 2013 IBM Corporation25
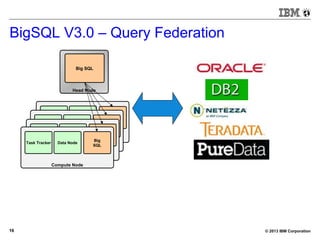
BigSQL V3.0 – Demo (small)
[bivm.ibm.com][biadmin] 1> select count(*) from trace3;
+----------+
| 1 |
+----------+
| 12014733 |
+----------+
1 row in results(first row: 2.94s; total: 2.95s)](https://image.slidesharecdn.com/sqlonhadoopmaster-140704022719-phpapp01/85/SQL-on-Hadoop-25-320.jpg)
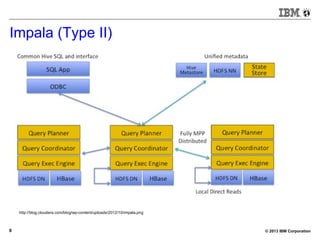
![© 2013 IBM Corporation26
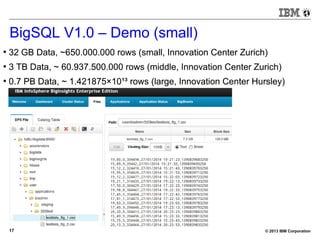
BigSQL V3.0 – Demo (small)
[bivm.ibm.com][biadmin] 1> select count(*) from trace3 t3 inner
join trace4 t4 on t3.hour=t4.hour;
+--------+
| 1 |
+--------+
| 504360 |
+--------+
1 row in results(first row: 0.79s; total: 0.80s)](https://image.slidesharecdn.com/sqlonhadoopmaster-140704022719-phpapp01/85/SQL-on-Hadoop-26-320.jpg)
![© 2013 IBM Corporation27
BigSQL V3.0 – Demo (small)
[bivm.ibm.com][biadmin] 1> select count(hour), hour from trace3
group by hour order by hour;
29 rows in results(first row: 1.88s; total: 1.89s)](https://image.slidesharecdn.com/sqlonhadoopmaster-140704022719-phpapp01/85/SQL-on-Hadoop-27-320.jpg)


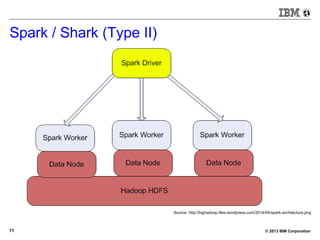
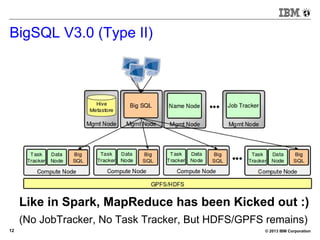
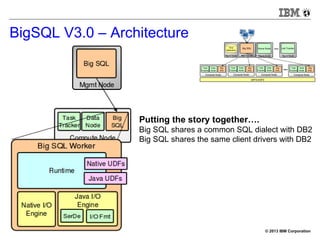
The document discusses SQL on Hadoop, highlighting various tools and SQL engines such as Hive, Impala, and BigSQL. It focuses on the evolution and performance of these technologies in data science, particularly emphasizing the improvements offered by BigSQL v3.0 over previous implementations. Additionally, it presents performance metrics and demo results showcasing the efficiency of BigSQL in handling large datasets.













![[db tech showcase OSS 2017] A23: Analytics with MariaDB ColumnStore by MariaD...](https://cdn.slidesharecdn.com/ss_thumbnails/mariadbcolumnstore-dbtechshowcasetokyo2017-170628024921-thumbnail.jpg?width=640&height=640&fit=bounds)










































































