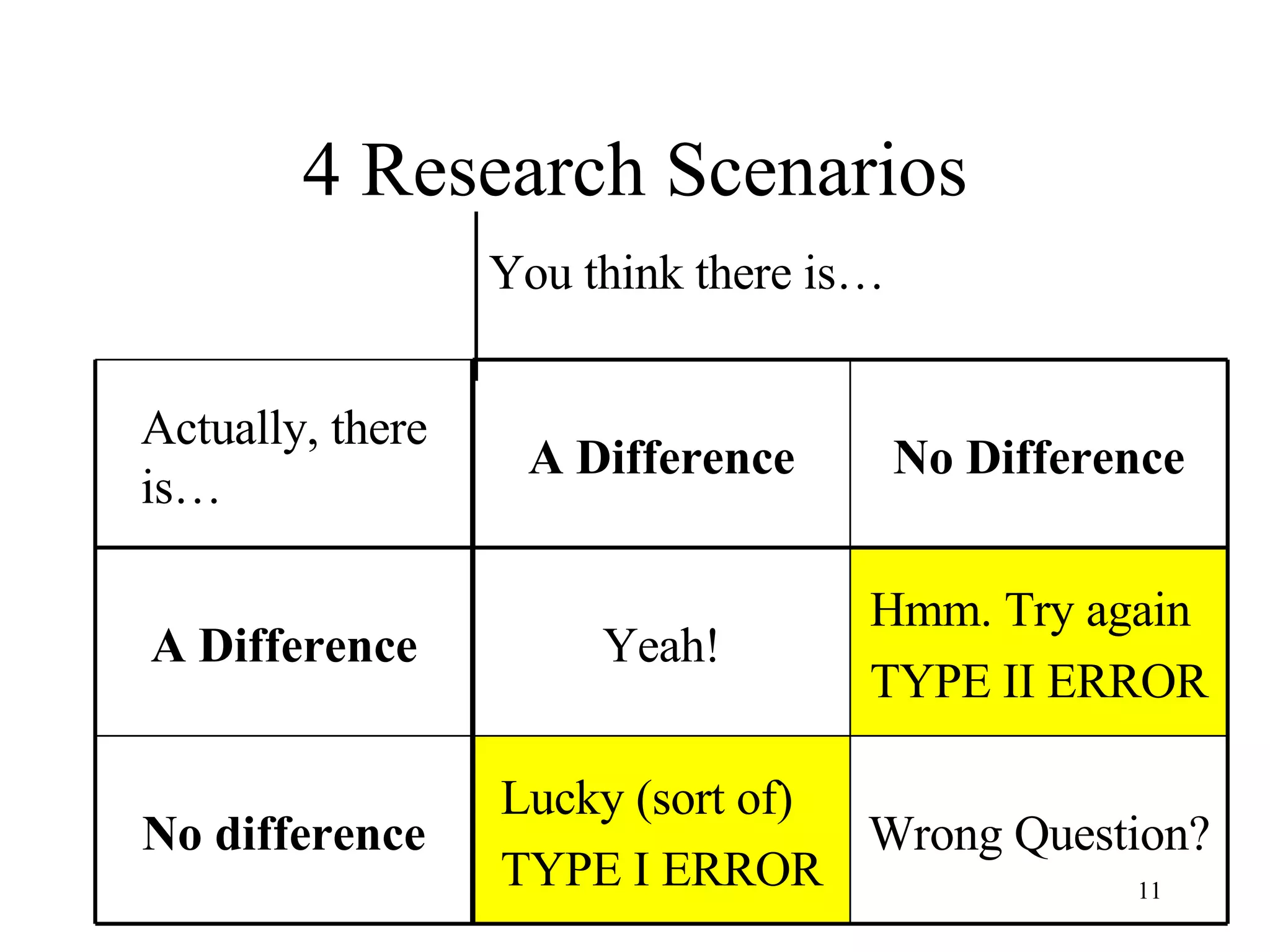
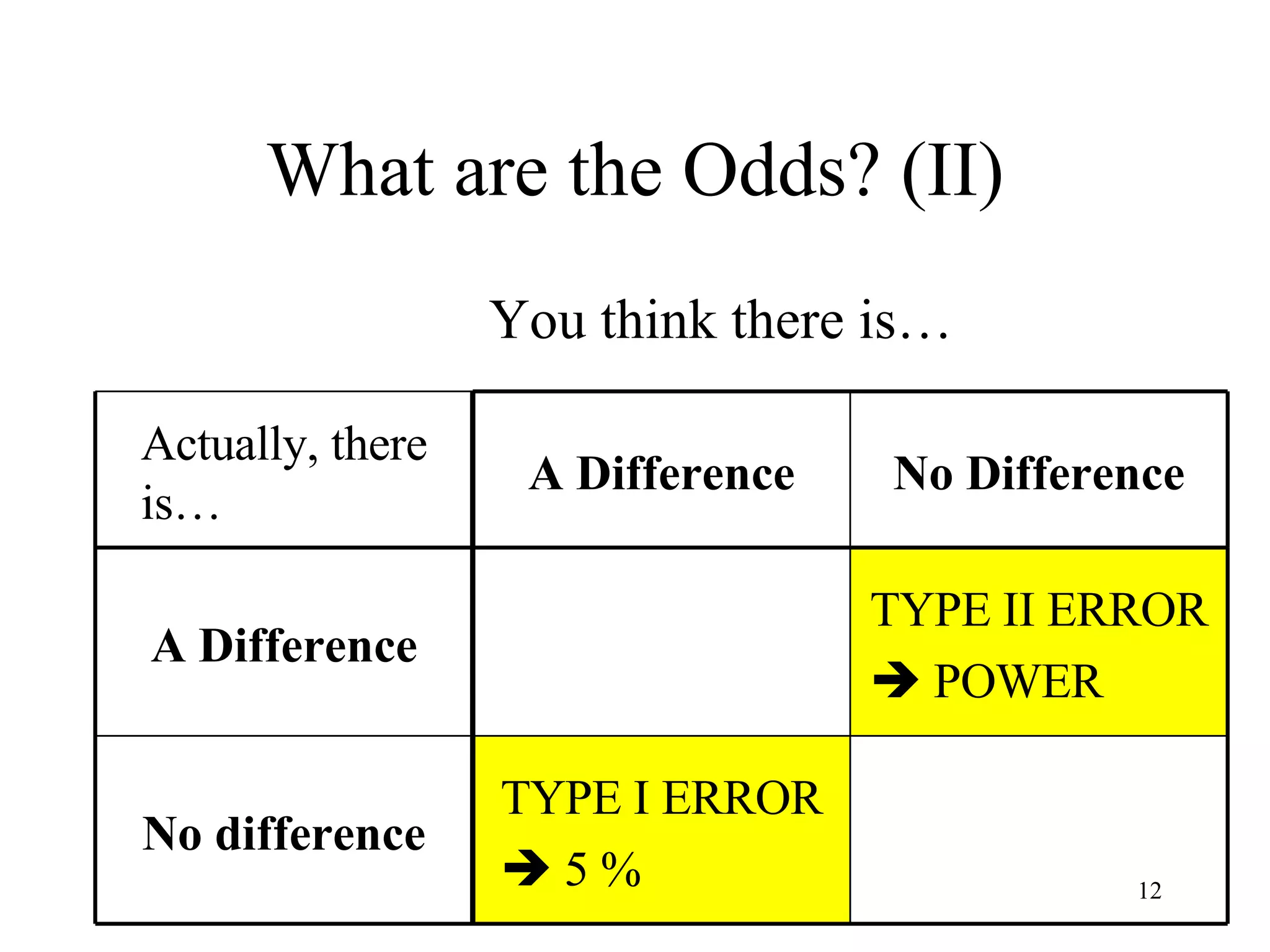
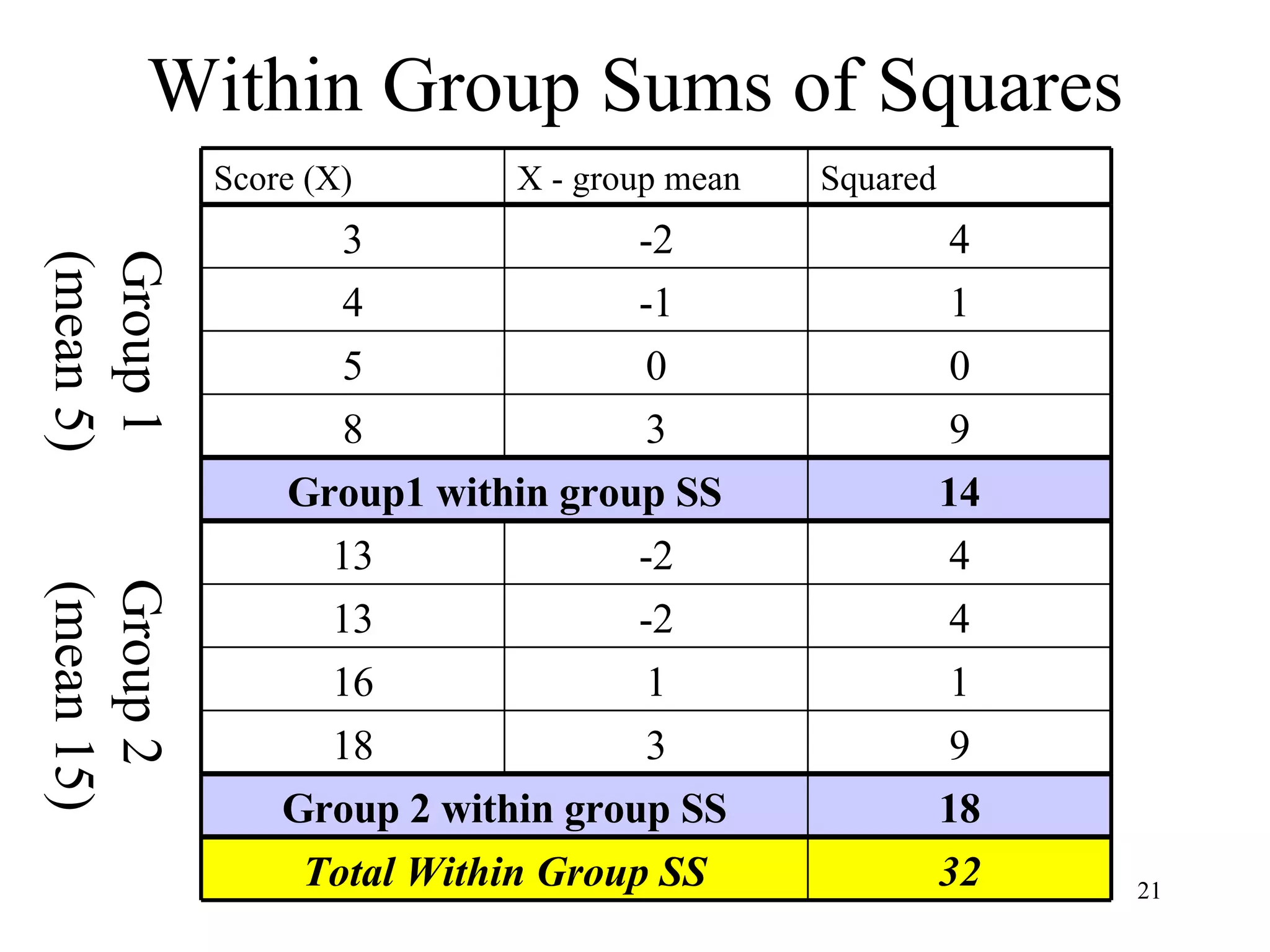
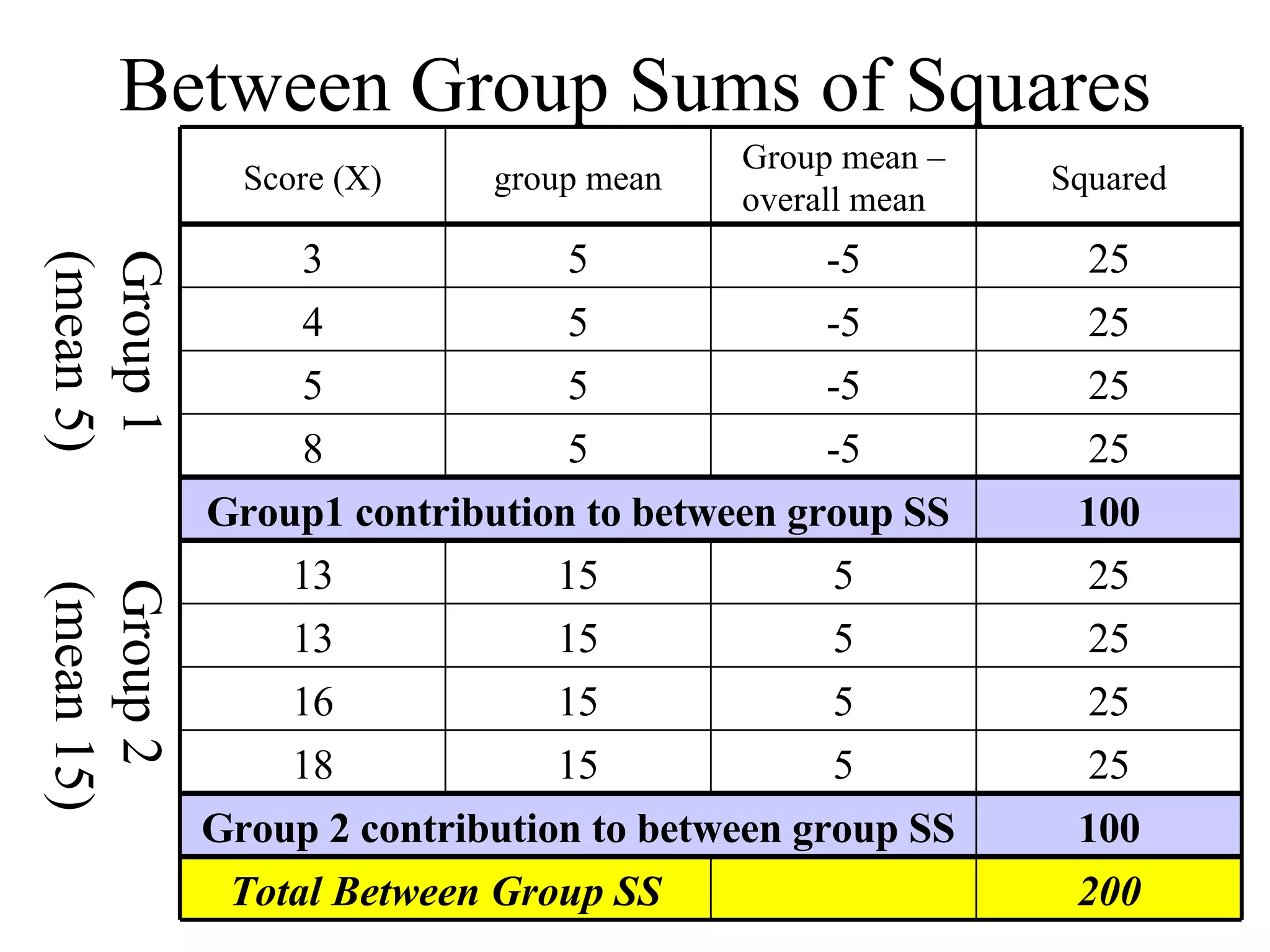
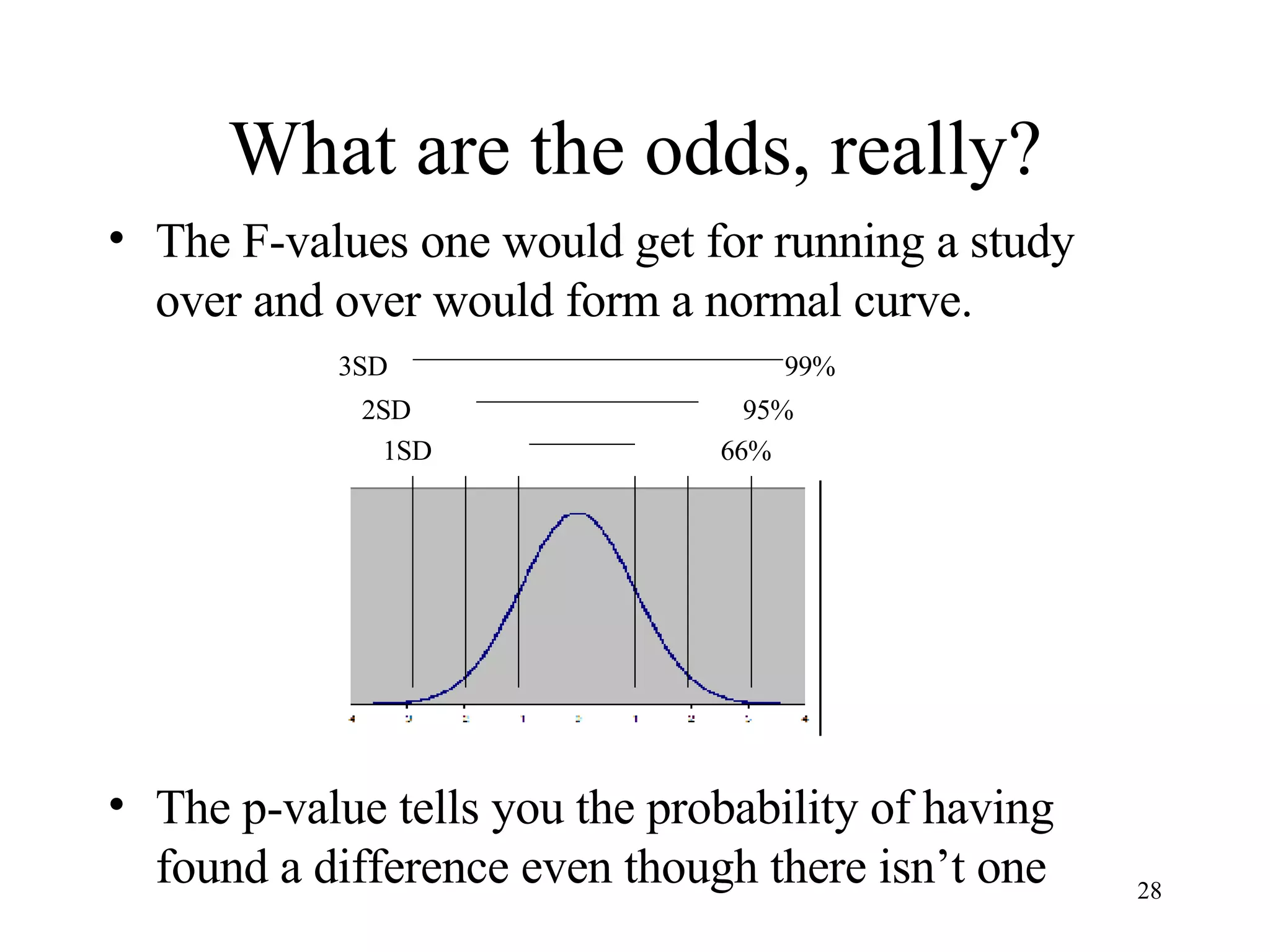
ANOVA (analysis of variance) is used to determine if different treatment groups differ significantly on some measure. It compares the variance between groups to the variance within groups. If the between-group variance is large relative to the within-group variance, it suggests the treatment had an effect. The analysis calculates an F-ratio, with larger values indicating it is less likely the groups differ due to chance. Researchers use statistical tables to determine the probability (p-value) that the F-ratio occurred by chance if there was actually no effect.



















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








