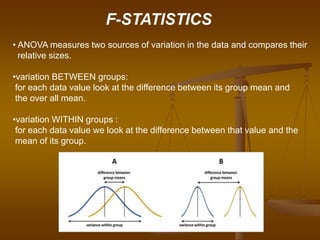
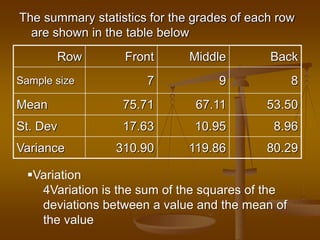
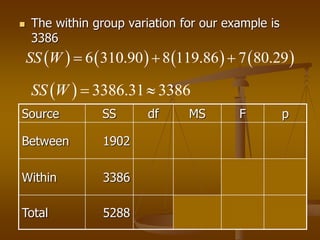
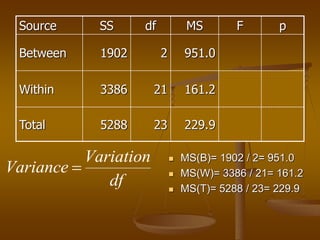
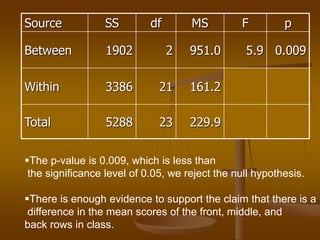
The document describes how analysis of variance (ANOVA) can be used to compare mean exam scores between students sitting in different rows (front, middle, back) of a classroom. ANOVA measures variation between and within groups. If the between-group variation is significantly greater than the within-group variation, then at least one group mean is different. The ANOVA calculation and assumptions are shown using example data. The results show the mean scores differed significantly between rows, rejecting the null hypothesis that all row means were equal.
![BRANCH :- FOOD PROCESSING AND TECHNOLOGY
in the
Subject of Food Standard and Quality Assurance[2171401]
On the
Topic of ANOVA model [how ANOVA work?] with example
Created by :
mahesh kapadiya 150010114020
Parth patel 130010114035](https://image.slidesharecdn.com/anovatest-191013143733/85/Anova-test-1-320.jpg)
![BRANCH :- FOOD PROCESSING AND TECHNOLOGY
in the
Subject of Food Standard and Quality Assurance[2171401]
On the
Topic of ANOVA model [how ANOVA work?] with example
Created by :
mahesh kapadiya 150010114020
Parth patel 130010114035](https://image.slidesharecdn.com/anovatest-191013143733/75/Anova-test-1-2048.jpg)