This document provides an overview and syllabus for CS 446: Machine Learning, taught by Gerald DeJong. Key details include:
- The course will use Mitchell's Machine Learning textbook
- Important dates: midterm on Oct 4, final on Dec 12
- Homework and projects will be submitted in class, with late penalties of 20% per day up to 3 days late
- Topics covered will include decision trees, linear threshold units, probabilistic representations, reinforcement learning, clustering, and more based on student interest
![CS 446: Machine Learning Gerald DeJong [email_address] 3-0491 3320 SC Recent approval for a TA to be named later](https://image.slidesharecdn.com/ppt301/85/ppt-1-320.jpg)


![Approx. Course Overview / Topics Introduction: Basic problems and questions A detailed examples: Linear threshold units Basic Paradigms: PAC (Risk Minimization); Bayesian Theory; SRM (Structural Risk Minimization); Compression; Maximum Entropy;… Generative/Discriminative; Classification/Skill;… Learning Protocols Online/Batch; Supervised/Unsupervised/Semi-supervised; Delayed supervision Algorithms: Decision Trees (C4.5) [Rules and ILP (Ripper, Foil)] Linear Threshold Units (Winnow, Perceptron; Boosting; SVMs; Kernels) Probabilistic Representations (naïve Bayes, Bayesian trees; density estimation) Delayed supervision: RL Unsupervised/Semi-supervised: EM Clustering, Dimensionality Reduction, or others of student interest](https://image.slidesharecdn.com/ppt301/85/ppt-4-320.jpg)

![What to Learn? Direct Learning: (discriminative, model-free[bad name]) Learn a function that maps an input instance to the sought after property. Model Learning: (indirect, generative) Learning a model of the domain; then use it to answer various questions about the domain In both cases, several protocols can be used – Supervised – learner is given examples and answers Unsupervised – examples, but no answers Semi-supervised – some examples w/answers, others w/o Delayed supervision](https://image.slidesharecdn.com/ppt301/85/ppt-6-320.jpg)

![Example and Hypothesis Spaces X H X: Example Space – set of all well-formed inputs [w/a distribution] H: Hypothesis Space – set of all well-formed outputs - - + + + - - - +](https://image.slidesharecdn.com/ppt301/85/ppt-8-320.jpg)









![Key Issues in Machine Learning Modeling How to formulate application problems as machine learning problems ? Learning Protocols (where is the data coming from, how?) Project examples: [complete products] EMAIL Given a seminar announcement, place the relevant information in my outlook Given a message, place it in the appropriate folder Image processing: Given a folder with pictures; automatically rotate all those that need it. My office: have my office greet me in the morning and unlock the door (but do it only for me!) Context Sensitive Spelling: Incorporate into Word](https://image.slidesharecdn.com/ppt301/85/ppt-18-320.jpg)


![Linear Discriminators I don’t know { whether, weather} to laugh or cry How can we make this a learning problem? We will look for a function F: Sentences { whether, weather} We need to define the domain of this function better. An option : For each word w in English define a Boolean feature x w : [x w =1] iff w is in the sentence This maps a sentence to a point in {0,1} 50,000 In this space: some points are whether points some are weather points Learning Protocol? Supervised? Unsupervised?](https://image.slidesharecdn.com/ppt301/85/ppt-22-320.jpg)





![A General Framework for Learning Goal: predict an unobserved output value y 2 Y based on an observed input vector x 2 X Estimate a functional relationship y~f(x) from a set {(x,y) i } i=1,n Most relevant - Classification : y {0,1} (or y {1,2,…k} ) (But, within the same framework can also talk about Regression, y 2 < What do we want f(x) to satisfy? We want to minimize the Loss (Risk): L(f()) = E X,Y ( [f(x) y] ) Where: E X,Y denotes the expectation with respect to the true distribution . Simply: # of mistakes […] is a indicator function](https://image.slidesharecdn.com/ppt301/85/ppt-28-320.jpg)
![A General Framework for Learning (II) We want to minimize the Loss: L(f()) = E X,Y ( [f(X) Y] ) Where: E X,Y denotes the expectation with respect to the true distribution . We cannot do that. Why not? Instead, we try to minimize the empirical classification error. For a set of training examples {(X i ,Y i )} i=1,n Try to minimize the observed loss (Issue I : when is this good enough? Not now) This minimization problem is typically NP hard. To alleviate this computational problem, minimize a new function – a convex upper bound of the classification error function I (f(x),y) =[f(x) y] = {1 when f(x) y; 0 otherwise}](https://image.slidesharecdn.com/ppt301/85/ppt-29-320.jpg)
















![Computational Issues Assume the data is linearly separable. Sample complexity: Suppose we want to ensure that our LTU has an error rate (on new examples) of less than with high probability(at least (1- )) How large must m (the number of examples) be in order to achieve this? It can be shown that for n dimensional problems m = O(1/ [ln(1/ ) + (n+1) ln(1/ ) ]. Computational complexity: What can be said? It can be shown that there exists a polynomial time algorithm for finding consistent LTU (by reduction from linear programming). (On-line algorithms have inverse quadratic dependence on the margin)](https://image.slidesharecdn.com/ppt301/85/ppt-46-320.jpg)


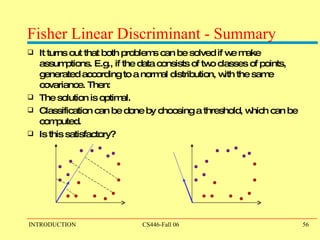
![Fisher Linear Discriminant This is a classical method for discriminant analysis. It is based on dimensionality reduction – finding a better representation for the data. Notice that just finding good representations for the data may not always be good for discrimination . [E.g., O, Q] Intuition: Consider projecting data from d dimensions to the line. Likely results in a mixed set of points and poor separation. However, by moving the line around we might be able to find an orientation for which the projected samples are well separated.](https://image.slidesharecdn.com/ppt301/85/ppt-49-320.jpg)