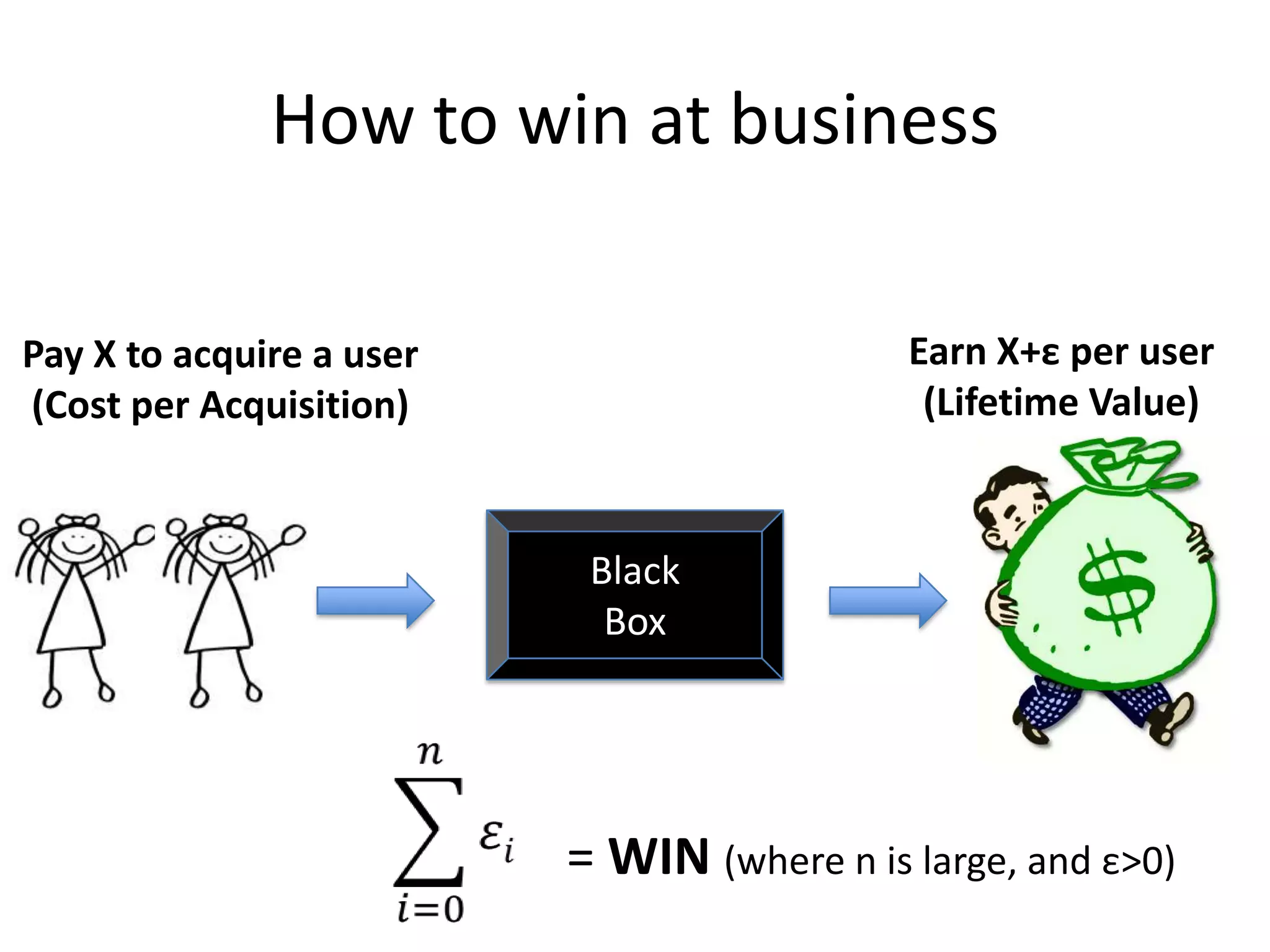





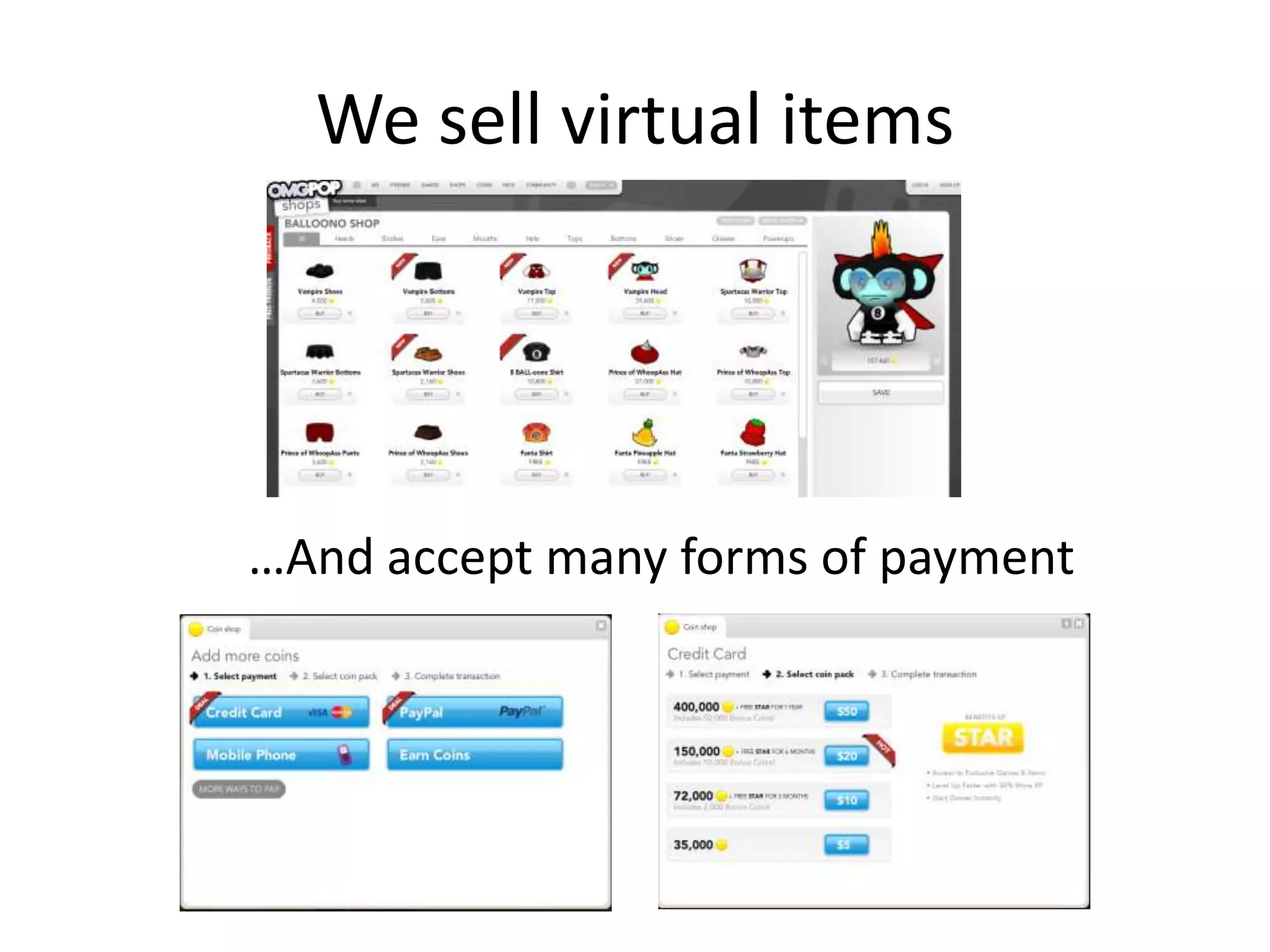









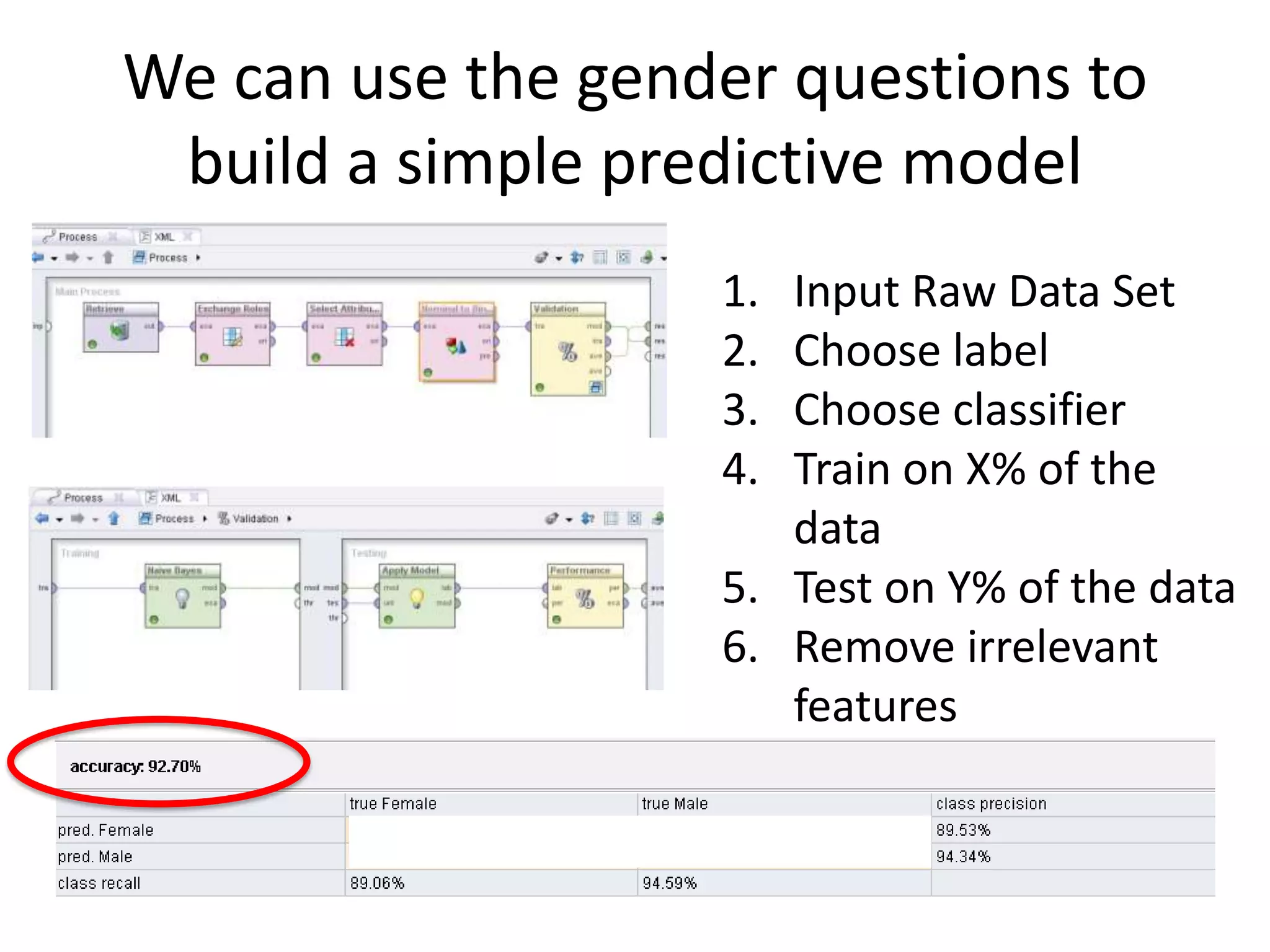
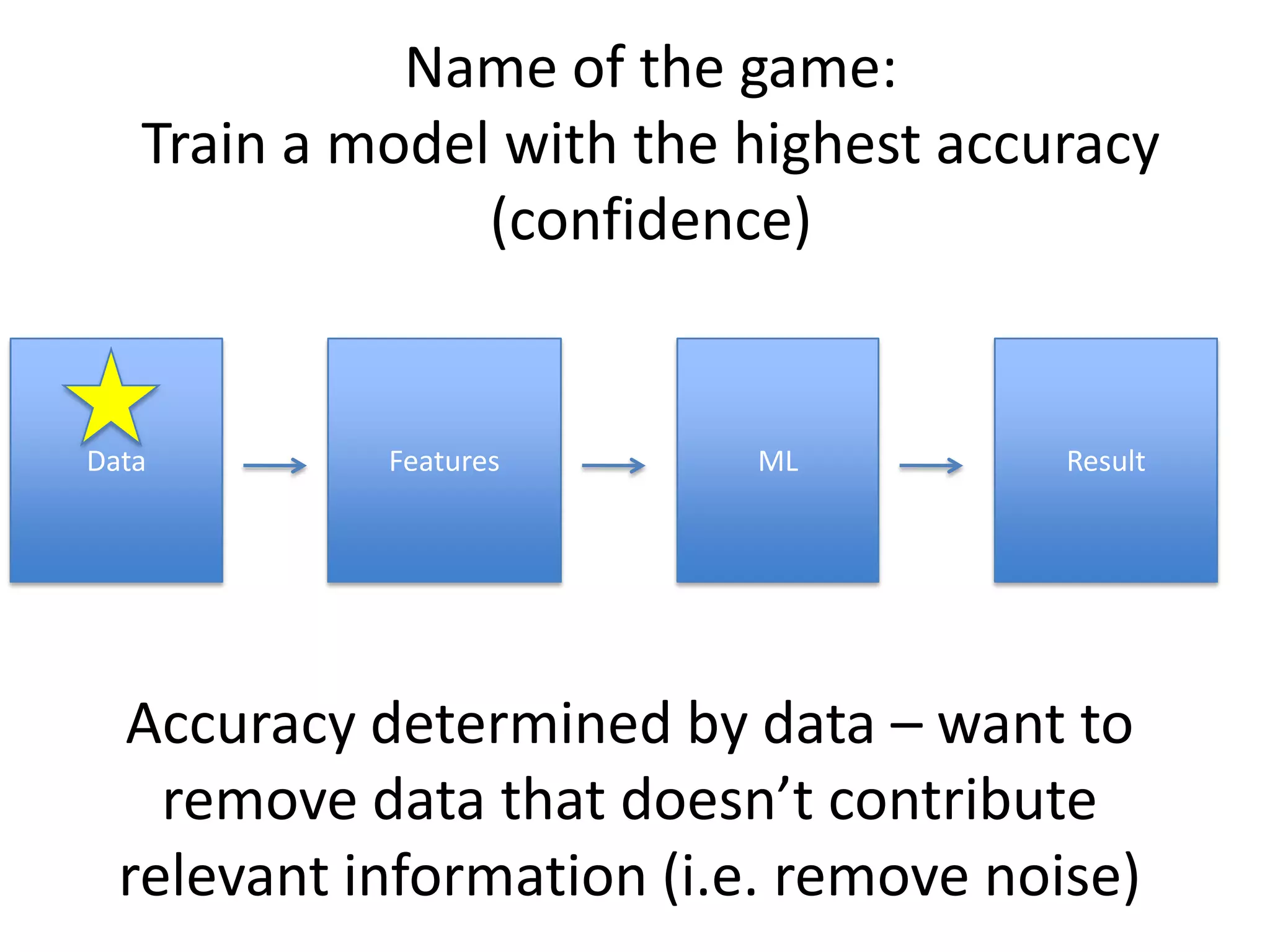


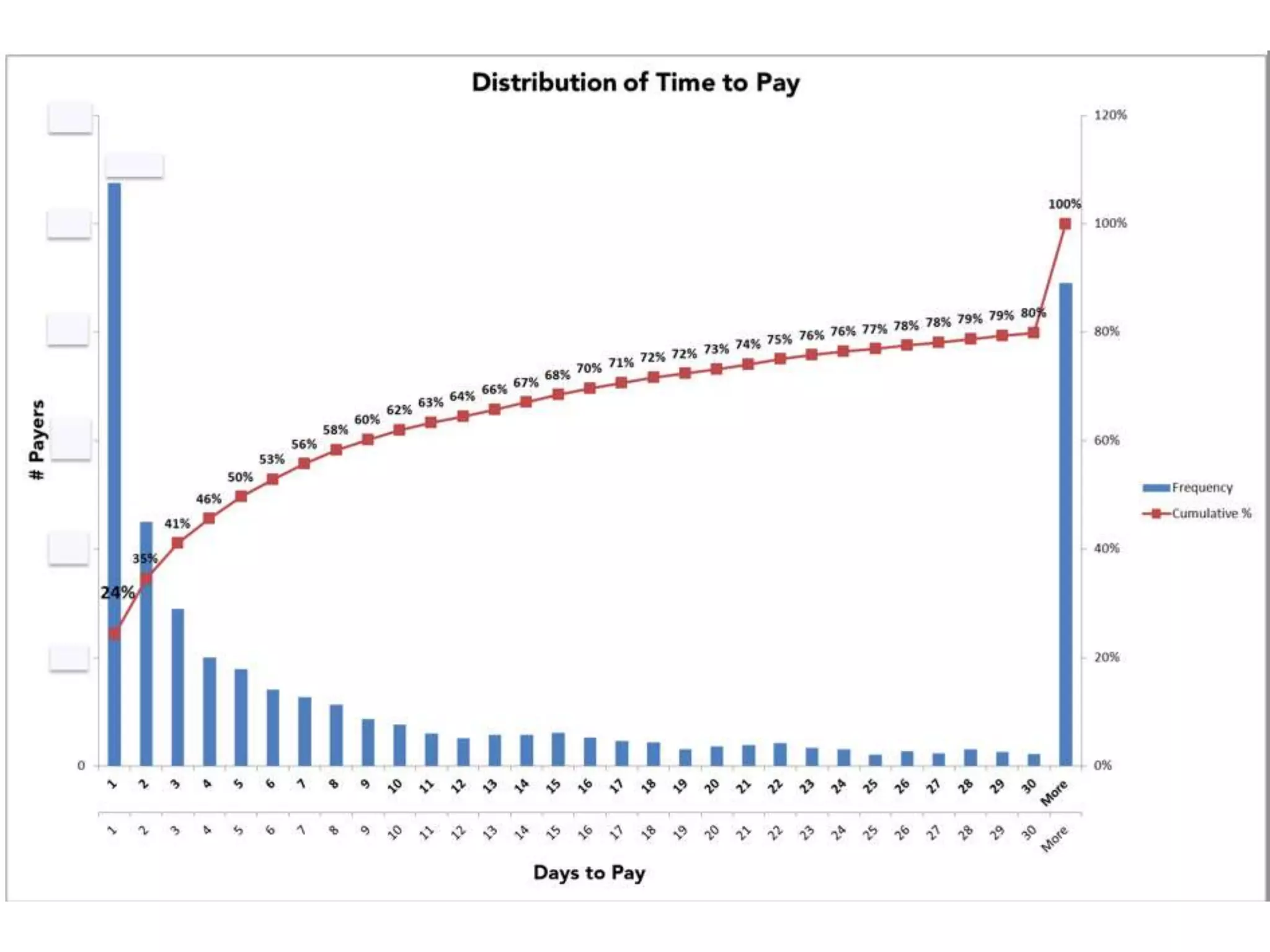
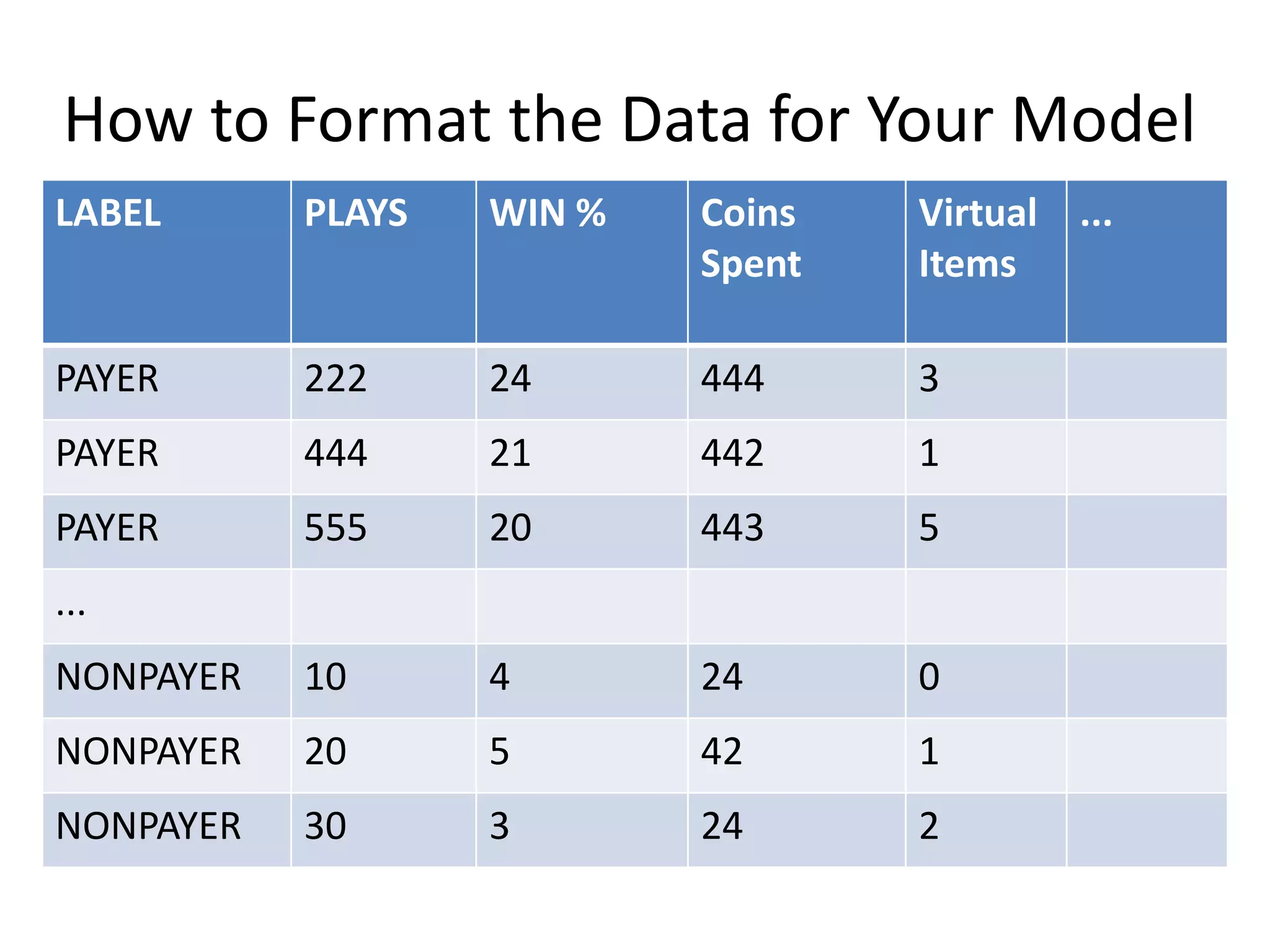
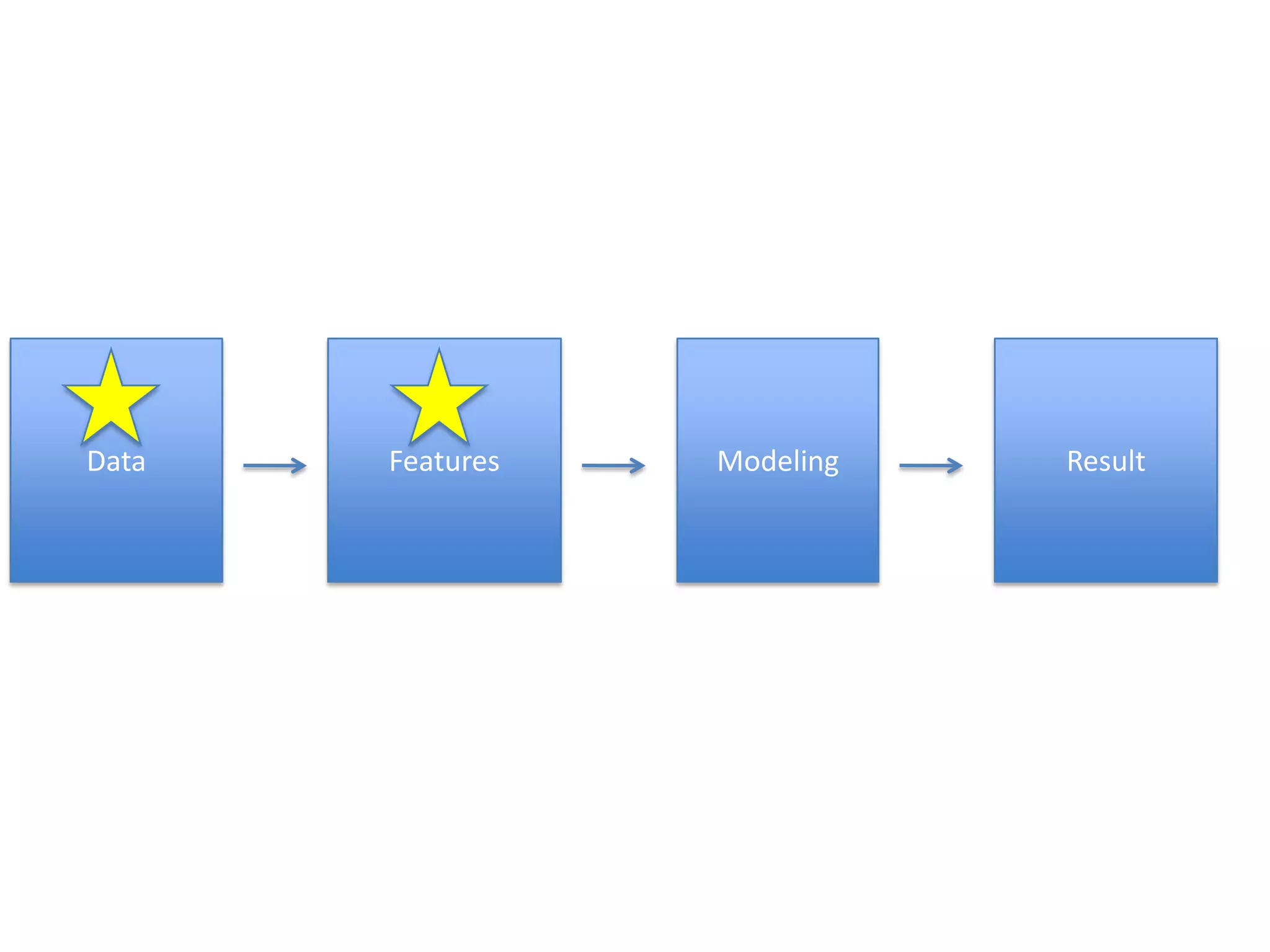

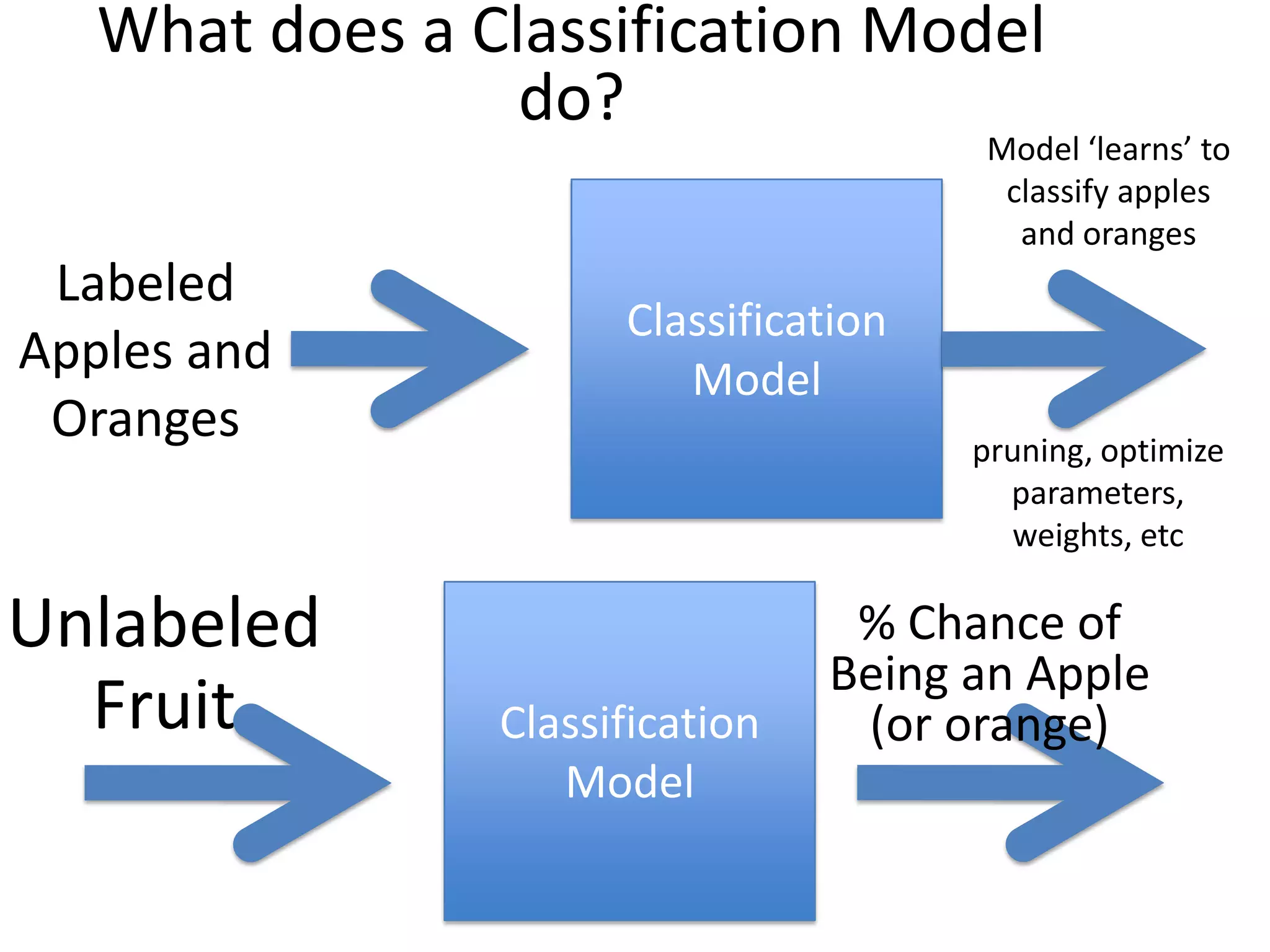

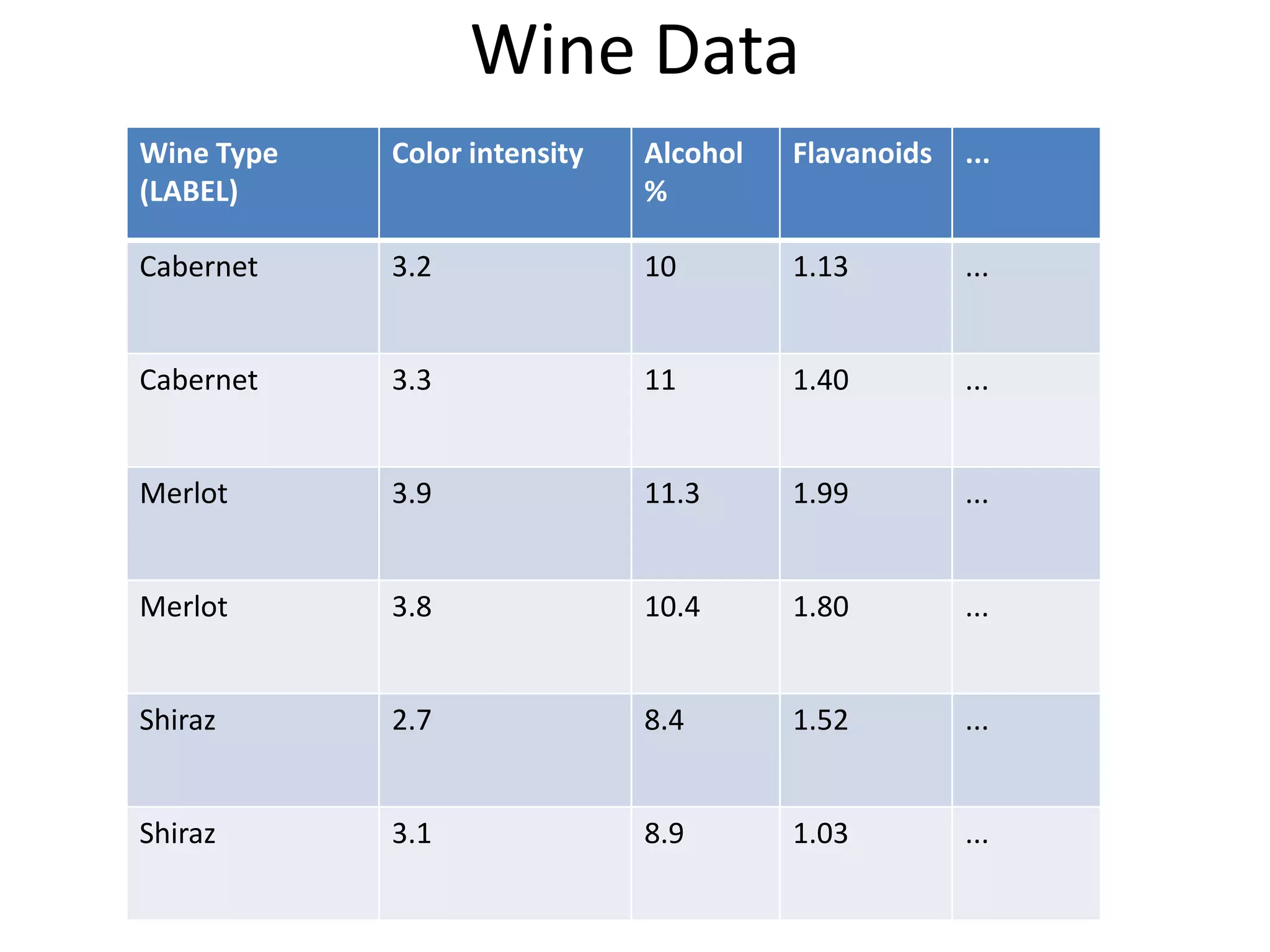
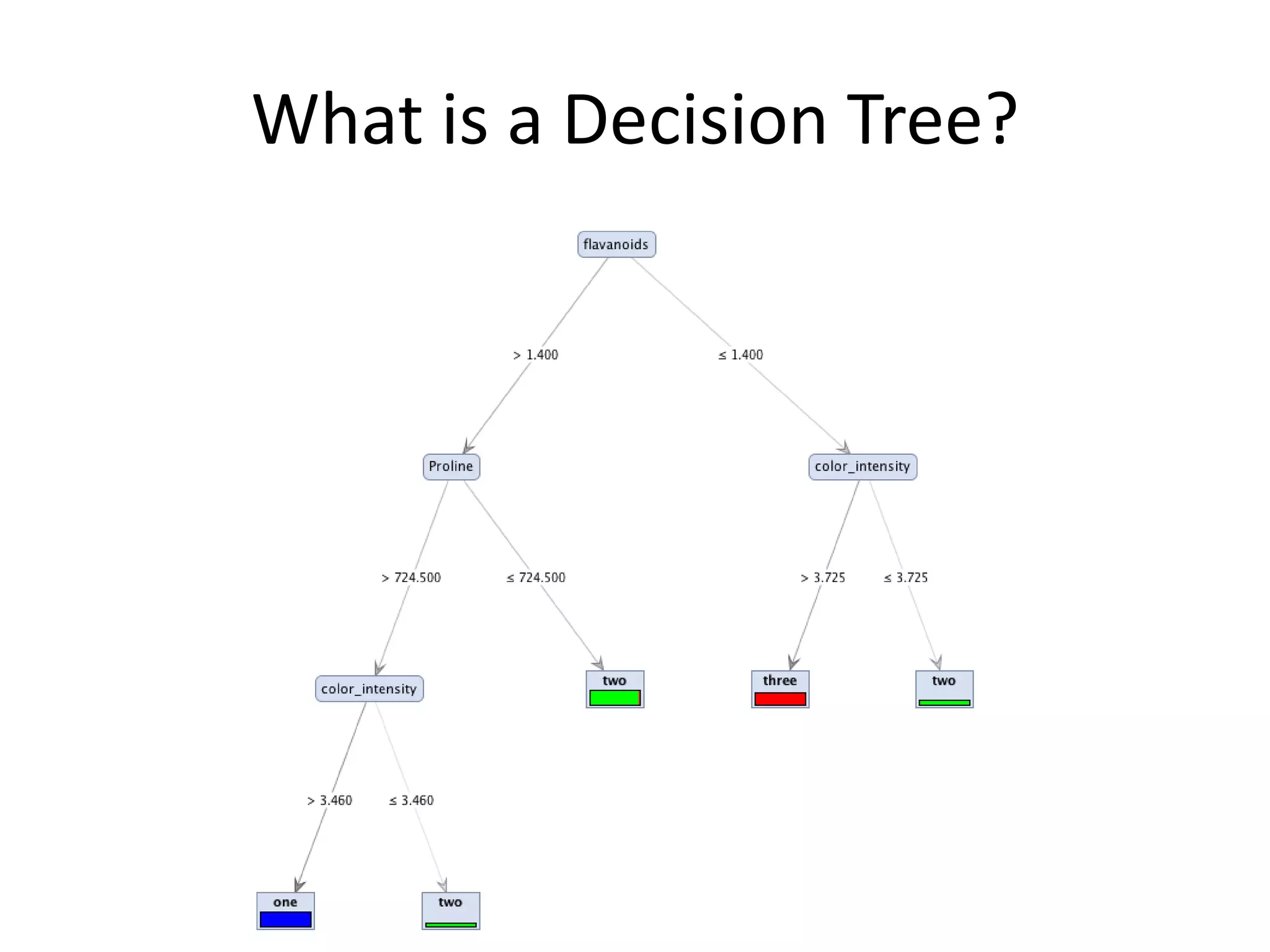
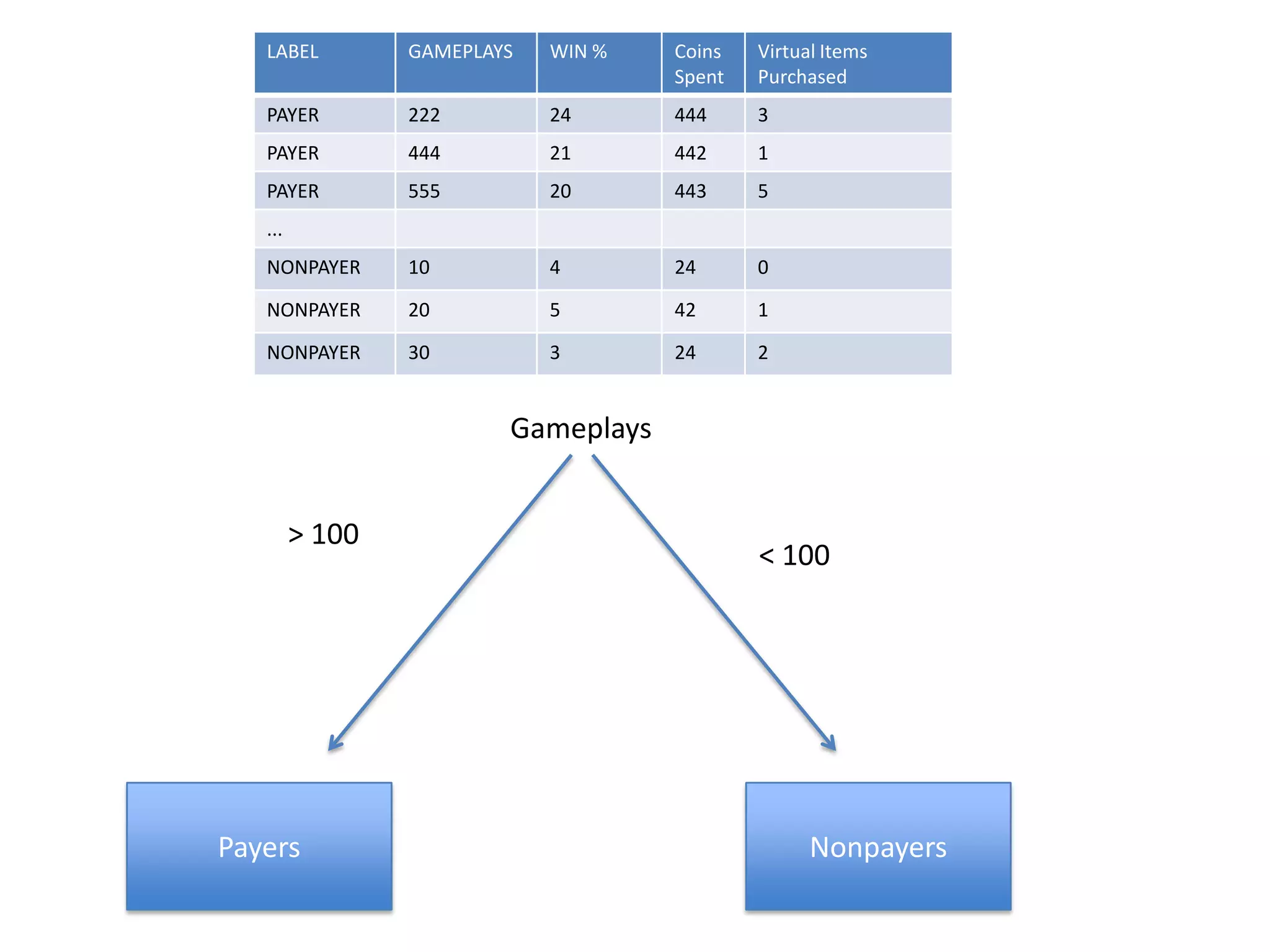



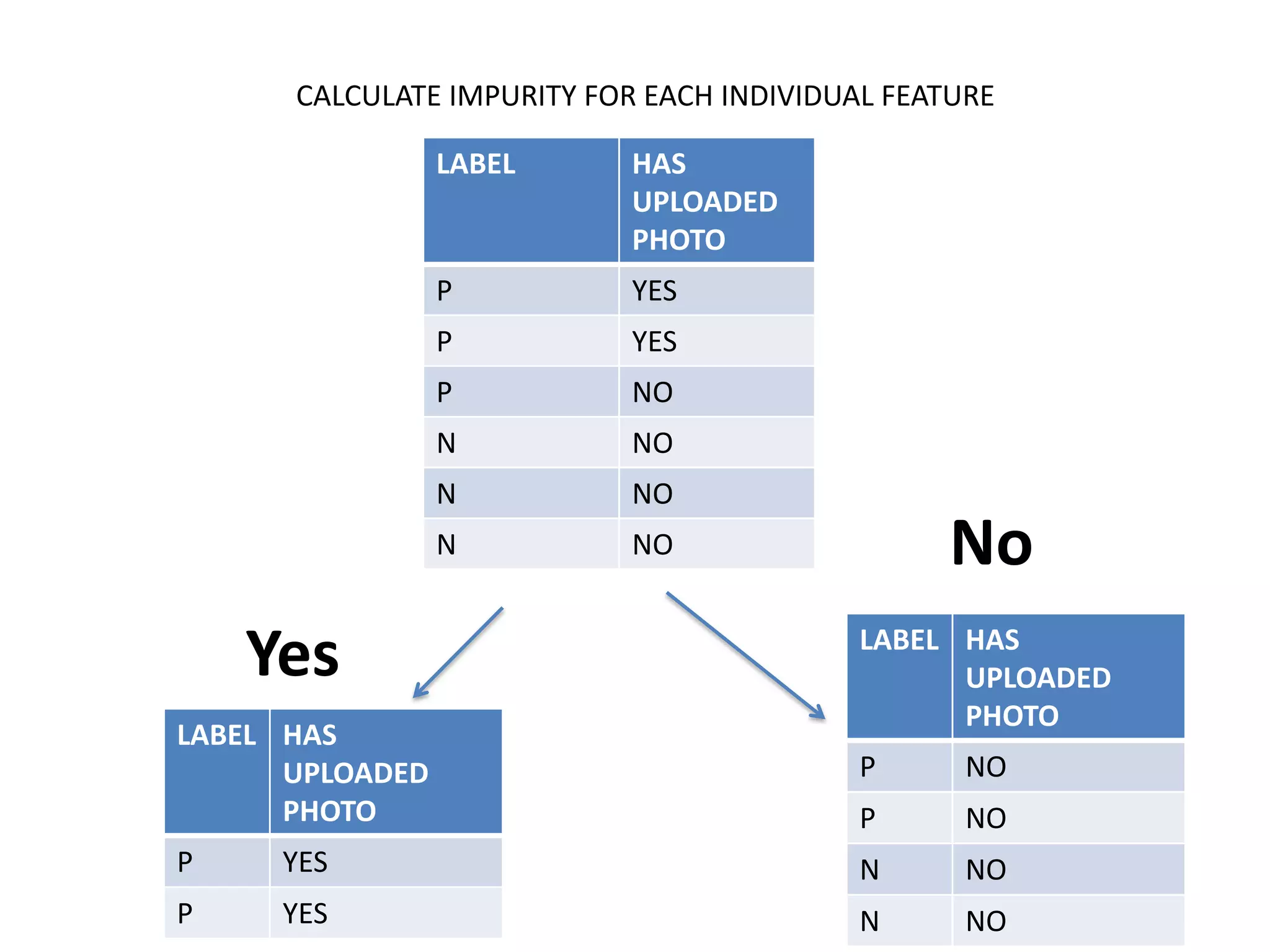

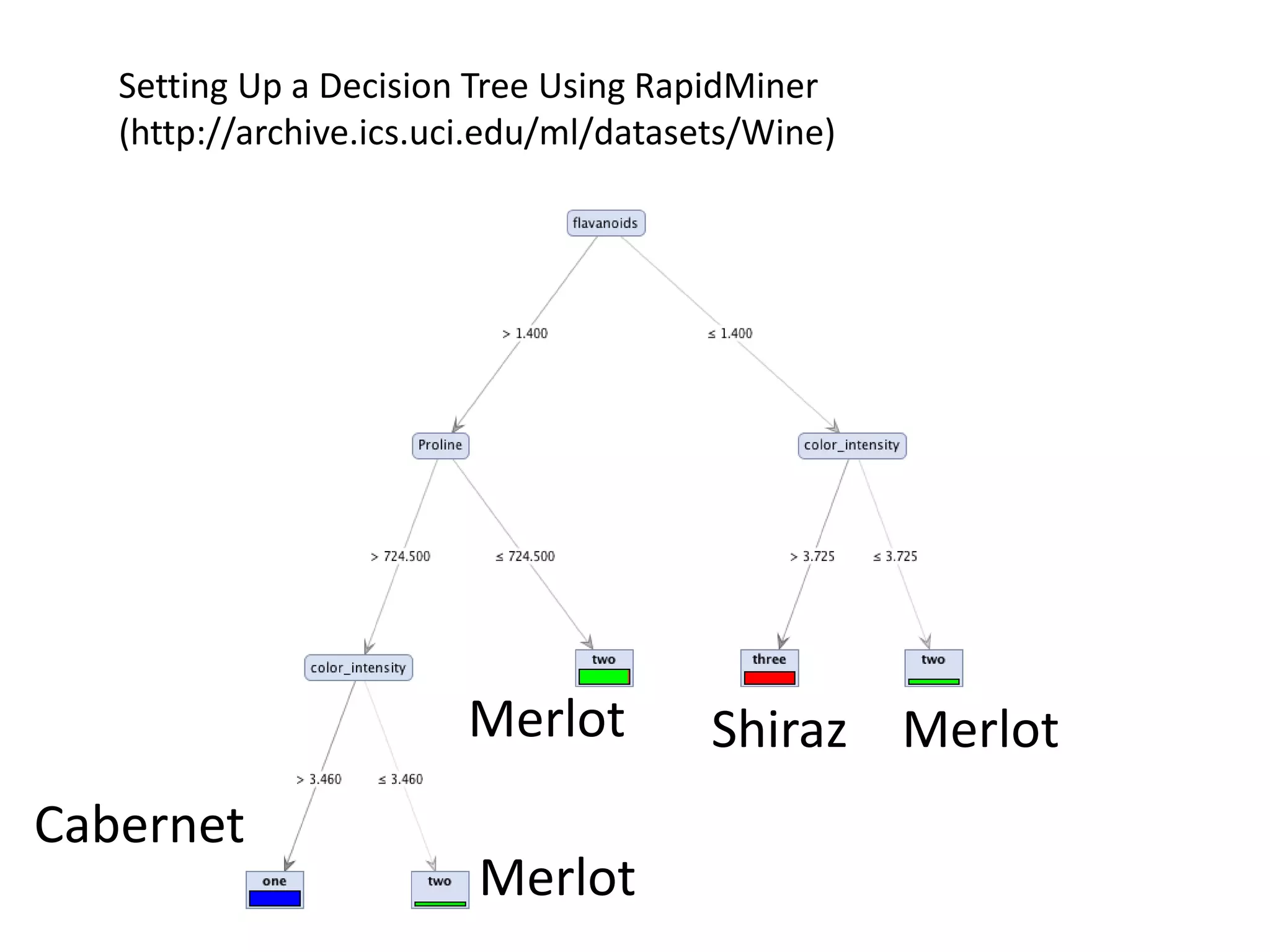













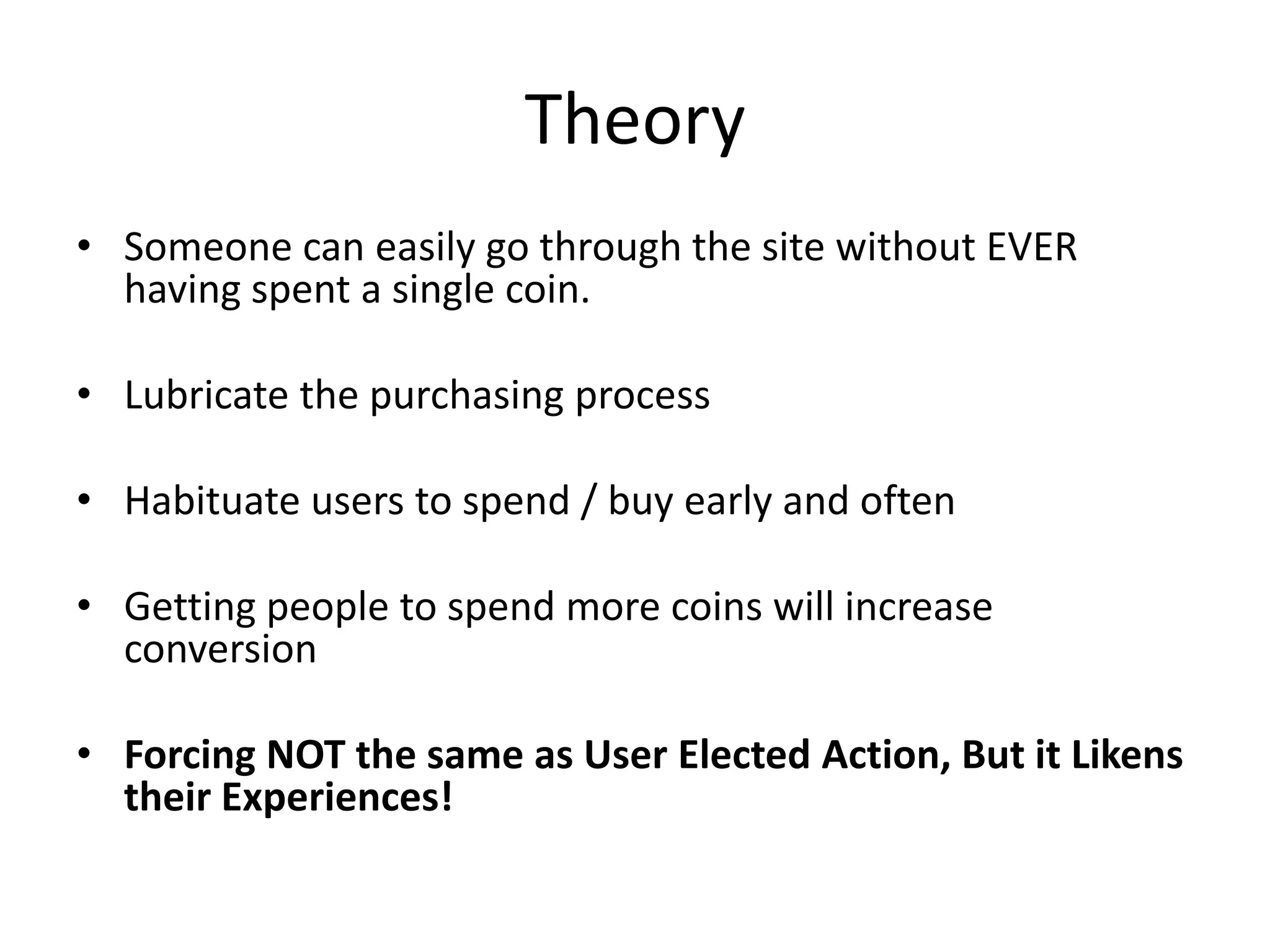




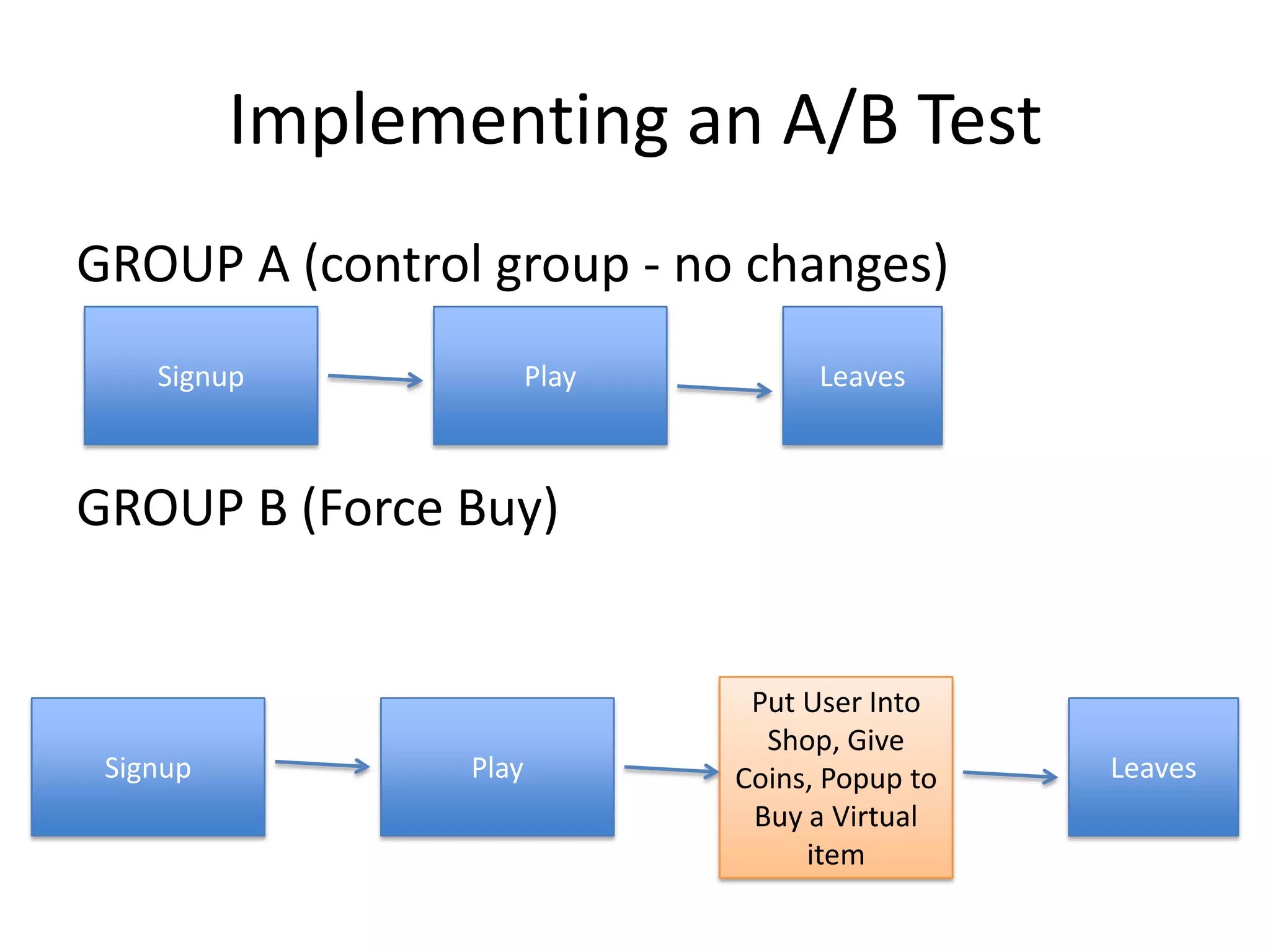




- The document discusses how to use predictive analytics and A/B testing to increase user conversion and revenue for a gaming startup. - By analyzing user data using decision trees, they found paying users had different experiences than non-paying users, spending more virtual currency on items. - They implemented an A/B test where new users in group B were forced to spend coins on virtual items initially to mimic paying users' experiences. - The success of this change would be measured by whether group B bought more virtual items and spent more coins, indicating aligning user experiences increased conversion.
















































