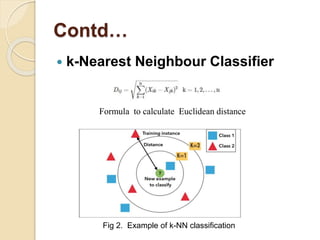
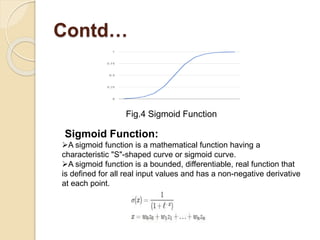
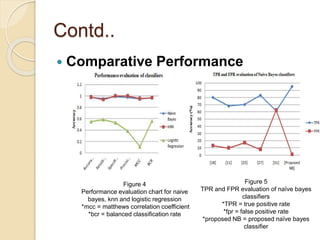
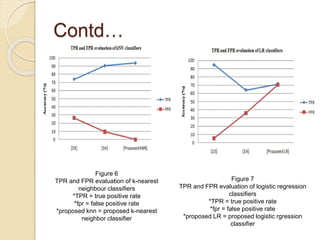
This document discusses credit card fraud detection using machine learning techniques. It compares the performance of naïve bayes, k-nearest neighbor, and logistic regression classifiers on a credit card transactions dataset. The dataset contains over 284,000 transactions with 0.172% fraudulent cases, making the data highly imbalanced. Different resampling techniques are used to address this imbalance. The performance of the classifiers is evaluated based on various metrics like accuracy, sensitivity, specificity, and F1 score. The results show that kNN performs best for most metrics except accuracy on a specific class distribution, while naïve bayes and logistic regression also achieve good performance.













































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








