Download as PDF, PPTX








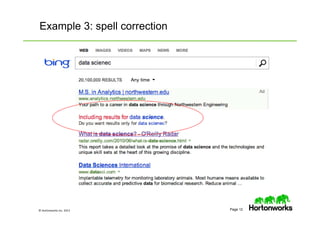


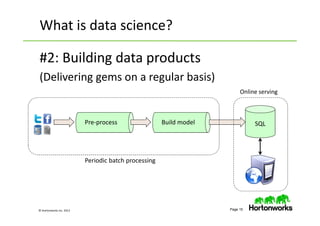
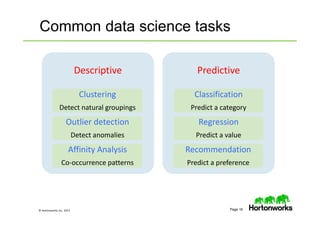

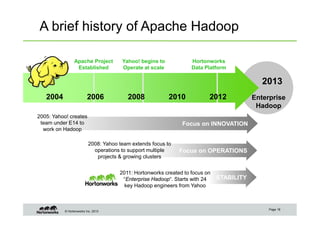
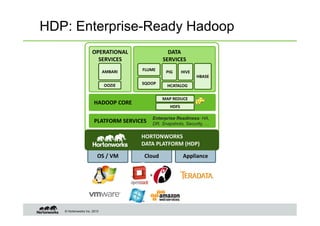


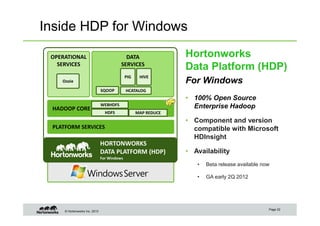
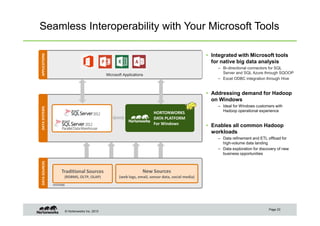



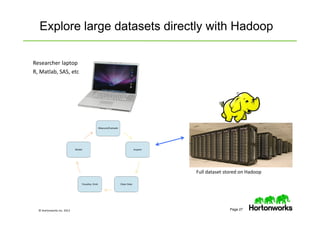




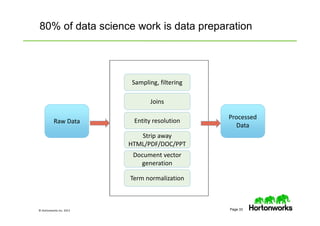

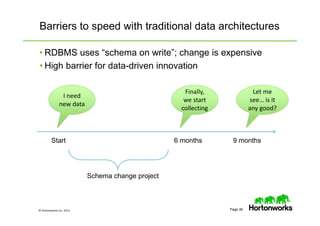
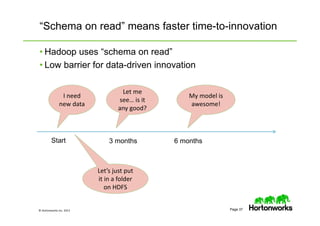




The document provides an overview of big data, data science, and the capabilities of Hadoop, focusing on its importance in handling large datasets and performing advanced analytics. It discusses the evolution of Hadoop, its architecture, and the benefits of using it for data preparation and innovation. Additionally, it introduces the Hortonworks Data Platform and opportunities for learning about Hadoop through training and events.


































































































