Downloaded 63 times


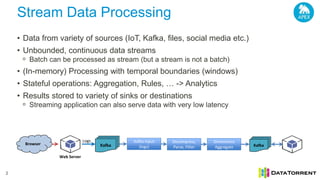

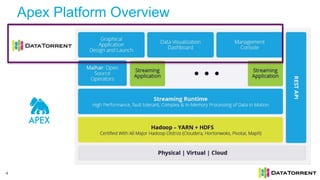
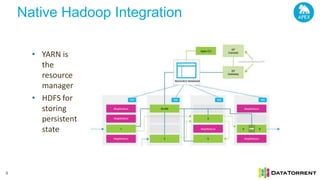
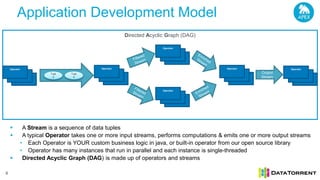
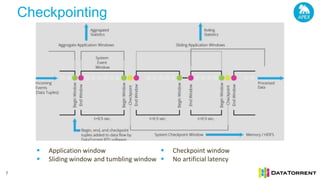
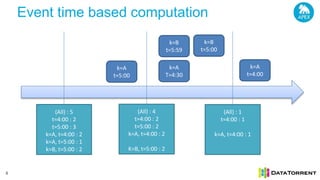
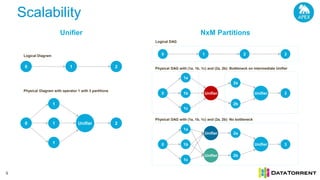
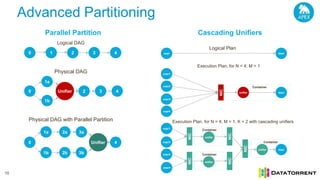
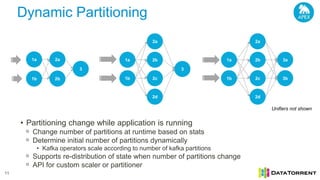

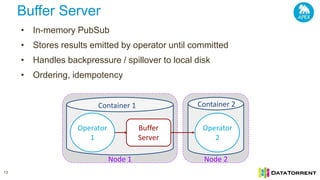








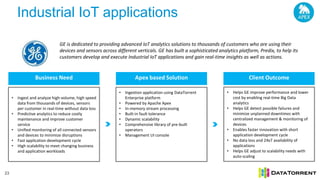
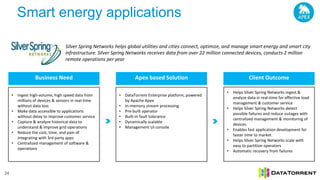



The document discusses next-generation big data analytics using Apache Apex, emphasizing in-memory stream processing and real-time data management from various sources. It highlights features such as scalability, fault tolerance, and dynamic resource allocation while detailing the application development model and operator framework. Additionally, it showcases case studies from companies like PubMatic and GE that benefit from real-time insights to enhance operational efficiency and revenue performance.



































































































