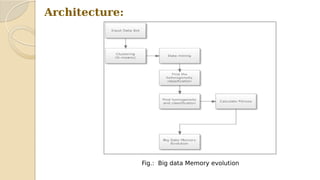
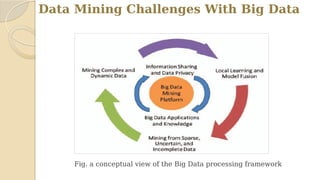
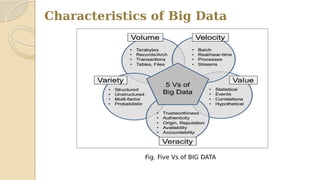
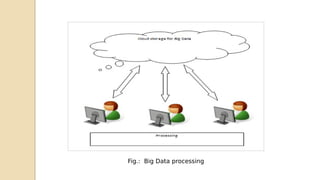
This document discusses data mining with big data. It begins with an agenda that covers problem definition, objectives, literature review, algorithms, existing systems, advantages, disadvantages, big data characteristics, challenges, tools, and applications. It then goes on to define the problem, objectives, provide a literature review summarizing several papers, and describe the architecture, algorithms, existing systems, HACE theorem that models big data characteristics, advantages of the proposed system, challenges, and characteristics of big data. It concludes that formalizing big data analysis processes will be important as data volumes continue increasing.