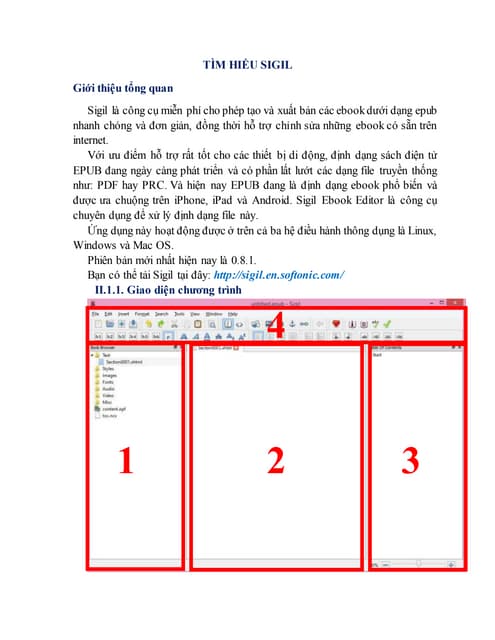
Download as PDF, PPTX




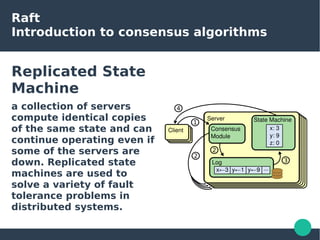





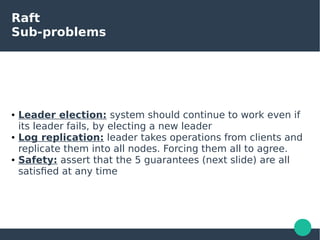

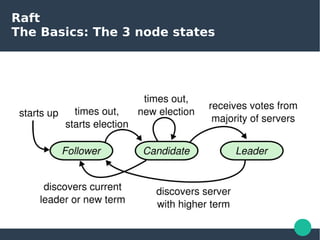
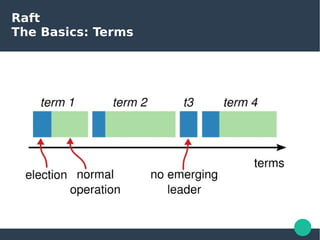
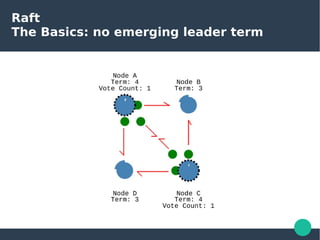


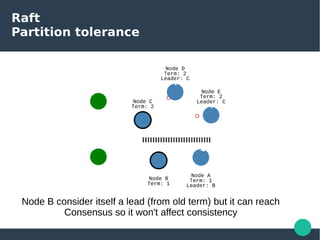


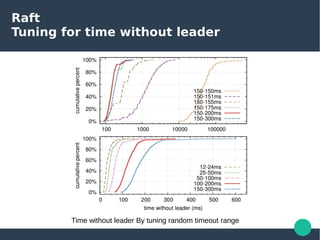
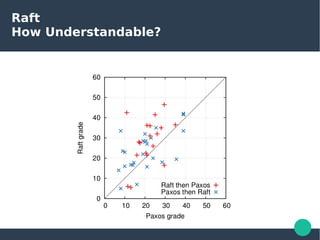


The document presents the Raft consensus algorithm, emphasizing its usability and structural differences from Paxos, aiming to provide an understandable solution for managing replicated logs in distributed systems. It discusses Raft’s unique features, including strong leadership, efficient leader election, and fault tolerance, along with its key properties and guarantees ensuring safety and consistency during consensus operations. The seminar showcases the relevance of Raft in real-world implementations, highlighting its application in distributed systems like Kubernetes and etcd.

























































![[Yu cheng lin]cloud presentation - Raft](https://cdn.slidesharecdn.com/ss_thumbnails/yu-chenglincloudpresentation-raft-170817043111-thumbnail.jpg?width=640&height=640&fit=bounds)


![Distributed Consensus: Making Impossible Possible [Revised]](https://cdn.slidesharecdn.com/ss_thumbnails/impossibleconsensus-161020212626-thumbnail.jpg?width=640&height=640&fit=bounds)

























