






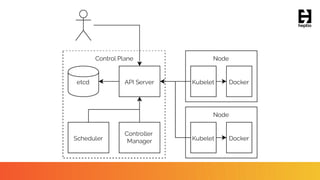

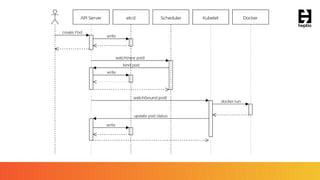










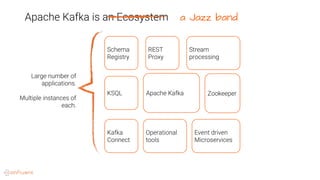
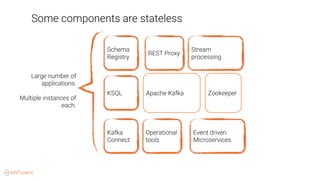
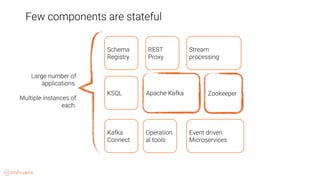






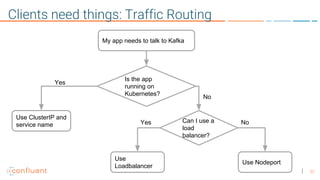
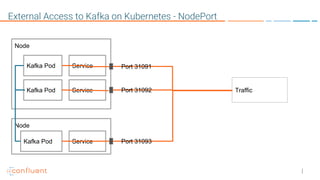
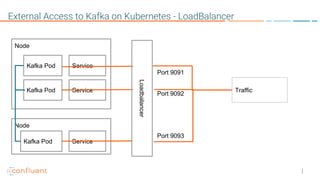
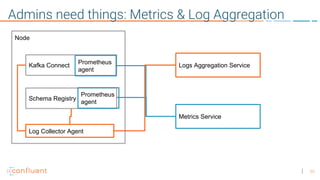










This document provides an overview of a webinar on Kubernetes operators presented by Joe Beda. It discusses: - Kubernetes allows for developer and operator productivity through improved workflows and better resource efficiency. - Operators are domain-specific controllers that manage both a software application and related Kubernetes objects, and help automate common operational tasks through code. - The Kafka operator example shows how an operator can handle tasks like identity, discovery, storage and logging/metrics for Kafka deployments on Kubernetes through a custom resource definition.












































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










