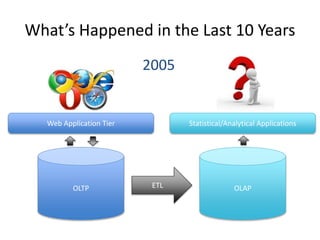
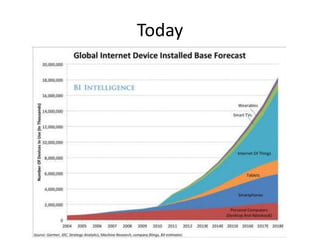
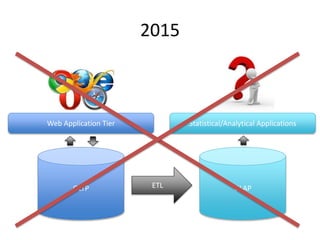
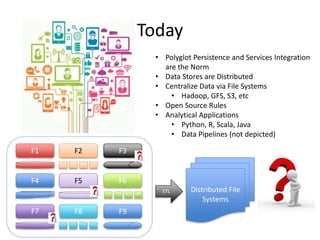
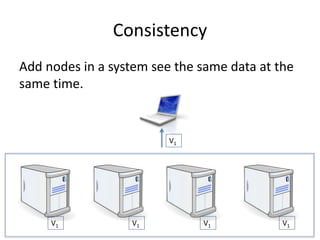
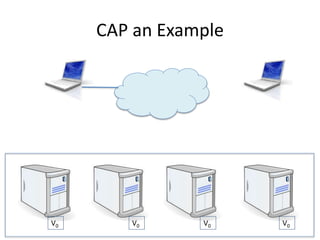
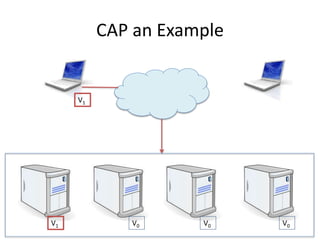
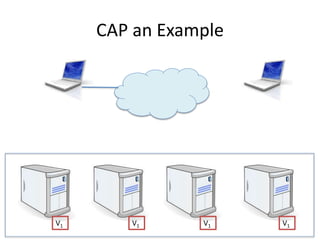
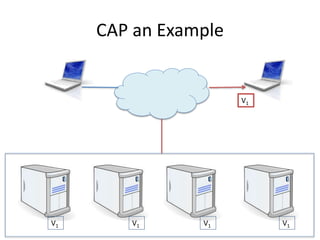
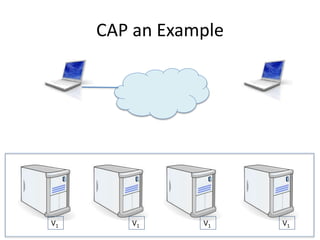
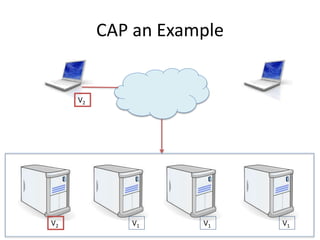
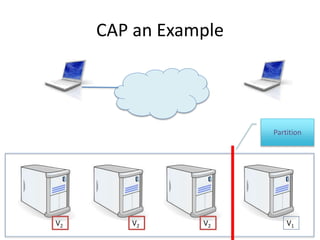
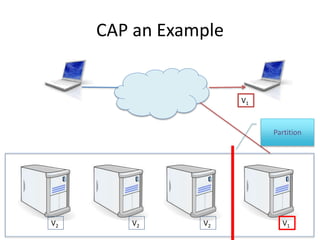
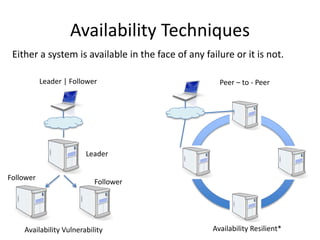
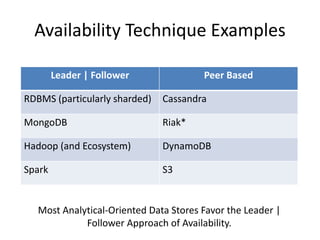
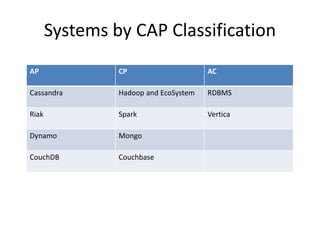
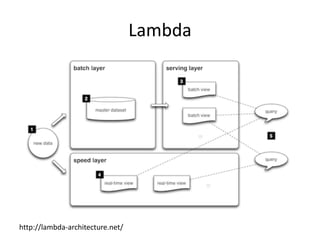
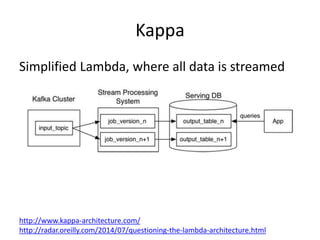
The document provides an overview of data engineering concepts for data scientists. It discusses the CAP theorem, which states that a distributed system cannot simultaneously provide consistency, availability, and partition tolerance. It describes various data store types and architectures that provide different balances of these properties, such as leader-follower systems that prioritize availability and consistency over partition tolerance. The document also summarizes reference architectures like Lambda and Kappa and discusses the concept of a data lake.