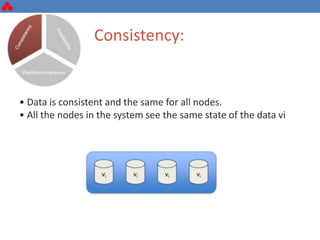
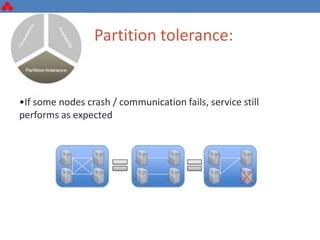
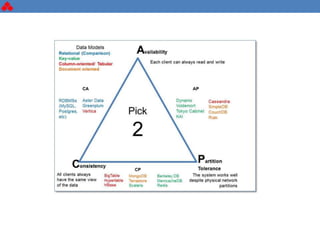
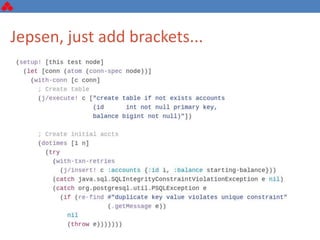
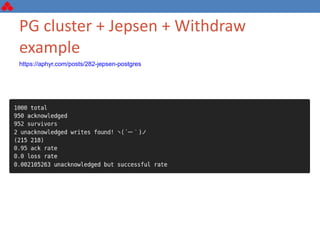
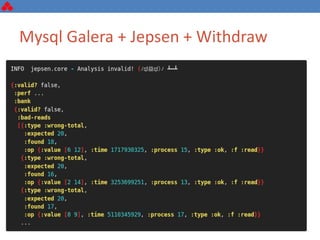
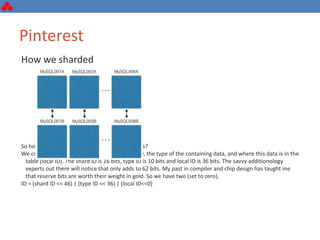
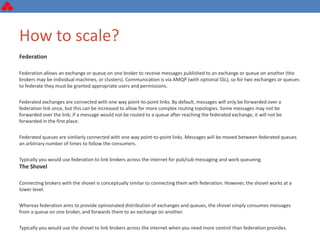
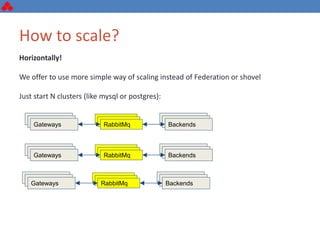
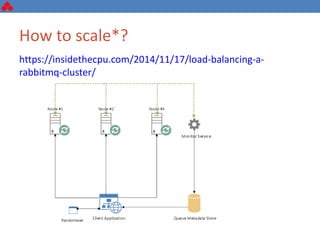
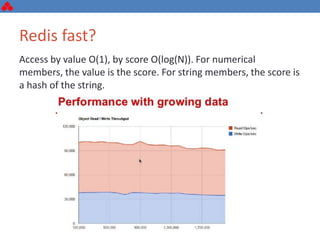
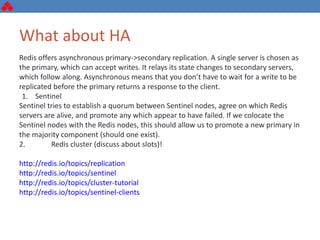
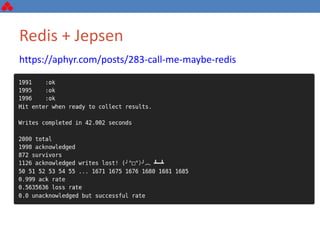
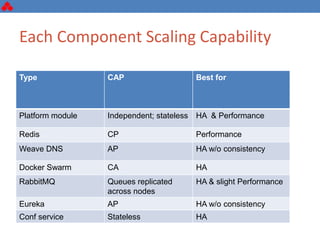
The document discusses some key challenges with achieving high availability and scalability in distributed systems based on the CAP theorem. It explains that consistency, availability, and partition tolerance cannot all be guaranteed simultaneously. It then provides examples of how this manifests in real database systems like MySQL, PostgreSQL, Redis, and RabbitMQ. It discusses strategies for improving availability and scalability in systems like PostgreSQL clusters and MySQL Galera clusters, but also limitations and complexity involved.