Download as PDF, PPTX










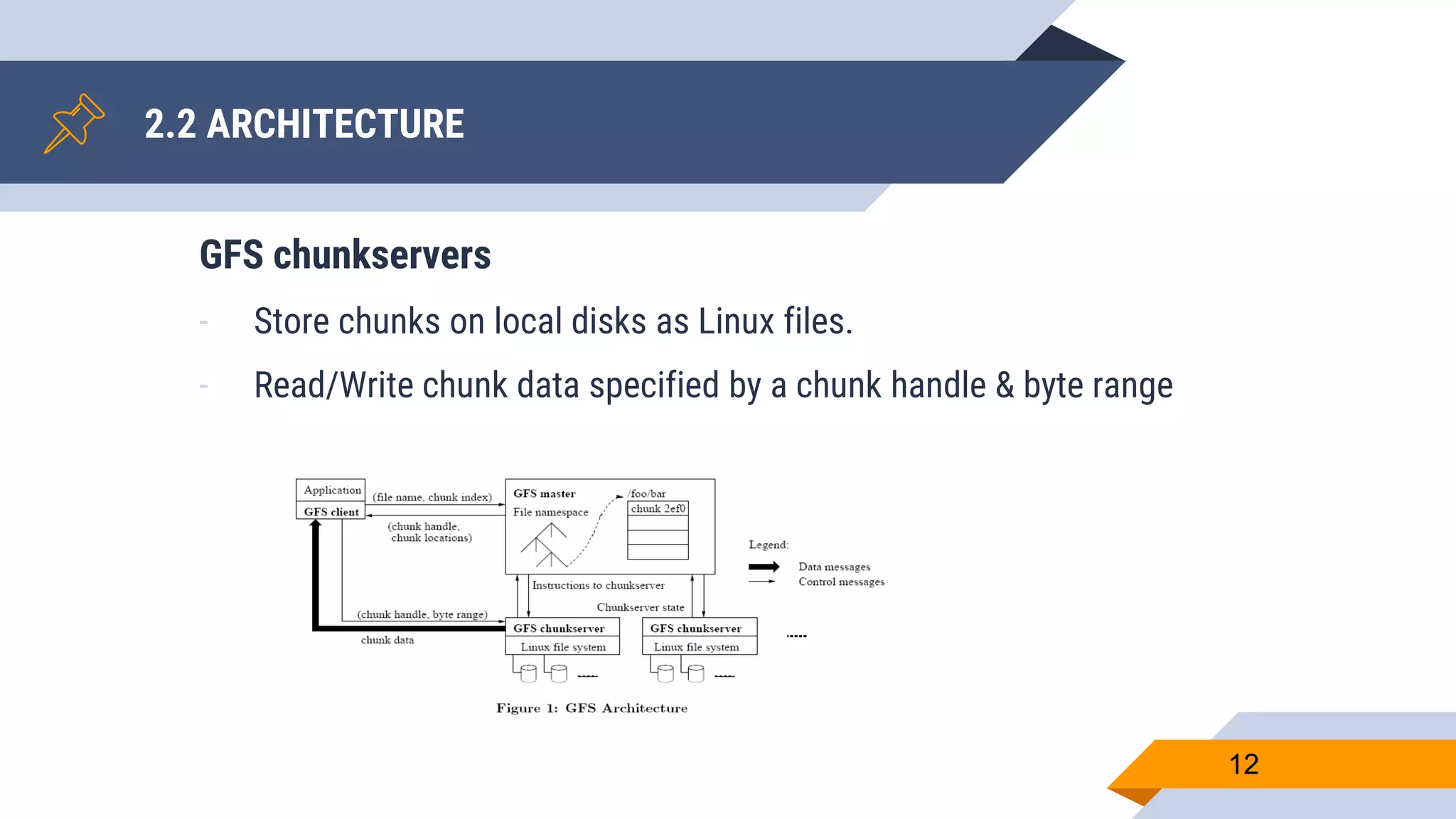

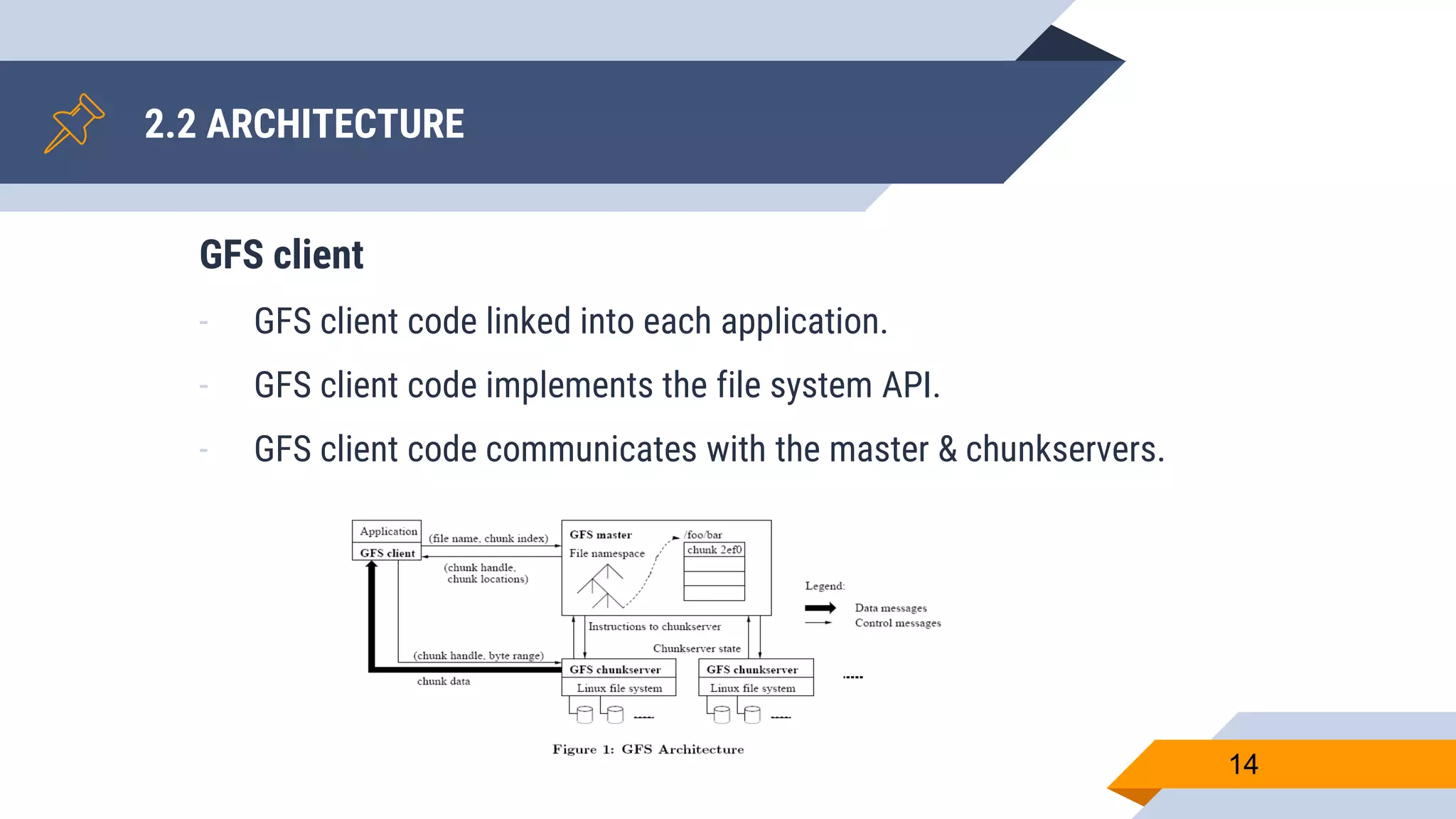





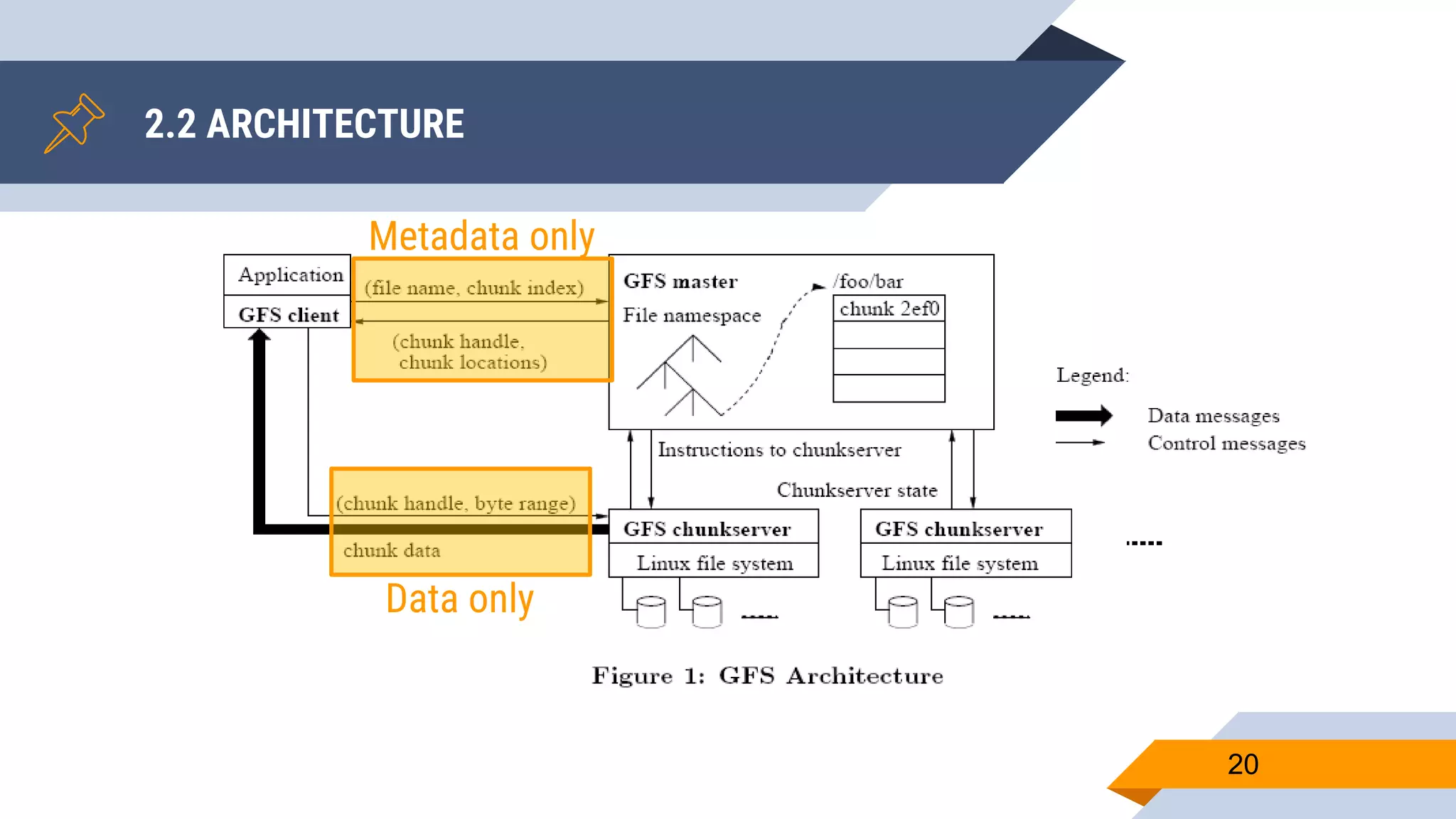
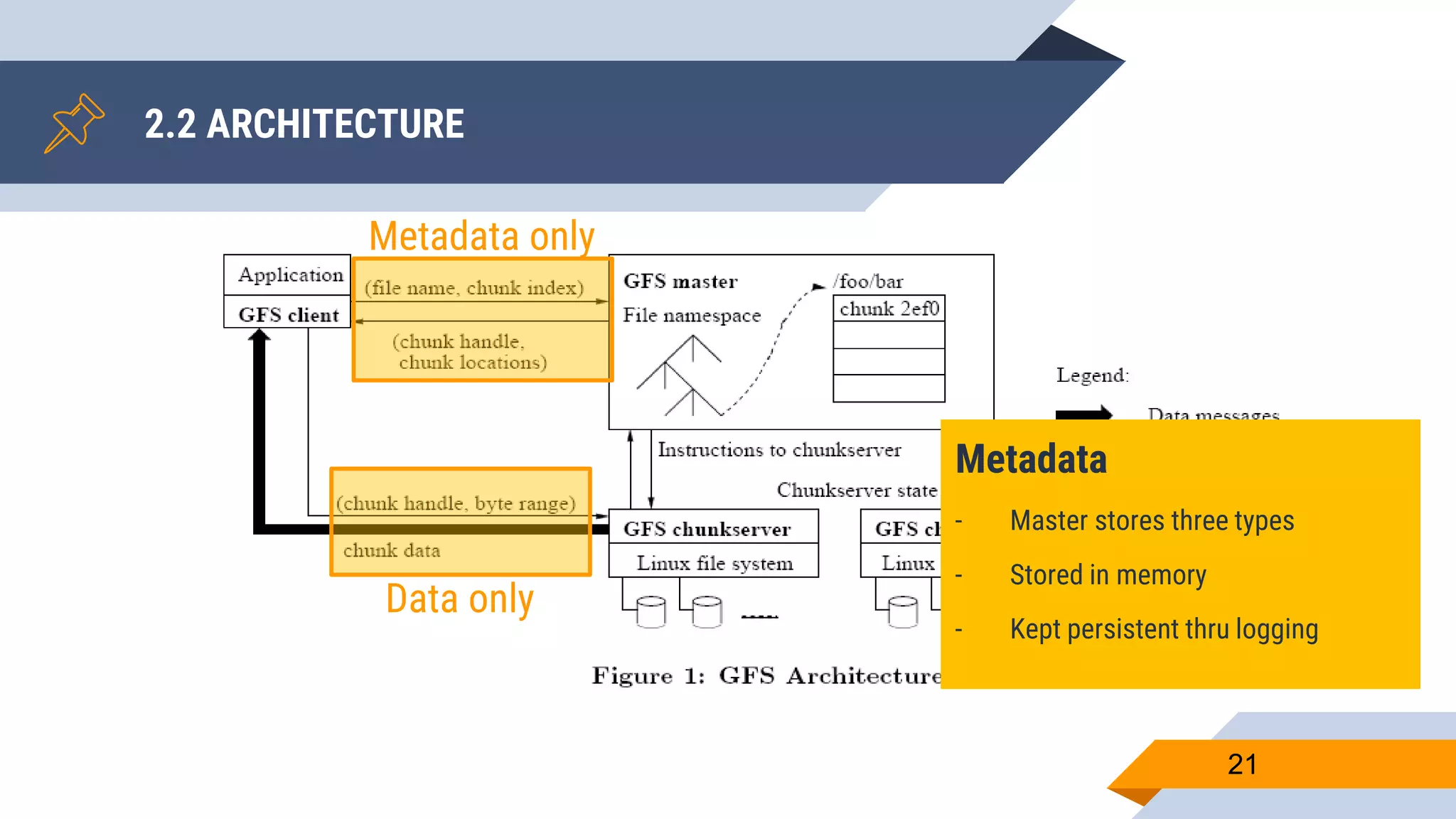



























The document summarizes the Google File System (GFS). It discusses the key points of GFS's design including: - Files are divided into fixed-size 64MB chunks for efficiency. - Metadata is stored on a master server while data chunks are stored on chunkservers. - The master manages file system metadata and chunk locations while clients communicate with both the master and chunkservers. - GFS provides features like leases to coordinate updates, atomic appends, and snapshots for consistency and fault tolerance.
















































![[KCC poster]정준영](https://cdn.slidesharecdn.com/ss_thumbnails/kccposter-170320133553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[KCC oral] 정준영](https://cdn.slidesharecdn.com/ss_thumbnails/presentation-181213110358-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Graduation Project] 전자석을 이용한 타자 연습기](https://cdn.slidesharecdn.com/ss_thumbnails/random-170605124558-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 평창올림픽 기념 SW 공모전] Nolza 보고서](https://cdn.slidesharecdn.com/ss_thumbnails/swatto-171228125353-thumbnail.jpg?width=640&height=640&fit=bounds)
![[대학생 연합 해커톤 UNITHON 3RD] Mingginyu_ppt](https://cdn.slidesharecdn.com/ss_thumbnails/15iot-161204120355-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Maybee] inSpot](https://cdn.slidesharecdn.com/ss_thumbnails/maybeeinspot-161204125845-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2015전자과공모전] ppt](https://cdn.slidesharecdn.com/ss_thumbnails/2015-161204112925-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Kcc poster] 정준영](https://cdn.slidesharecdn.com/ss_thumbnails/kccposter-170624041745-thumbnail.jpg?width=640&height=640&fit=bounds)
![[team608] 전자석을 이용한 타자연습기](https://cdn.slidesharecdn.com/ss_thumbnails/random-170704062658-thumbnail.jpg?width=640&height=640&fit=bounds)
![[C++]6 function2](https://cdn.slidesharecdn.com/ss_thumbnails/6function2-161204061932-thumbnail.jpg?width=640&height=640&fit=bounds)
![[우아주, 7월] 정준영](https://cdn.slidesharecdn.com/ss_thumbnails/7-170726085554-thumbnail.jpg?width=640&height=640&fit=bounds)
![[우아주, Etc] 정준영 - 페이시스템](https://cdn.slidesharecdn.com/ss_thumbnails/etc-170726085645-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2016 K-global 스마트디바이스톤] inSpot](https://cdn.slidesharecdn.com/ss_thumbnails/4inspot-161204120340-thumbnail.jpg?width=640&height=640&fit=bounds)
![[UNITHON 5TH] KOK - 프로귀찮러를 위한 지출관리 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/7-170801072235-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2018 평창올림픽 기념 SW 공모전] Nolza - Activity curation service](https://cdn.slidesharecdn.com/ss_thumbnails/nolzafinalpptf-171228123419-thumbnail.jpg?width=640&height=640&fit=bounds)



















