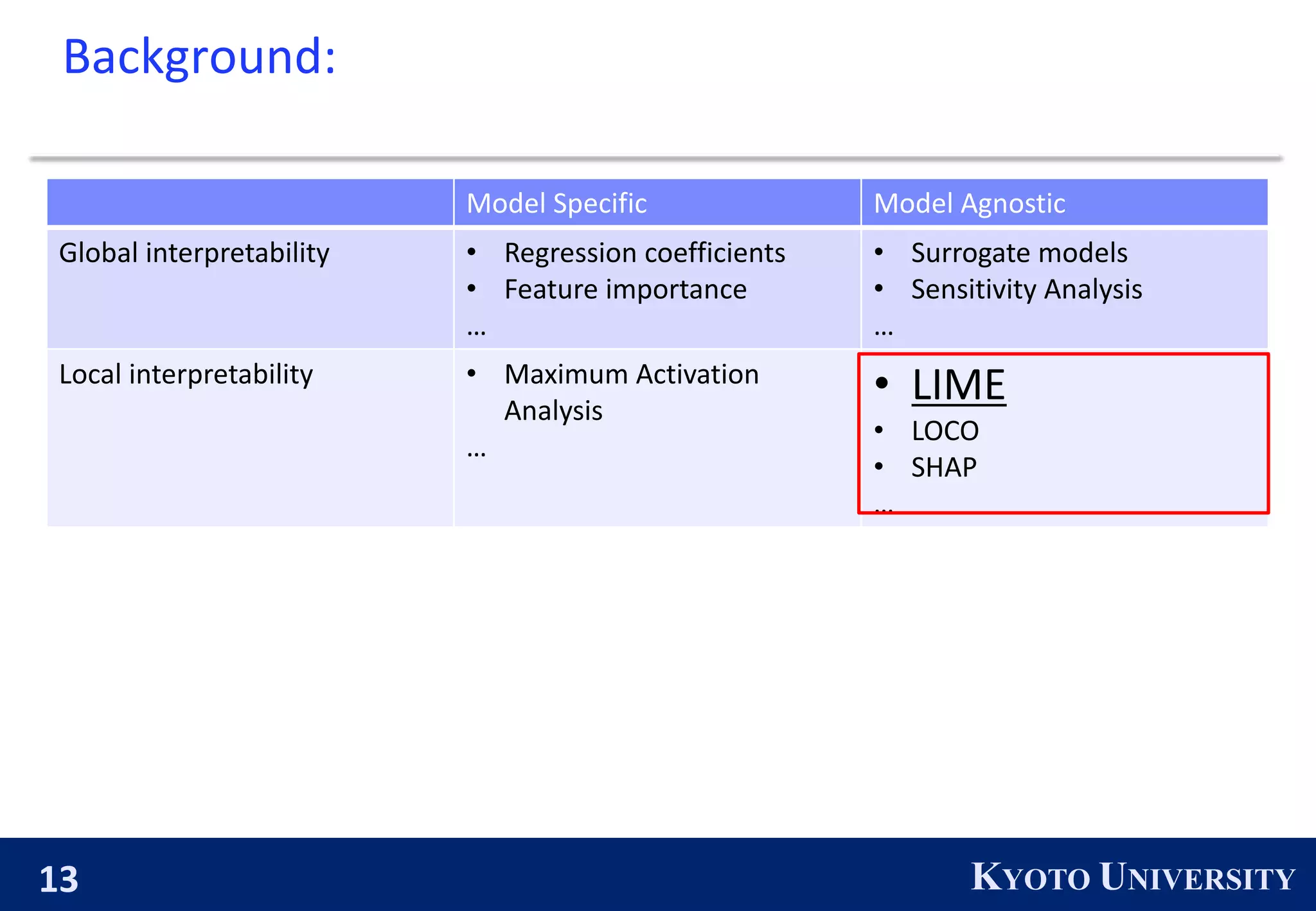
1) The document discusses LIME (Local Interpretable Model-Agnostic Explanations), a method for explaining the predictions of any machine learning model. LIME works by training an interpretable model locally around predictions to approximate the original model.
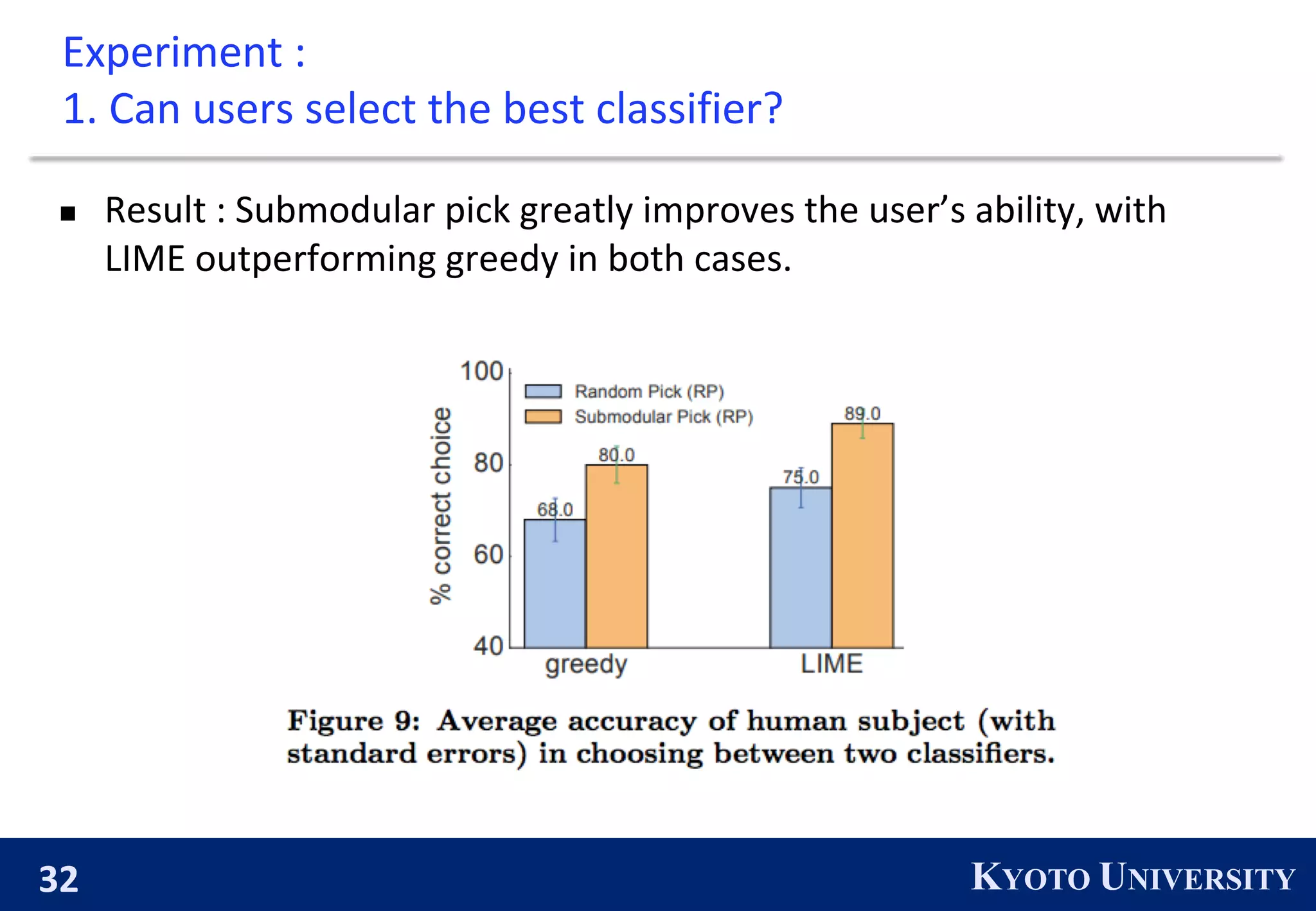
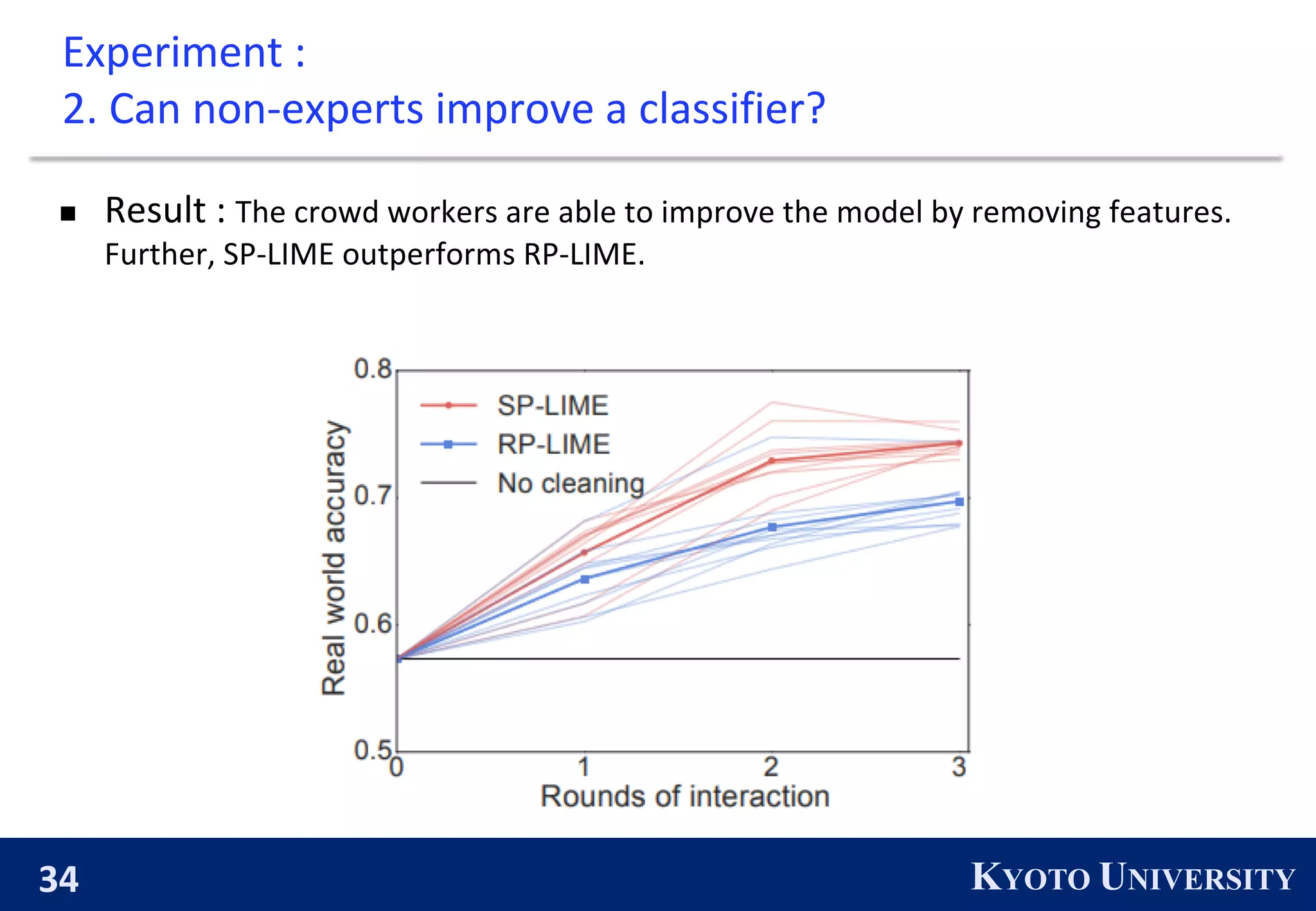
2) Experiments show that LIME explanations help human subjects select better performing classifiers, identify features to improve classifiers, and gain insights into how classifiers work.
3) SP-LIME is introduced to select a representative set of predictions to provide a global view of a model, by maximizing coverage of important features.














































































![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Paper reading] L-SHAPLEY AND C-SHAPLEY: EFFICIENT MODEL INTERPRETATION FOR S...](https://cdn.slidesharecdn.com/ss_thumbnails/l-shapley-190705085327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Reading] Theoretical Analysis of Self-Training with Deep Networks on U...](https://cdn.slidesharecdn.com/ss_thumbnails/miidaspaperreading20210423-210425115856-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Paper Reading] Causal Bandits: Learning Good Interventions via Causal Inference](https://cdn.slidesharecdn.com/ss_thumbnails/reading201912-191206052456-thumbnail.jpg?width=640&height=640&fit=bounds)




![Anomaly Detection with VAEGAN and Attention [JSAI2019 report]](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2019report-190612095817-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
