Download as PDF, PPTX








![Weakness Detection by Error Slicing
11
1. Specify an appropriate metric based on individual prediction residuals:
e.g., MSE for regression, ACC/AUC for classification, train-test
performance gap (for checking overfit), prediction interval bandwidth, ...
2. Specify 1 or 2 slicing features of interest;
3. Evaluate the metric for each sample in the target data (training or testing)
as pseudo responses;
4. Segment the target data along the slicing features, by
a) [Unsupervised] Histogram slicing with equal-space binning, or
b) [Supervised] fitting a decision tree to generate the sub-regions
5. Identify the sub-regions with average metric exceeding the pre-specified
threshold, subject to minimum sample condition.](https://image.slidesharecdn.com/machinelearningmodelvalidationaijunzhang2024-240320163726-c8b1333d/85/Machine-Learning-Model-Validation-Aijun-Zhang-2024-pdf-11-320.jpg)





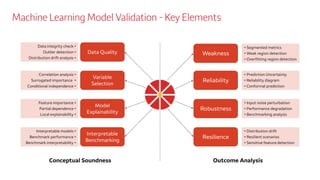
The document outlines a comprehensive approach to machine learning model validation, focusing on an effective risk management program for AI/ML models. It emphasizes the importance of interpretability, data quality checks, and robustness against distribution shifts in models, along with providing tools and strategies for model explanation and evaluation. Additionally, it discusses the integration of a standardized validation process to streamline the validation and monitoring of dynamically updating models.



































































