Download to read offline















![© 2016 IBM Corporation
Example: Use of Scala Functions as Values
Scala has first class functions – they can be treated as values
val square = (x: Int) => { x * x }
Implemented by scalac using generic interfaces!
val square = new Function2[Int, Int] {
def apply(x: Int): Int = x * x
}
Calls to function values site is highly uncertain
– Program contains many different classes that implement Function2
– Hard to tell which Function2 implementer to inline
def filter(values: List[A], checkOp: A => Boolean): List[A] = {
var result: List[A] = Nil
for (v <- values) { if (checkOp(v)) { result = result :: v } }
return result
}](https://image.slidesharecdn.com/apachecon-spark-2016-161121115026/85/Apache-Big-Data-Europe-2016-18-320.jpg)






![© 2016 IBM Corporation27
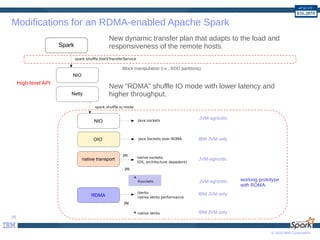
Time to complete TeraSort benchmark
32 cores (1 master, 4 nodes x 8 cores/node, 32GB Mem/node), IBM Java 8
0 100 200 300 400 500 600
Spark HiBench TeraSort [30GB]
Execution Time (sec)
556s
159s
TCP/IP
JSoR](https://image.slidesharecdn.com/apachecon-spark-2016-161121115026/85/Apache-Big-Data-Europe-2016-27-320.jpg)





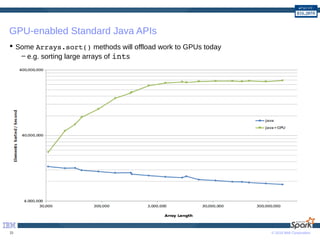




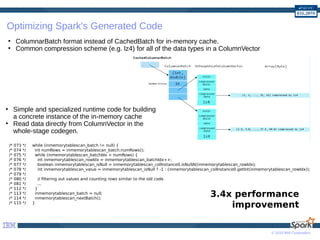



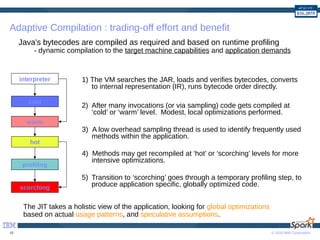
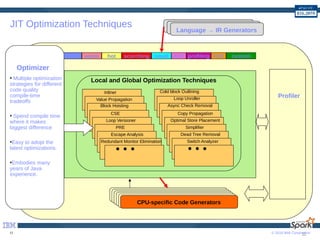
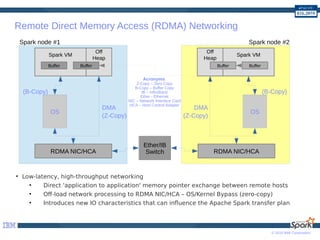
The document provides a comprehensive guide to optimizing Apache Spark performance using Java. It discusses optimizations through JIT compilation, memory management, and the use of advanced networking and storage technologies, including RDMA and GPU acceleration. The document highlights techniques for profiling workloads, reducing code complexity, and leveraging Scala features to enhance Spark's efficiency.











































































