Download as PDF, PPTX



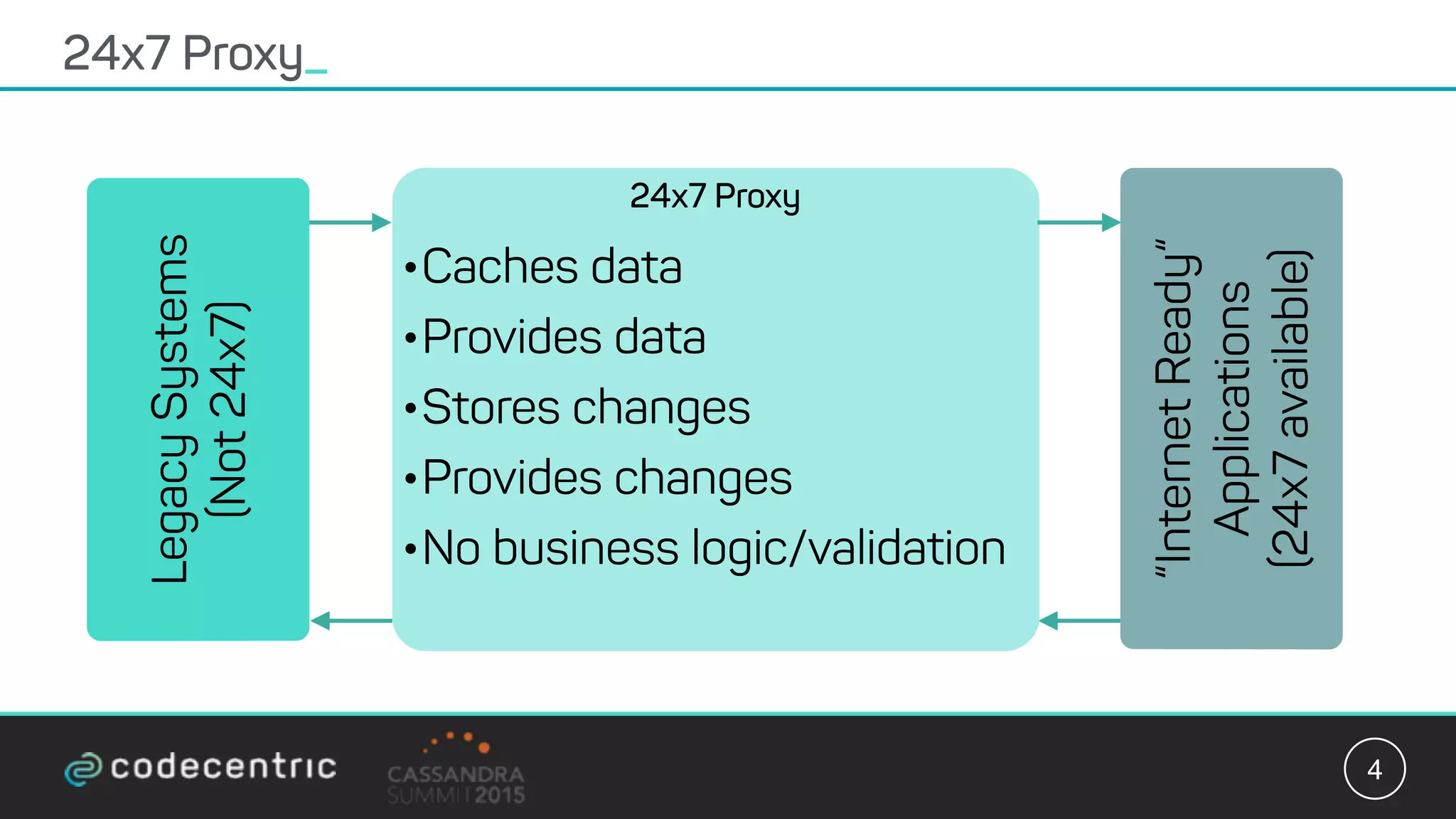


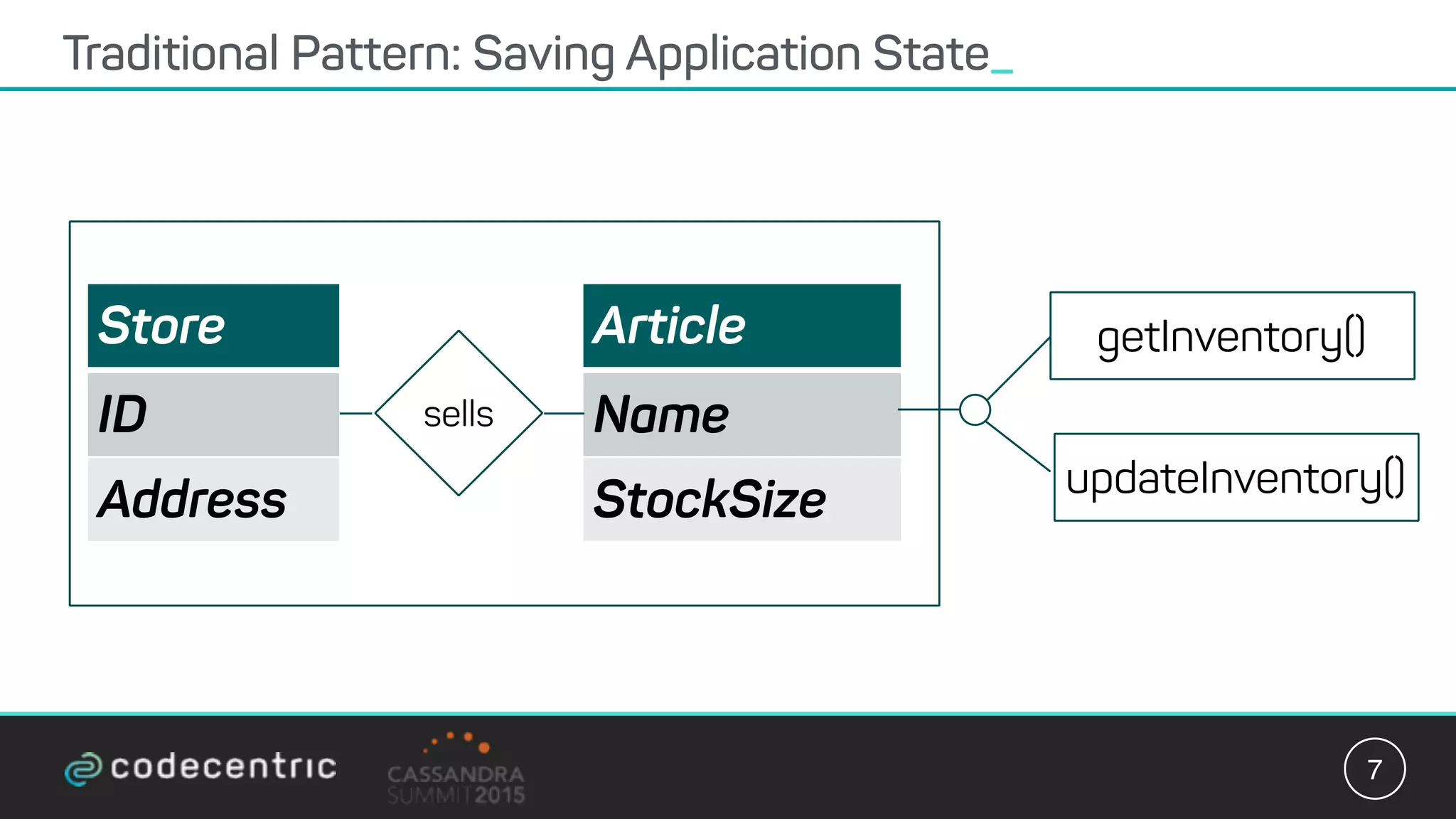

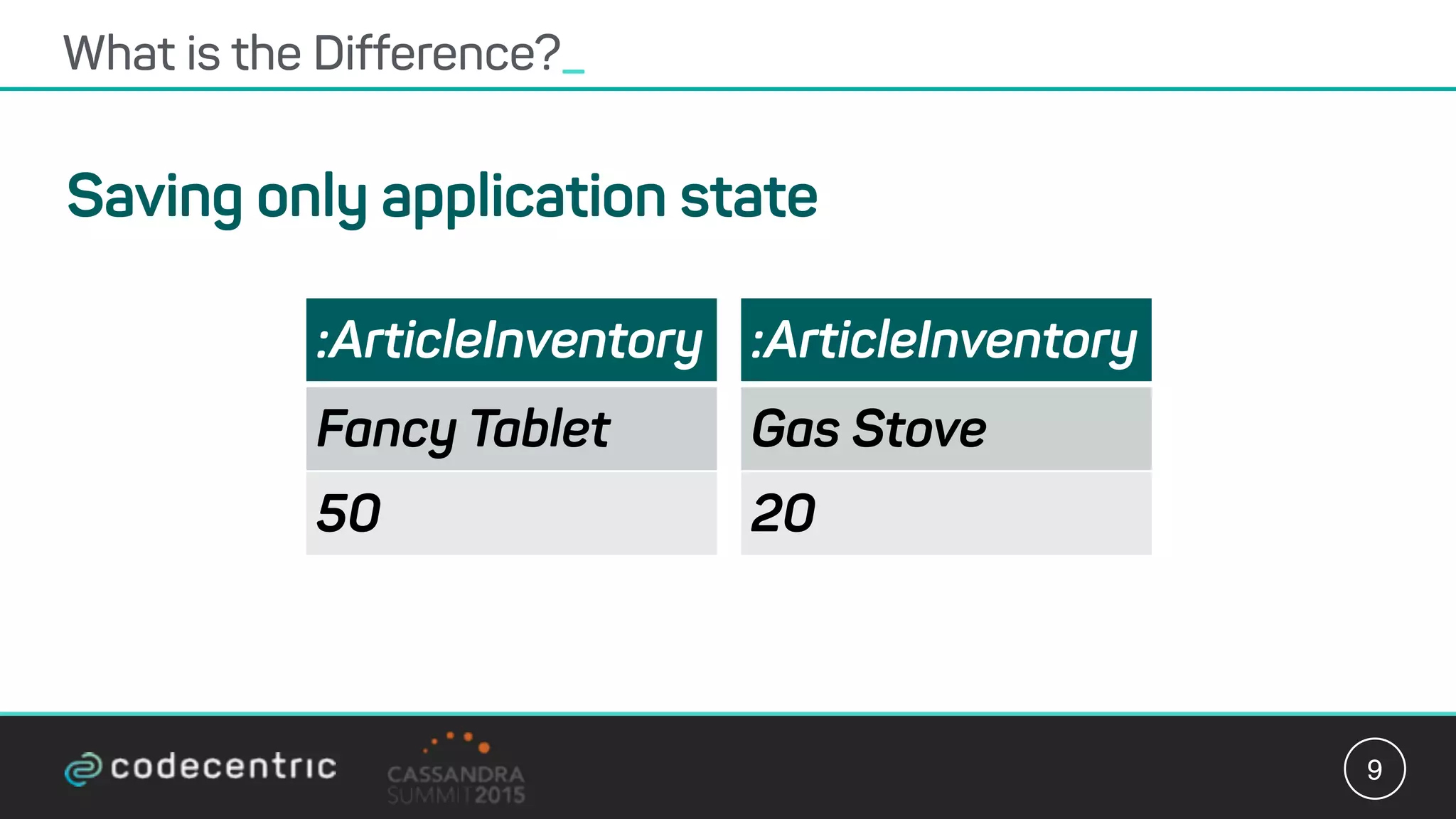



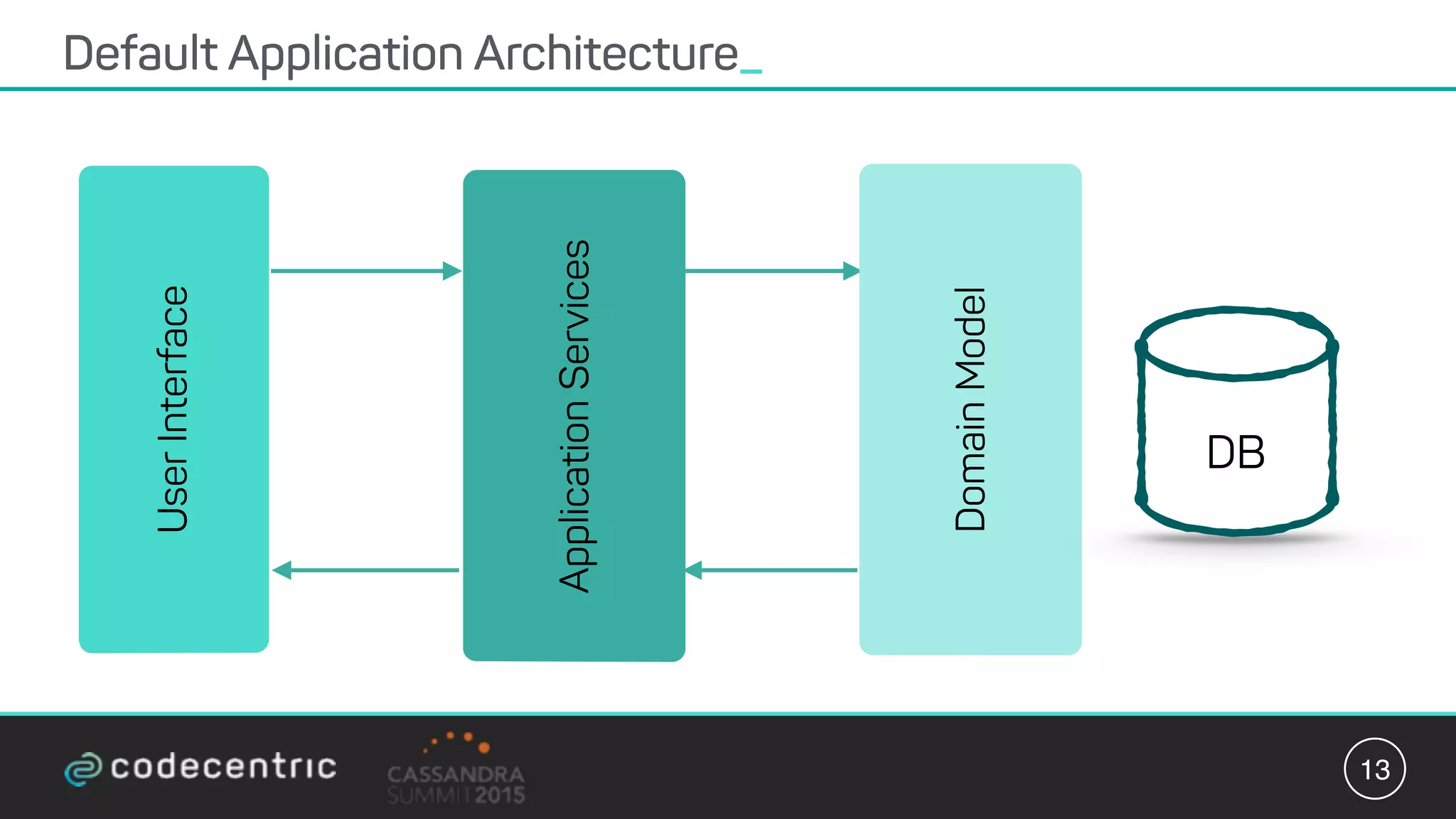
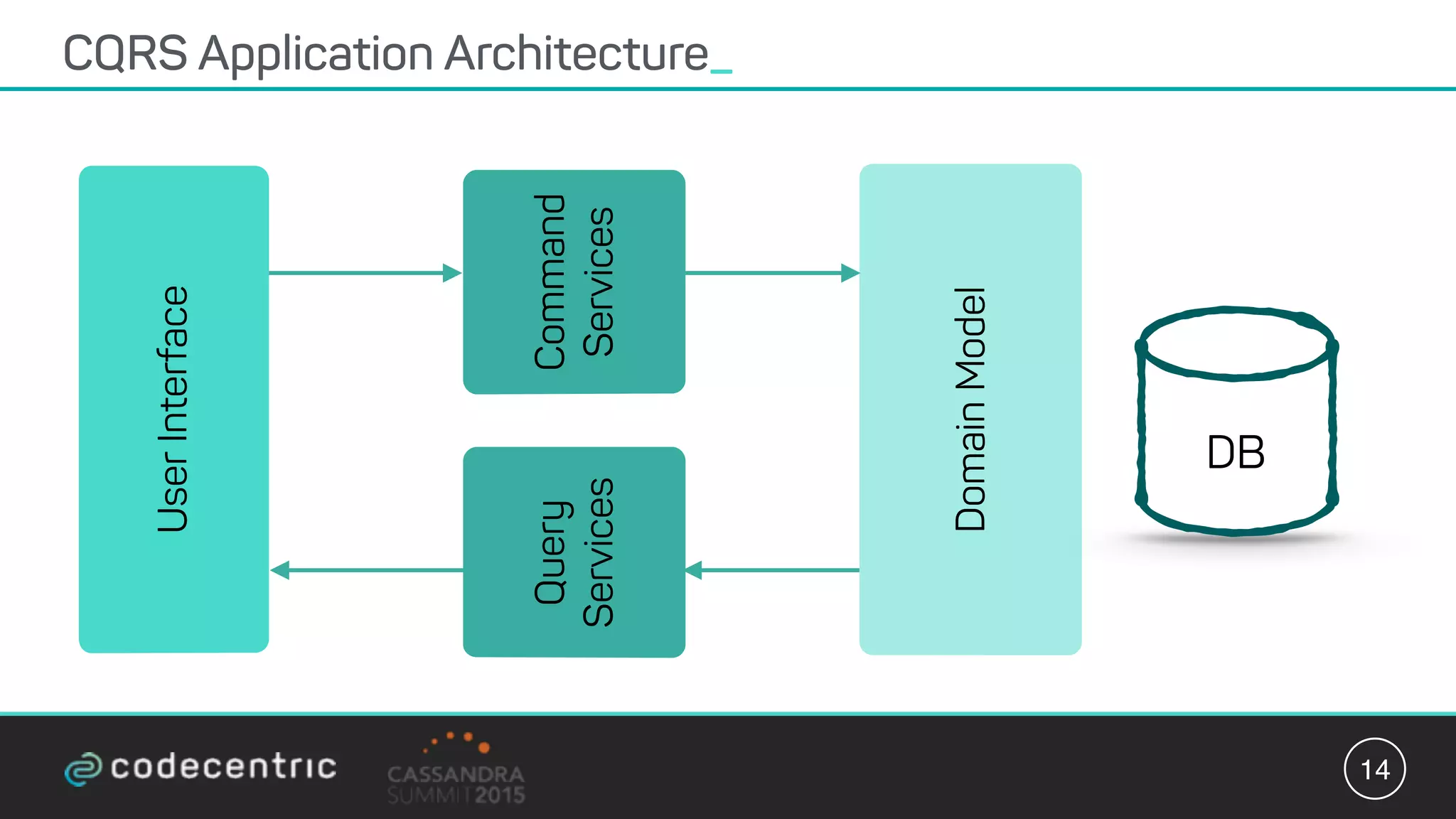

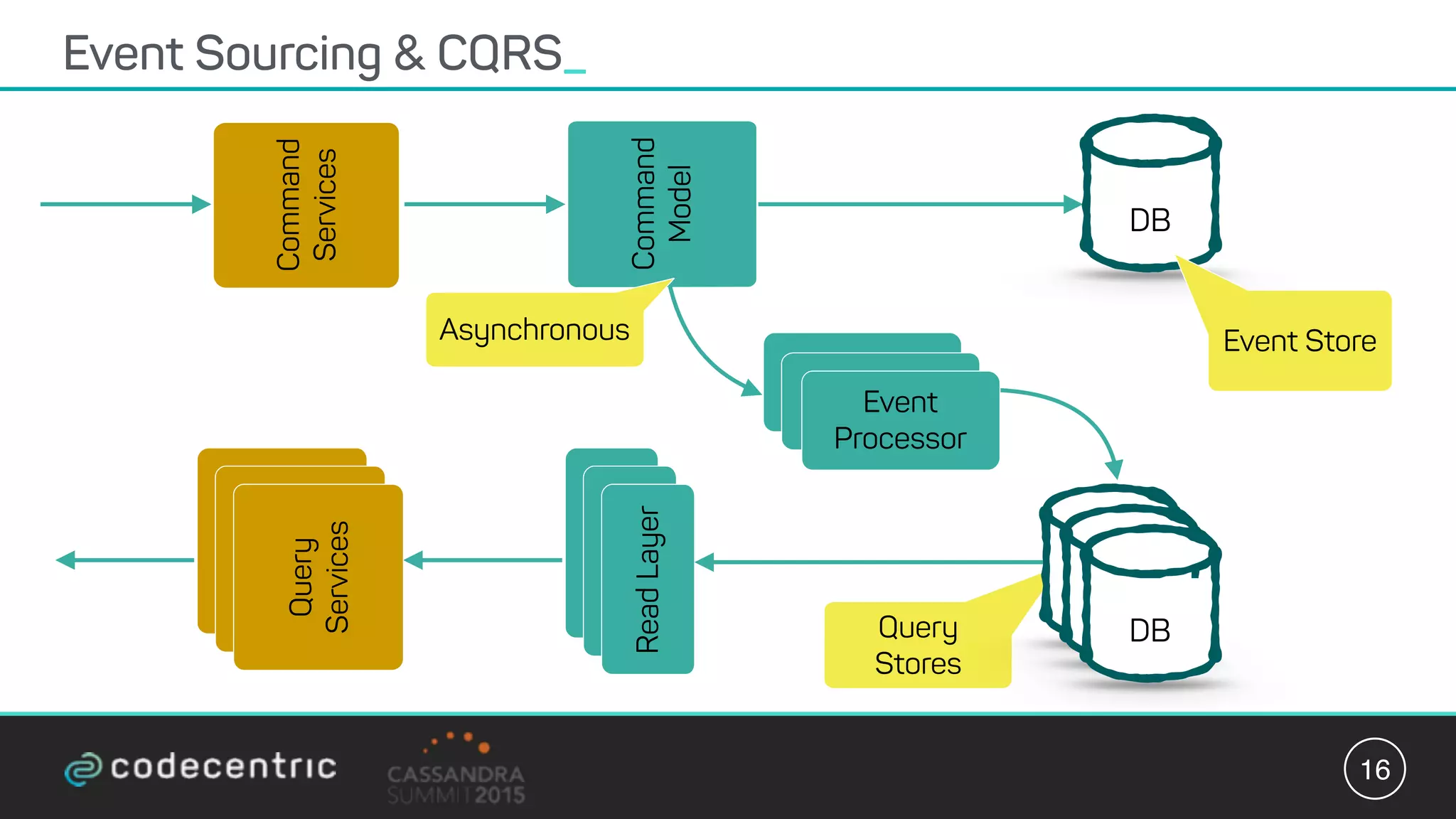








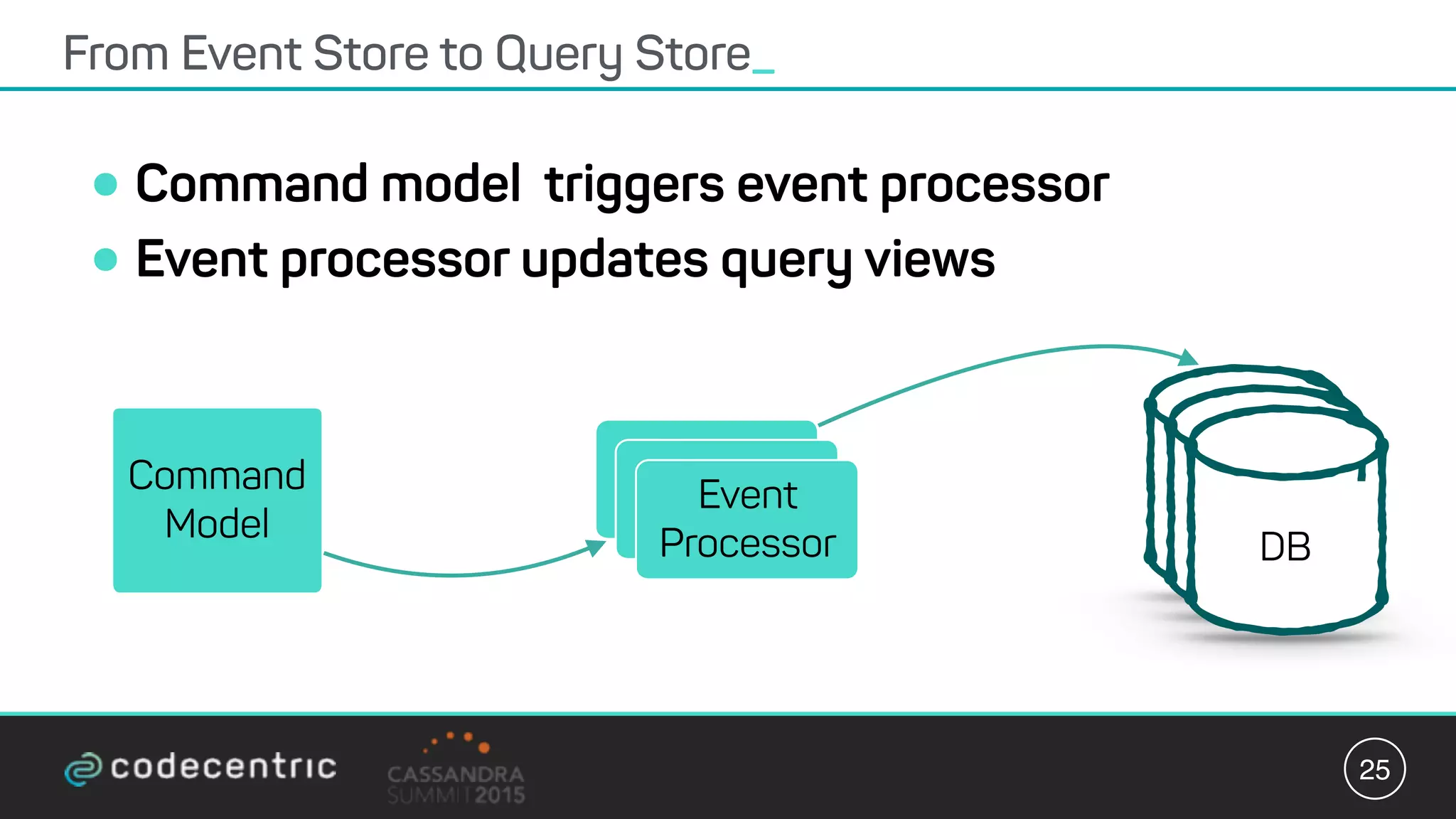
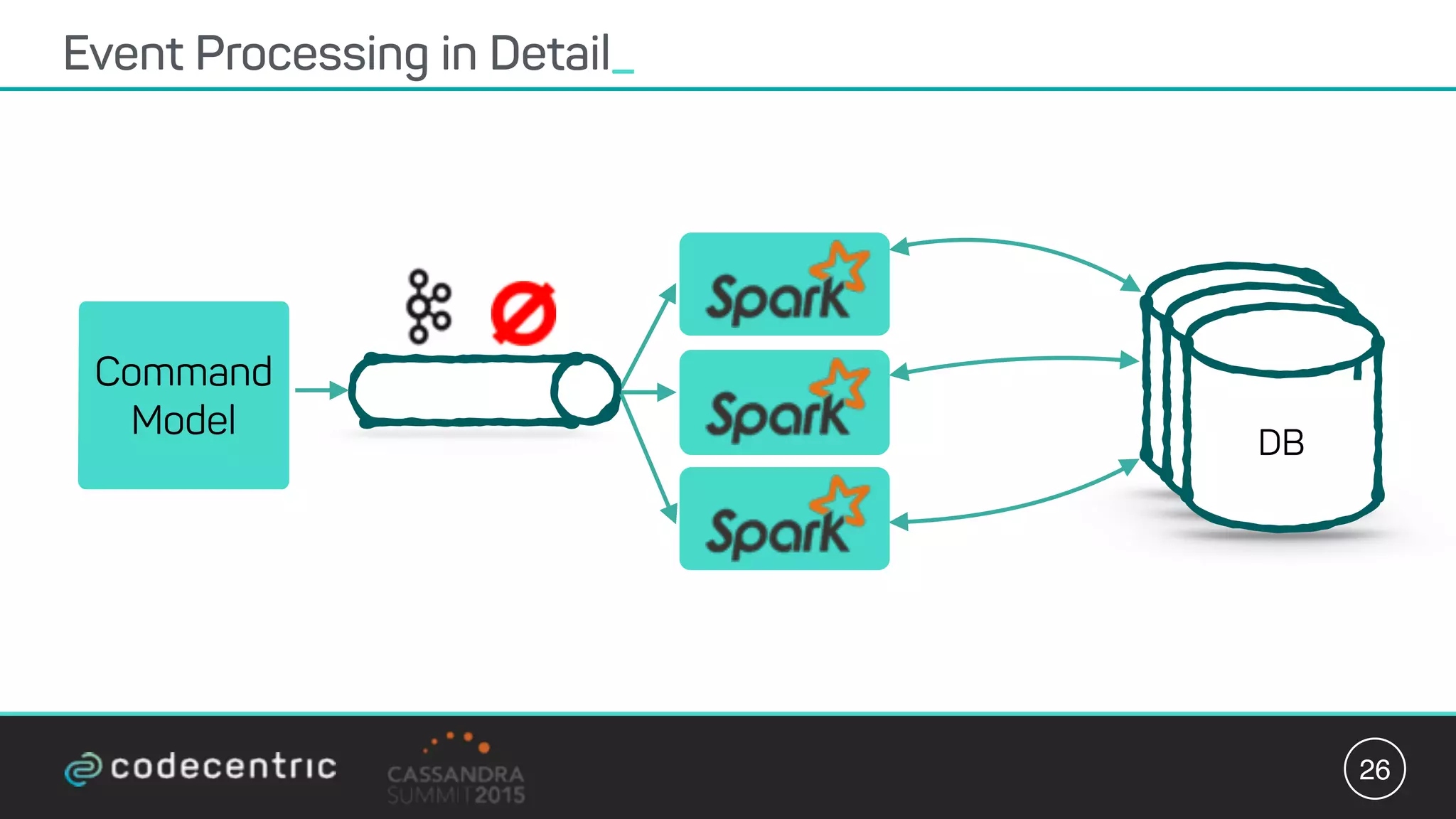






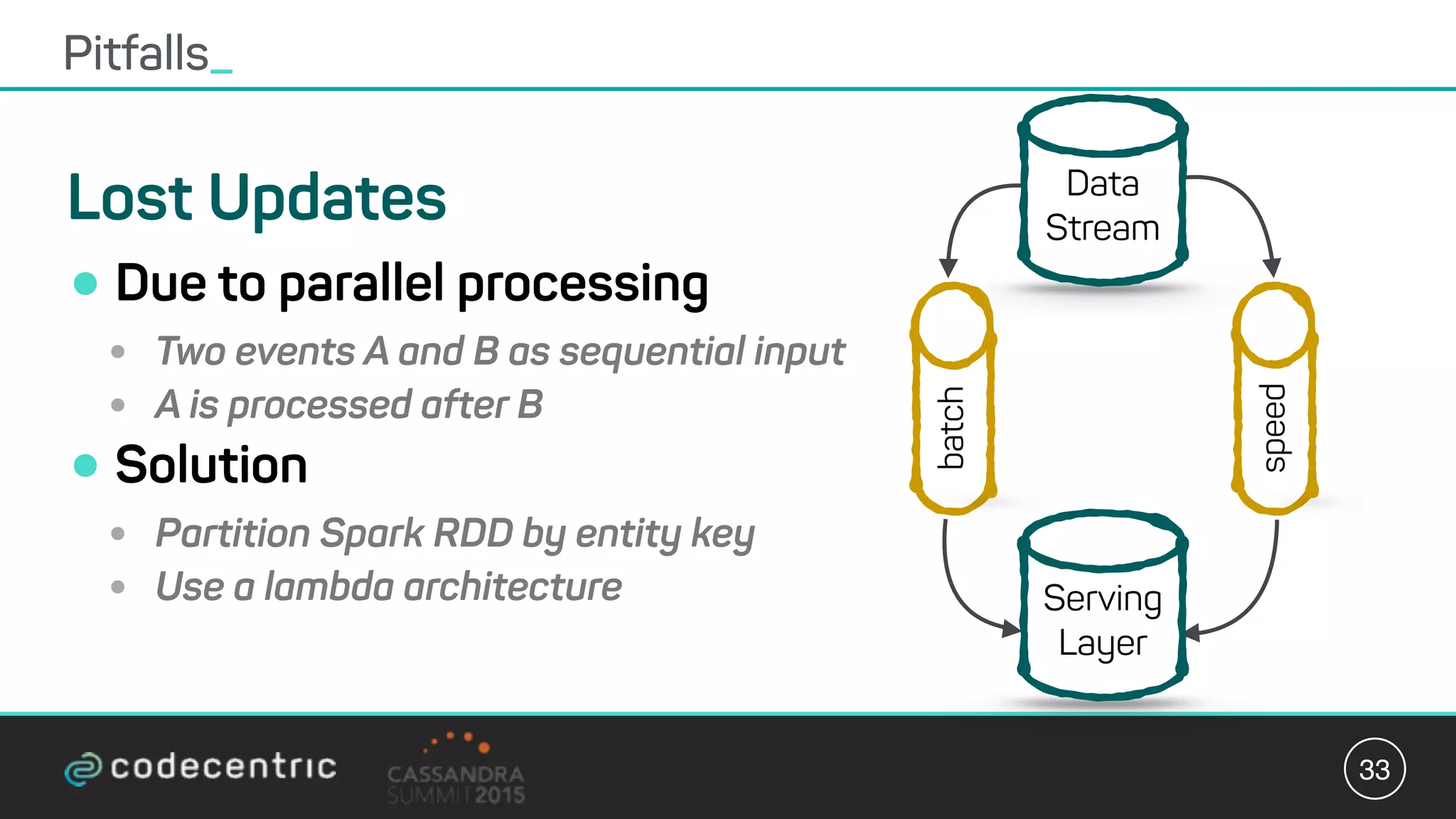


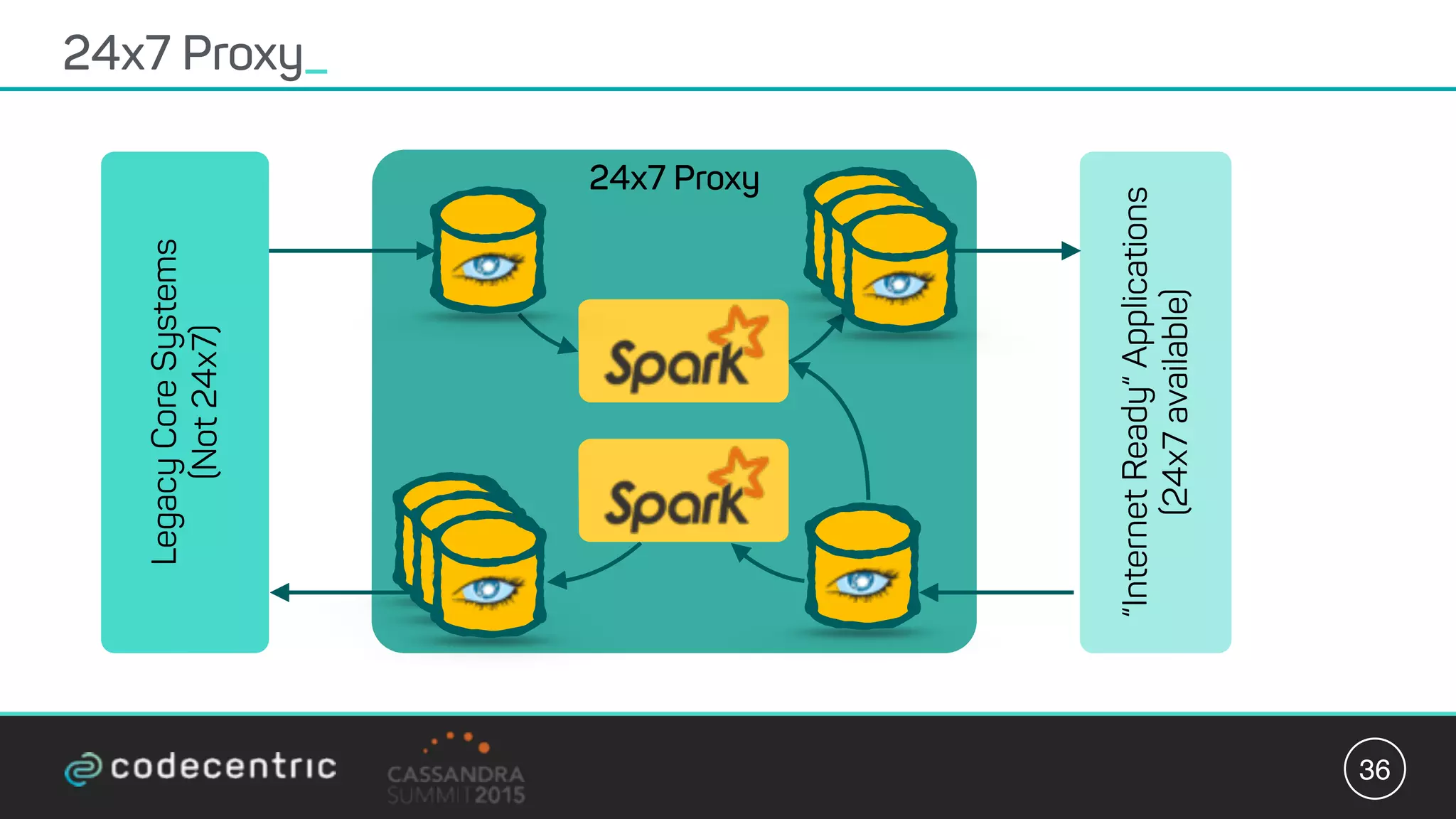



Matthias Niehoff's presentation discusses the integration of CQRS and event sourcing with Cassandra for building scalable, 24/7 applications. The approach emphasizes the benefits of storing events over traditional state saving, allowing for improved querying and processing using frameworks like Spark. Niehoff outlines both the advantages and challenges of this architecture, including scalability and complexity in handling concurrent writes.



















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











