Downloaded 130 times






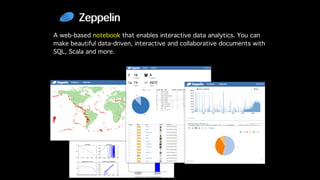


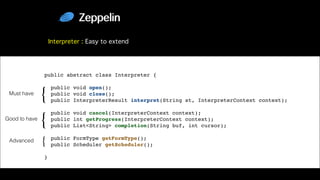


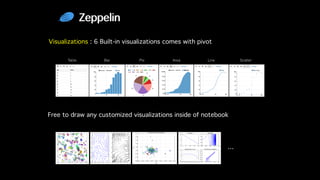

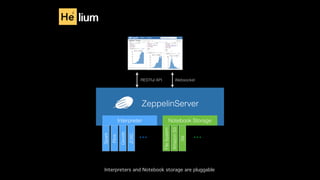

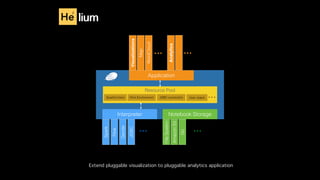

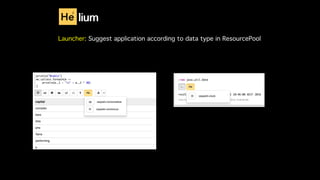







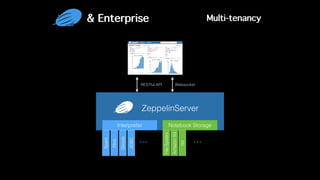
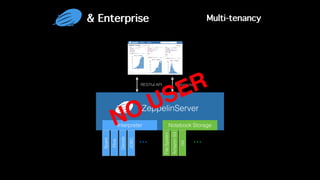

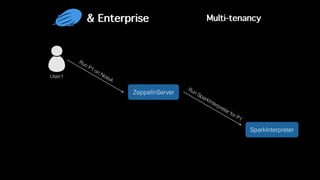
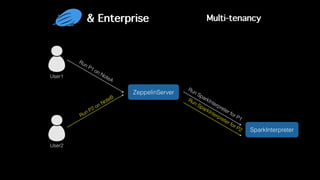

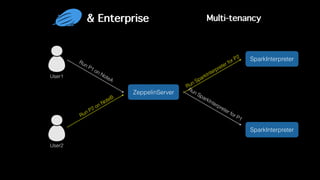

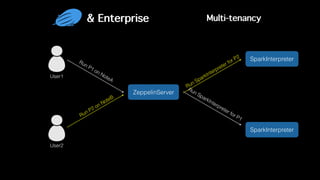
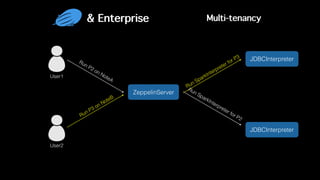
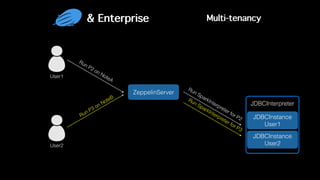


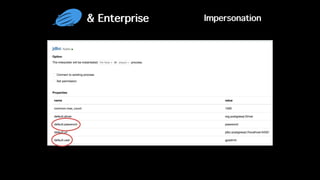

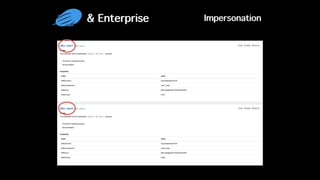
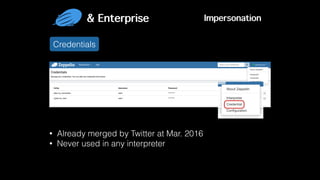
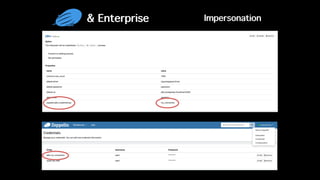








This document discusses Apache Zeppelin, an open-source web-based notebook that enables interactive data analytics. It provides an overview of Zeppelin's history and architecture, including how interpreters and notebook storage are pluggable. The document also outlines Zeppelin's roadmap for improving enterprise support through features like multi-tenancy, impersonation, job management and frontend performance.
























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





