

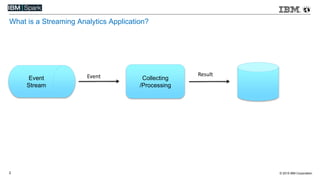
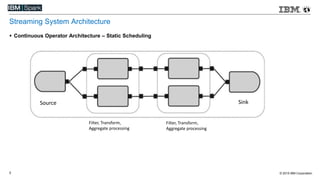
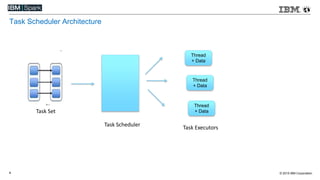


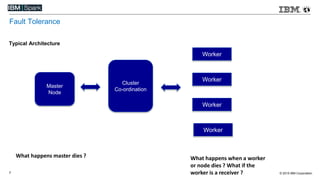






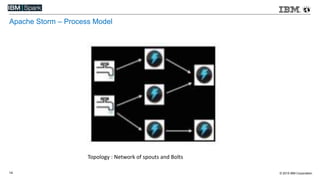

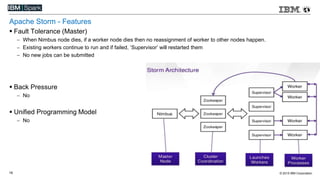



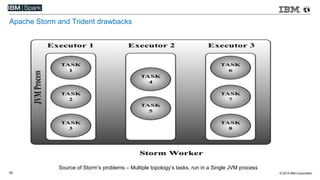

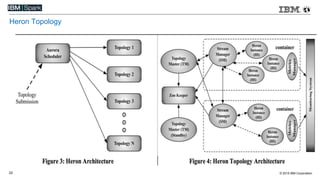

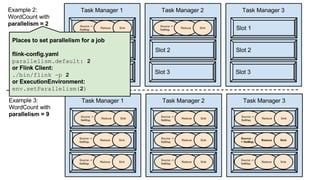
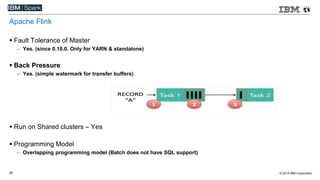
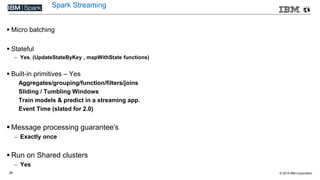

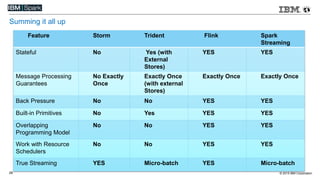






This document compares various streaming analytics technologies including Apache Storm, Apache Trident, Apache Flink, and Spark Streaming. It discusses key features needed in streaming applications such as fault tolerance, message processing guarantees, back pressure, and resource utilization. It then provides an overview of each technology, describing their architectures, programming models, support for features like state management, and ability to run on shared clusters. The document concludes with suggestions on how to benchmark Spark Streaming applications.






















































































