Downloaded 15 times


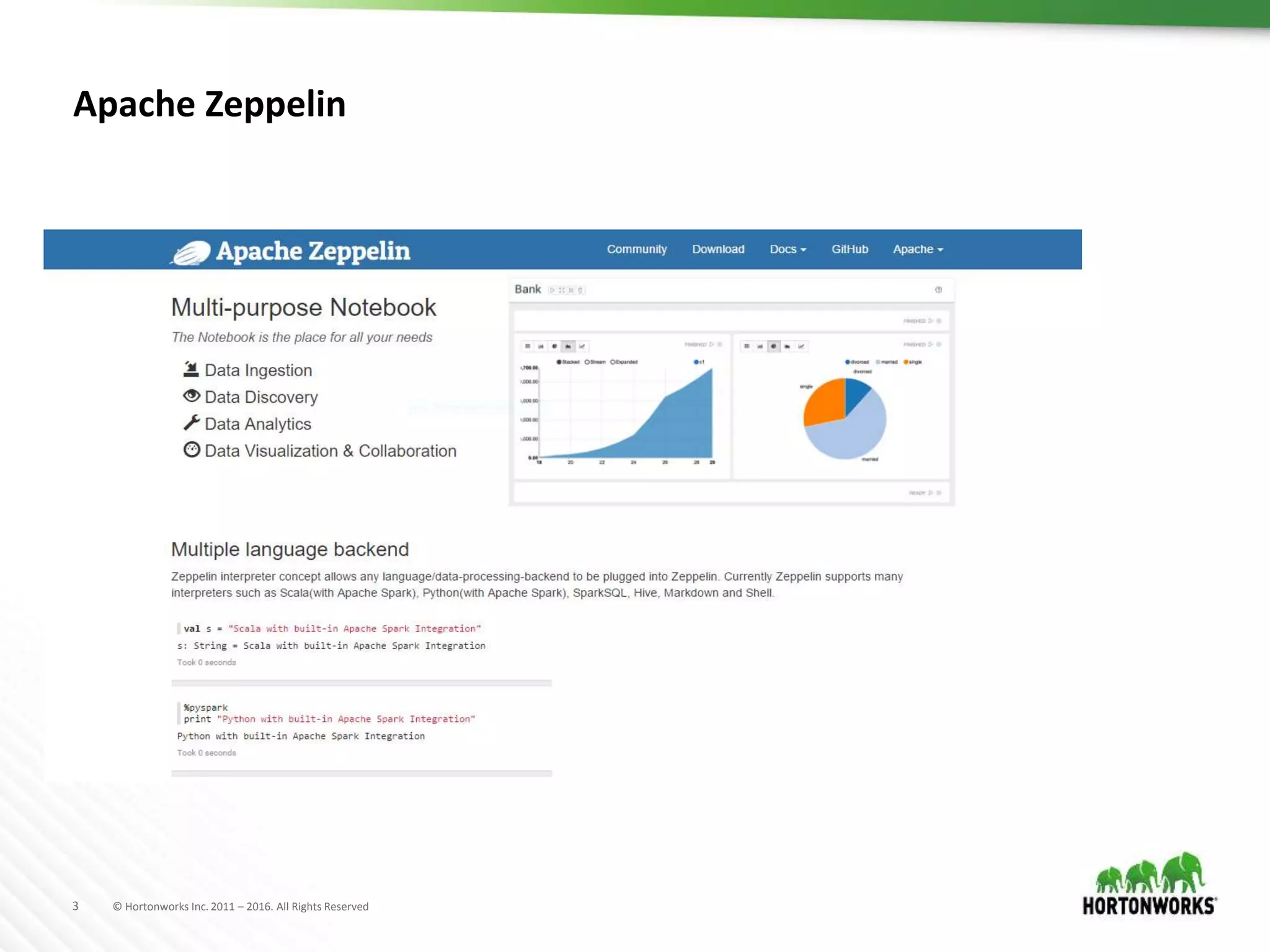

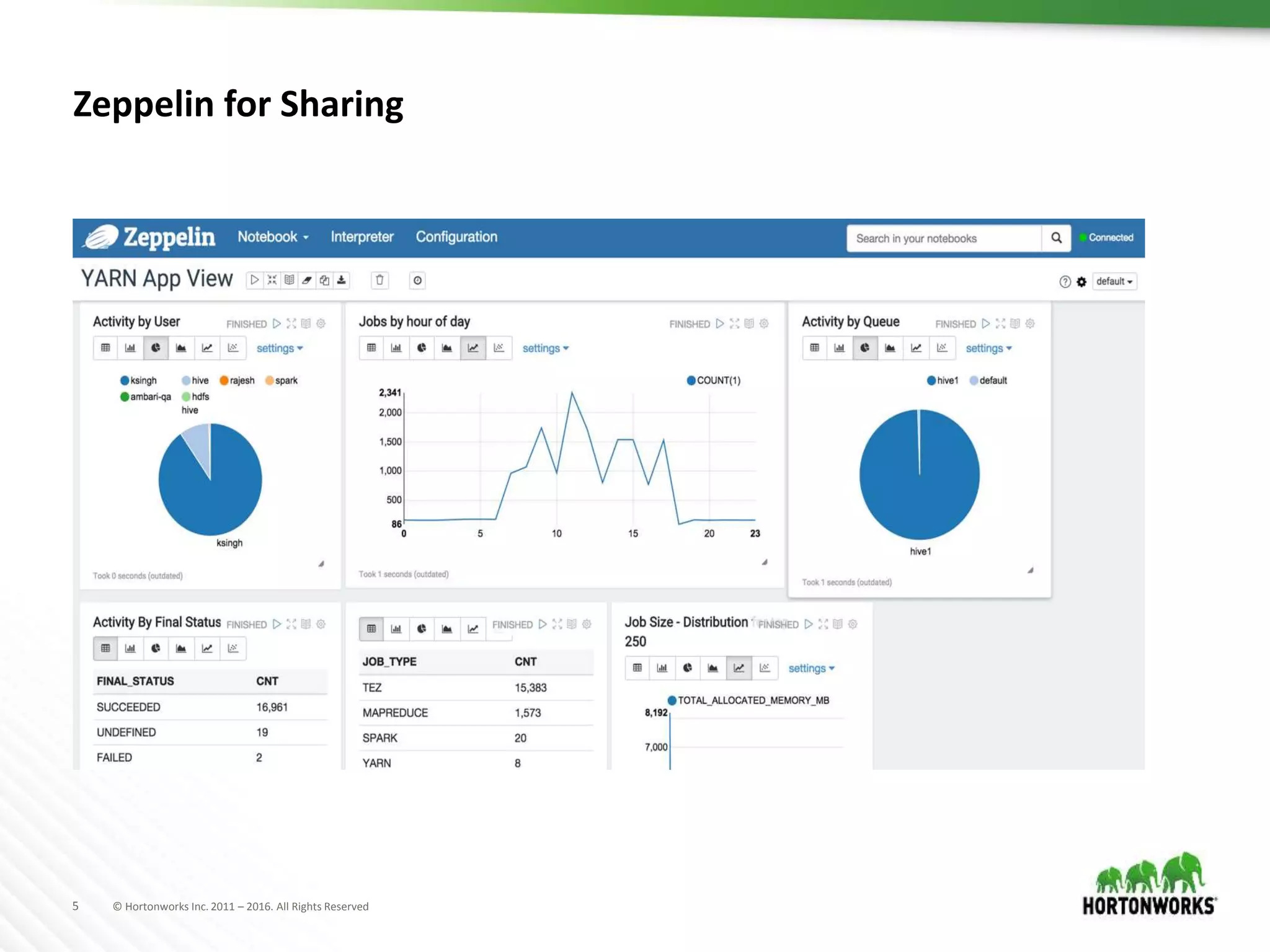

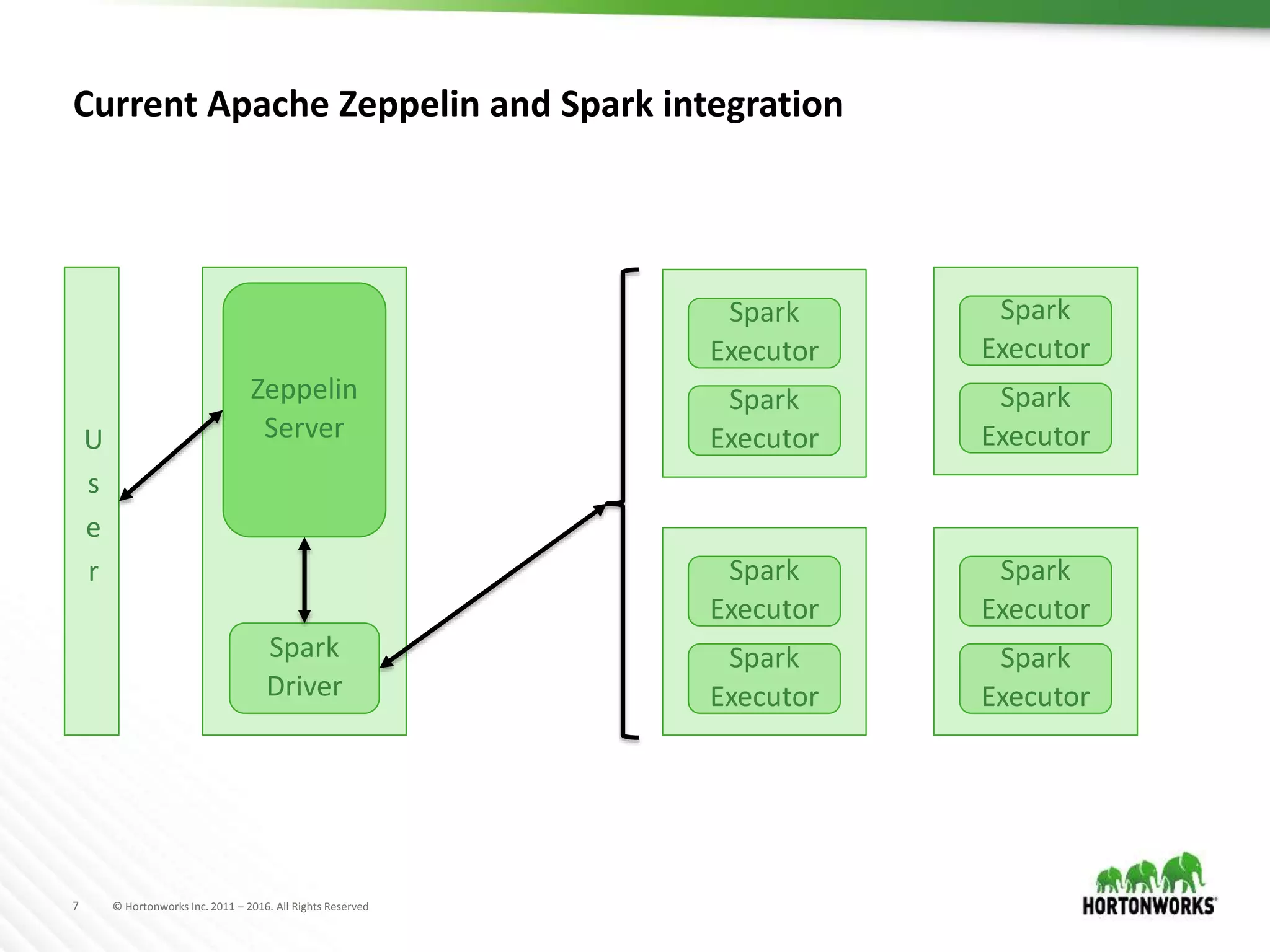
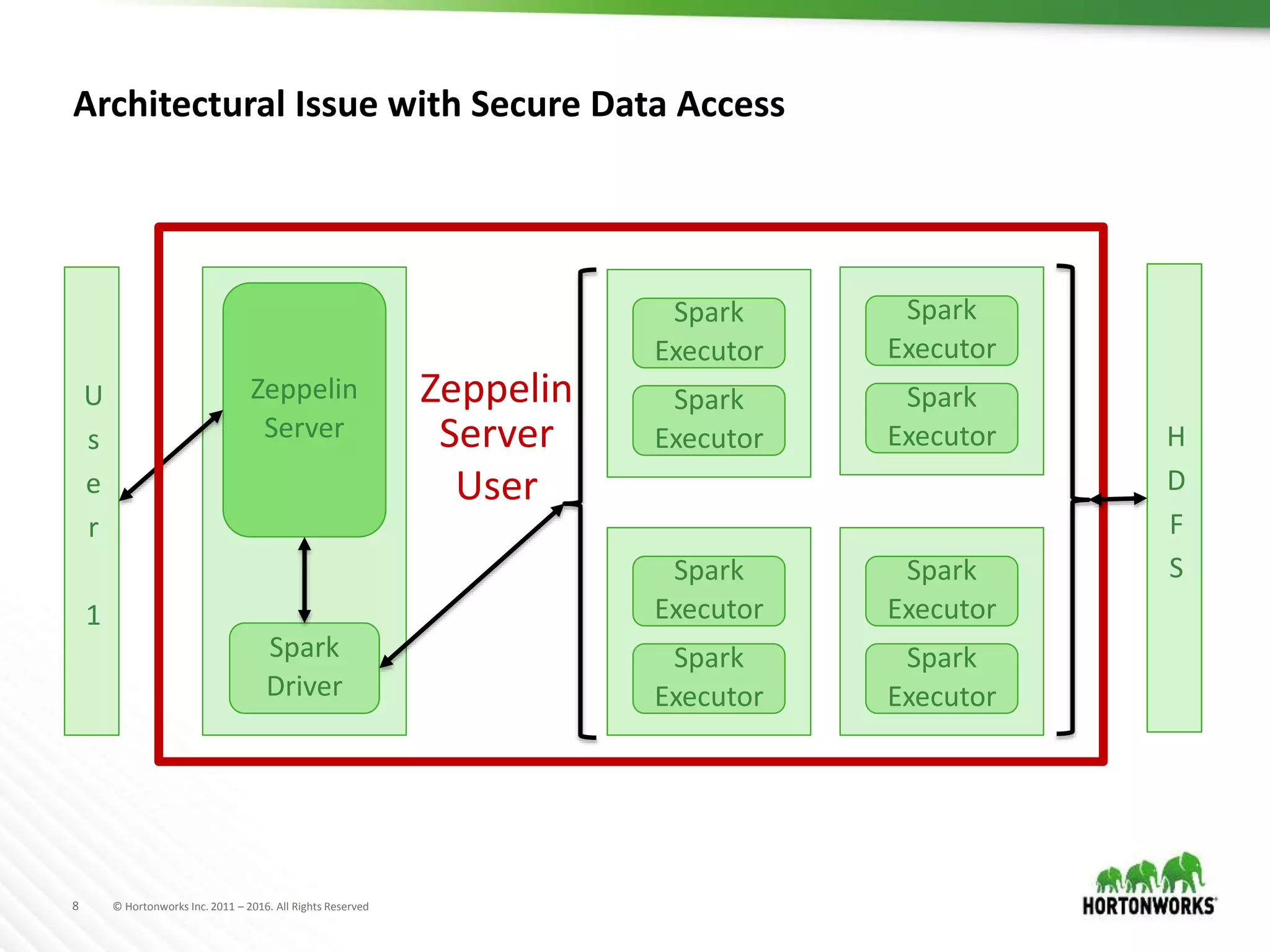
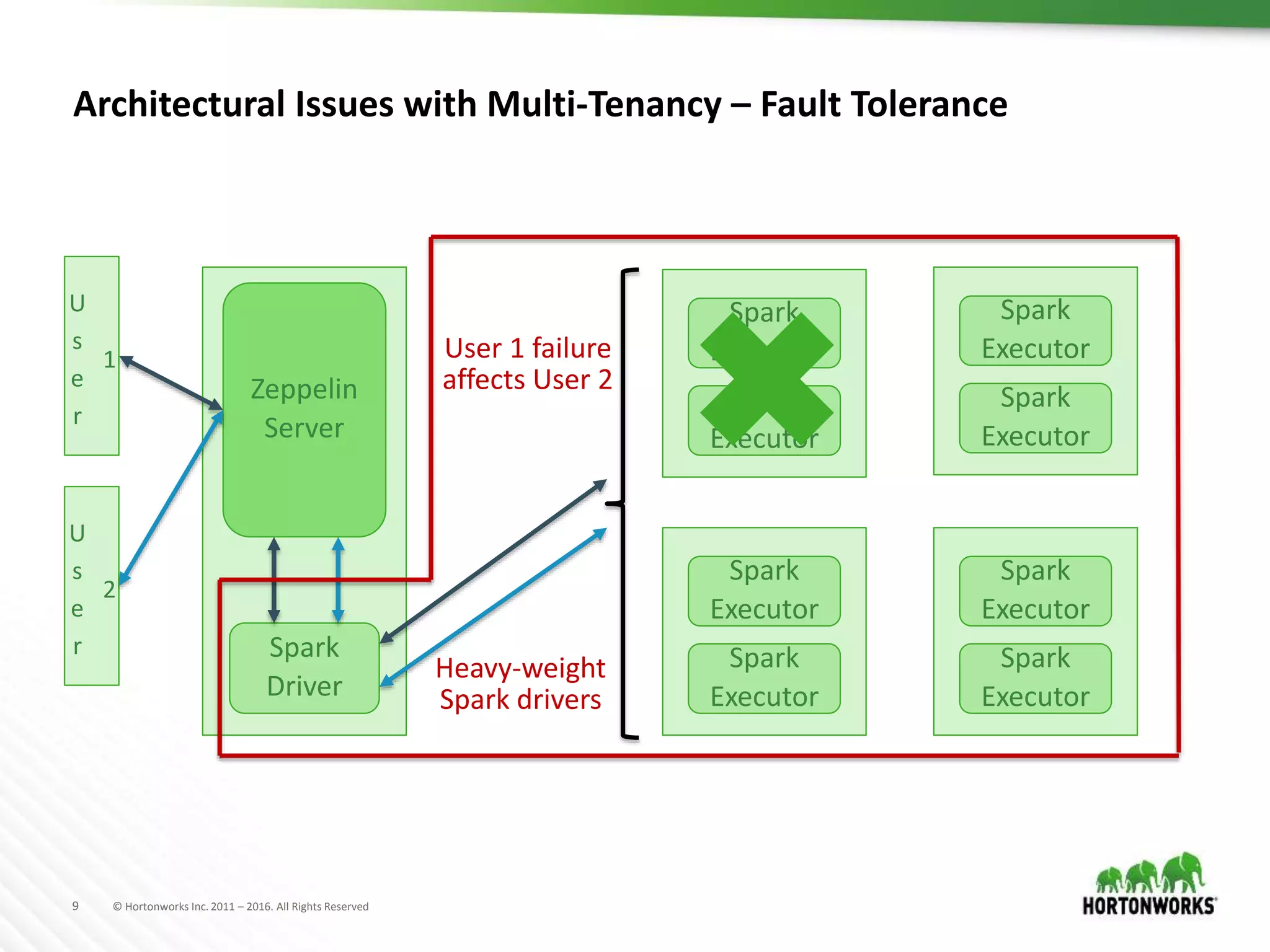
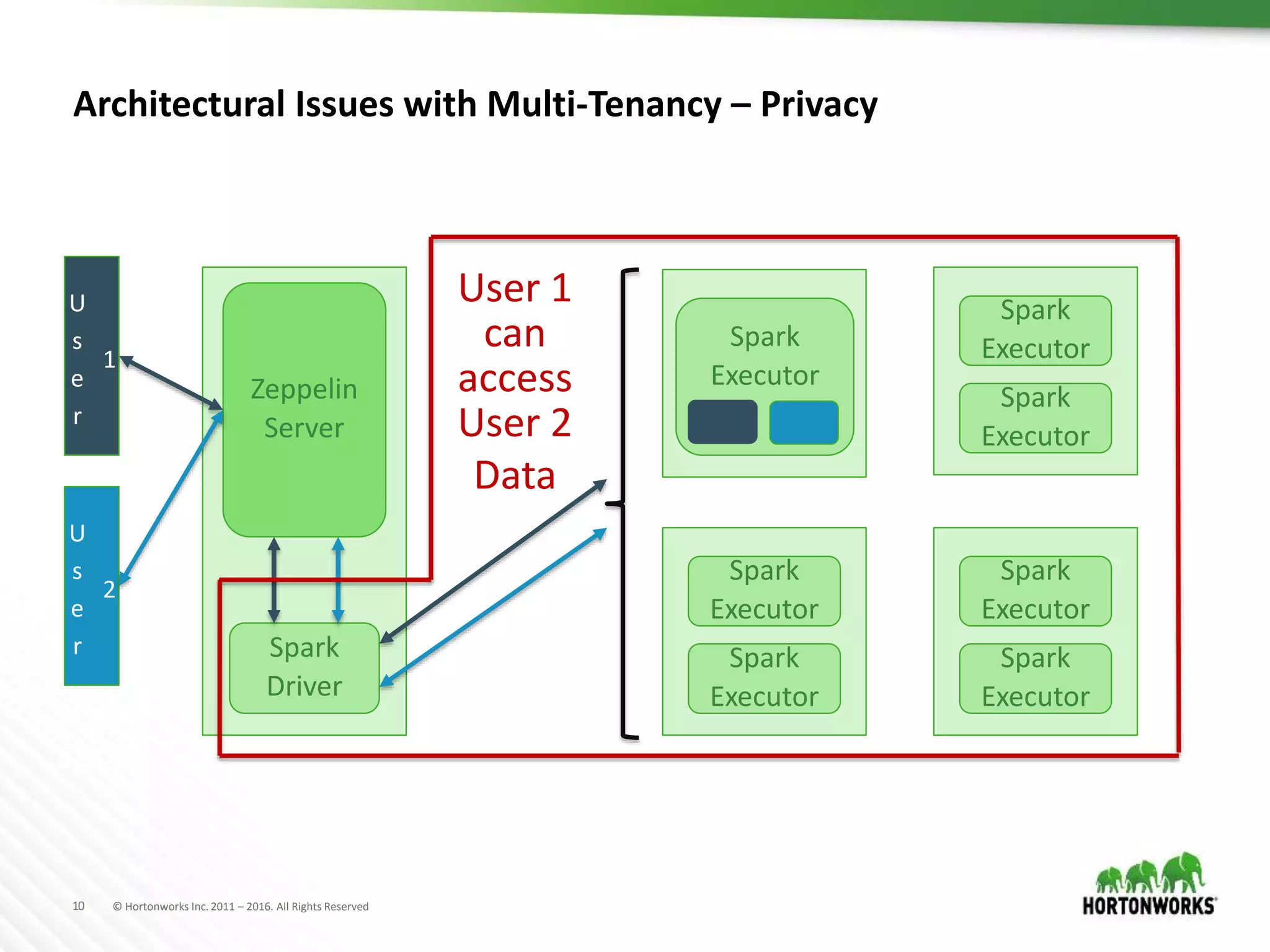

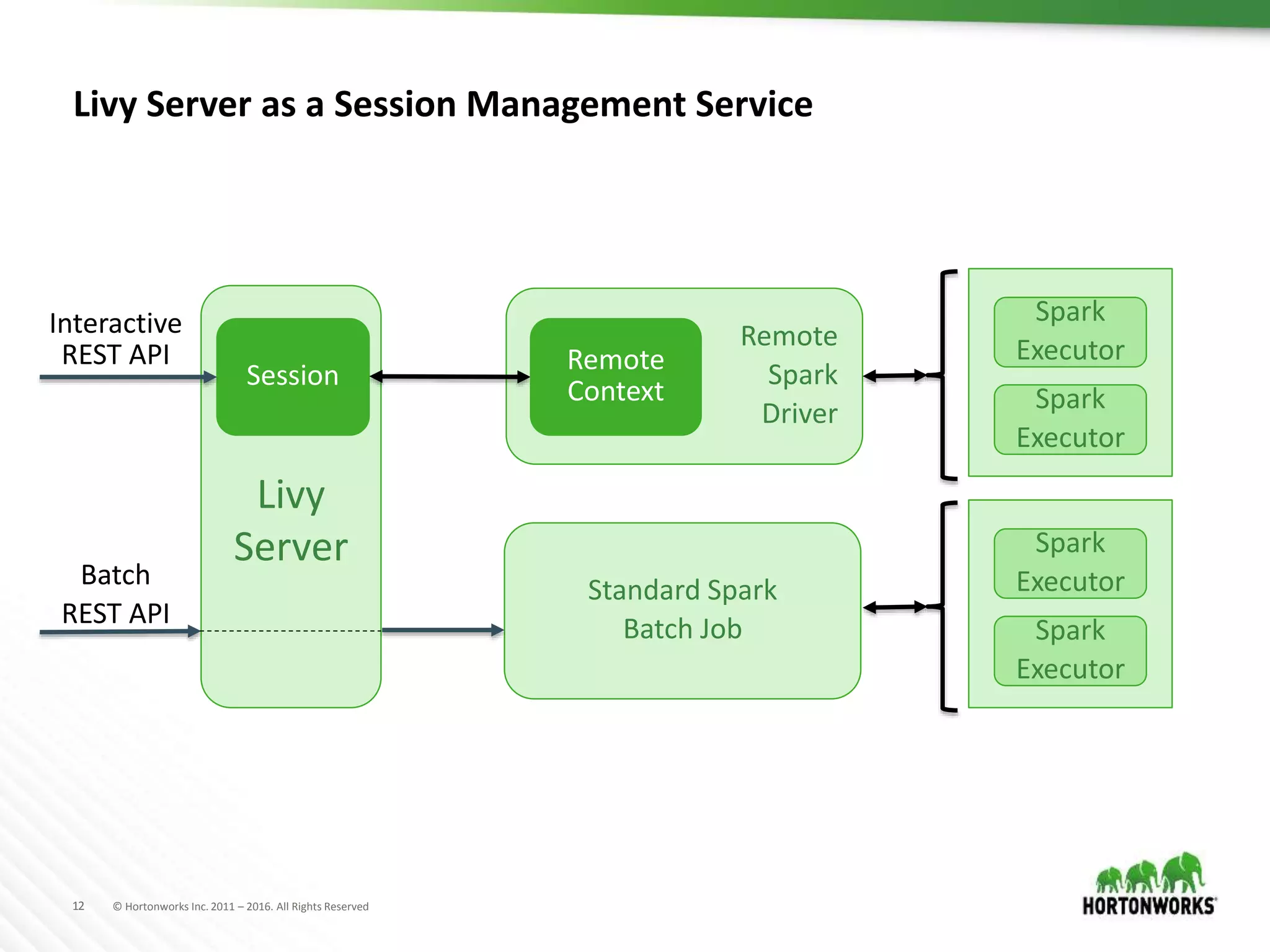
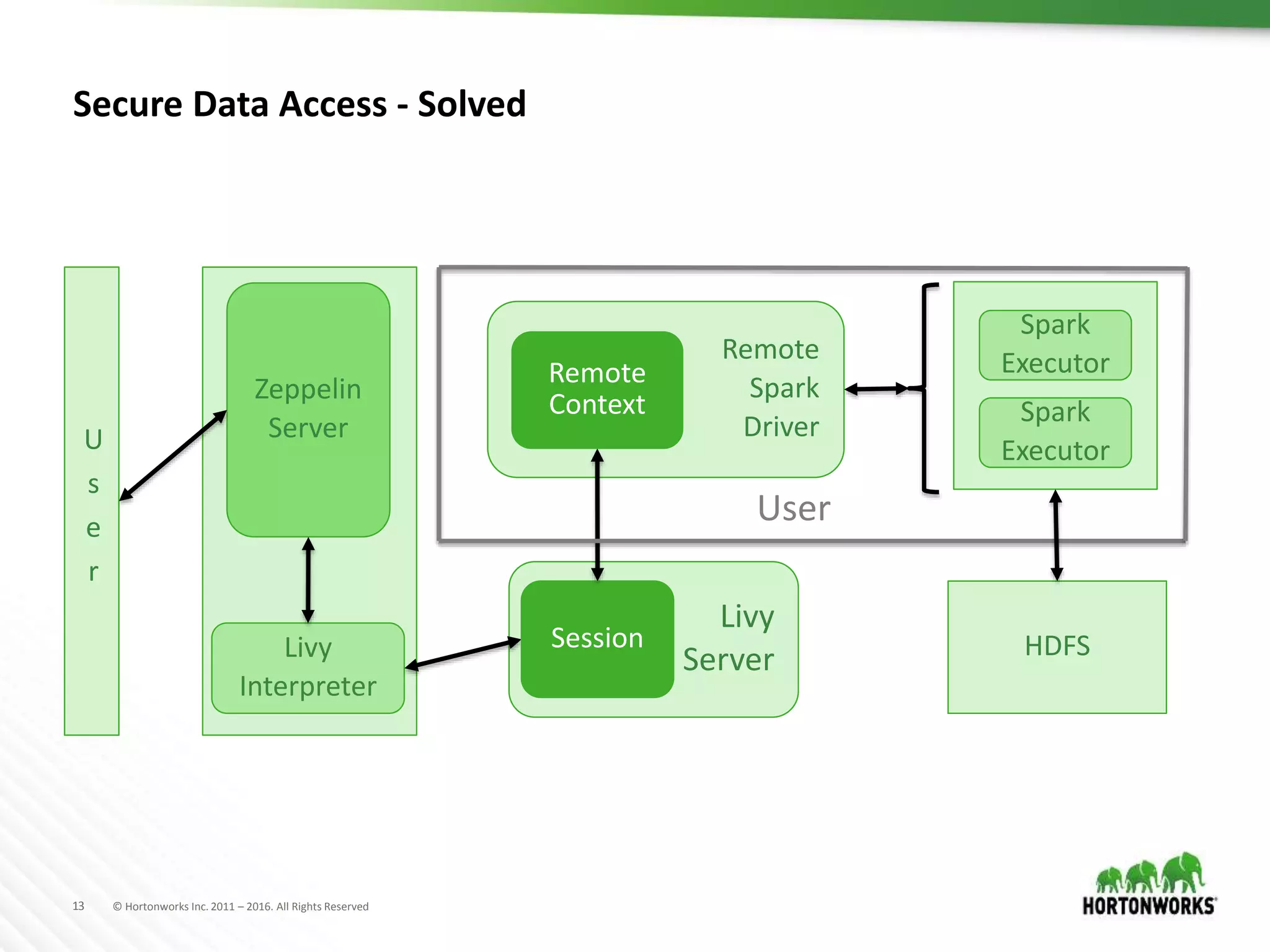
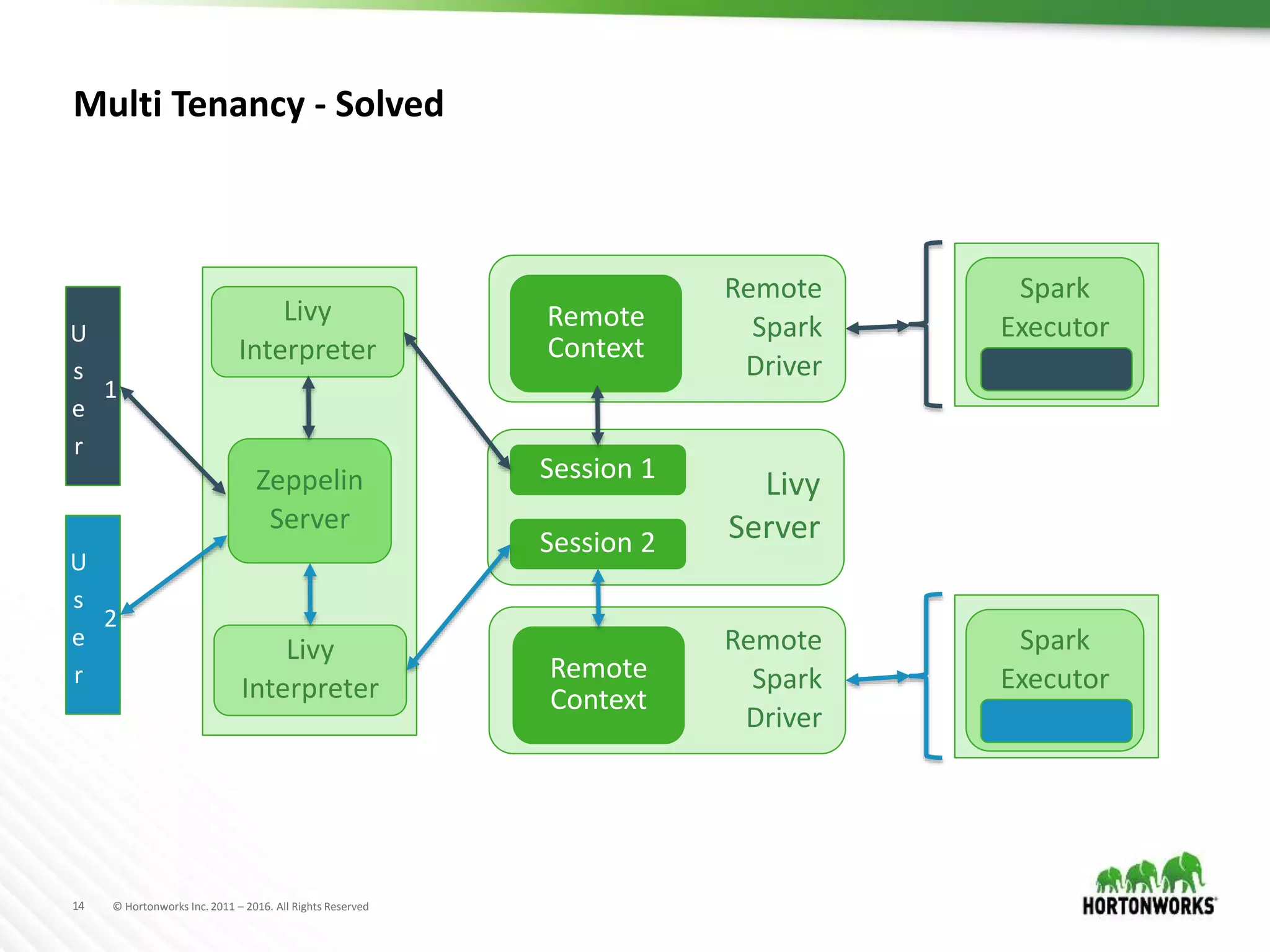





The document discusses the capabilities of Apache Zeppelin and Spark for data science in enterprises, highlighting its ease of use with zero installation and support for multiple execution platforms and languages. It addresses current challenges such as secure data access and multi-tenancy, proposing solutions like the Livy server for session management. Future improvements are outlined, focusing on session management, better visualizations, and enhanced collaboration features.











































































