Download as PDF, PPTX






![PySpark Today
▪ Less Pythonic
▪ Deprecated Python built-in instance support when creating a DataFrame
>>> spark.createDataFrame([{'a': 1}])
/.../session.py:378: UserWarning: inferring schema from dict is deprecated, please use
pyspark.sql.Row instead](https://image.slidesharecdn.com/145hyukjinkwon-201129185119/85/Project-Zen-Improving-Apache-Spark-for-Python-Users-8-320.jpg)







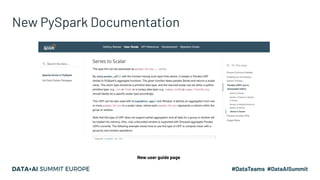



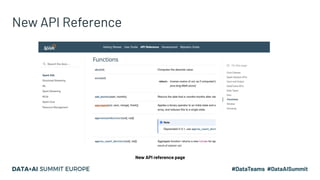
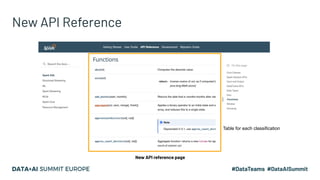


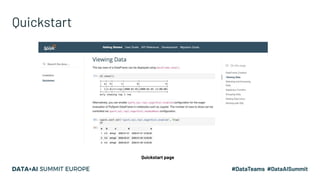
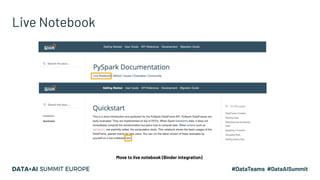
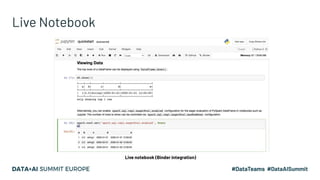





















Project Zen aims to enhance Apache Spark for Python users by addressing documentation challenges, improving IDE support, and facilitating better type hinting. The initiative seeks to make PySpark more Pythonic and user-friendly through redesigned documentation, clearer exception handling, and a streamlined installation process via PyPI. Future efforts will focus on enhanced interoperability with other Python libraries, improved readability, and standardization of warnings and exceptions.