Download as PDF, PPTX









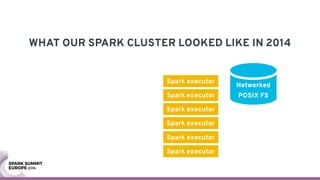
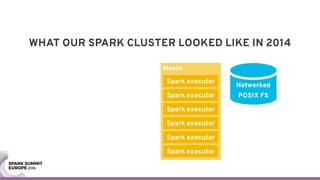

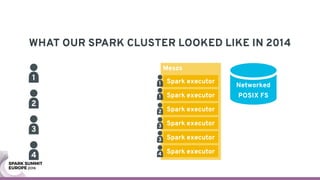
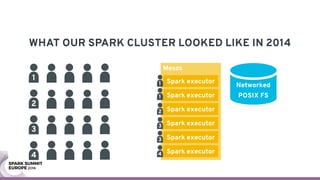
















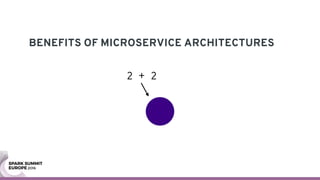
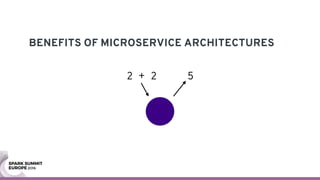






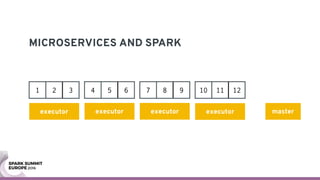
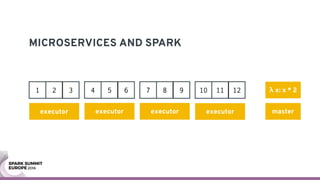

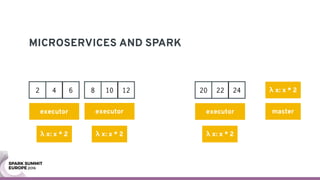
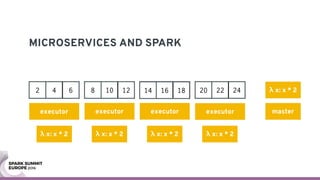

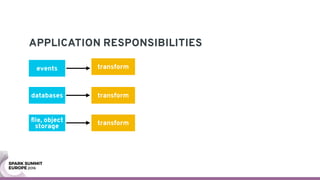
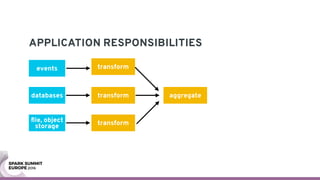
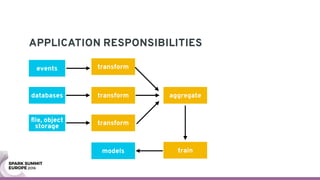

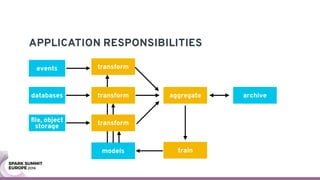

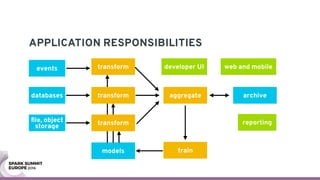
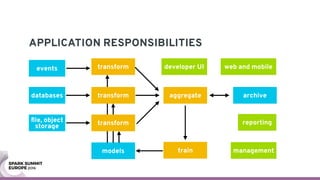



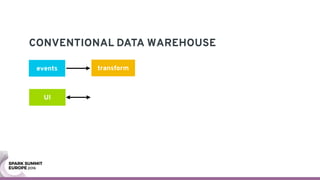

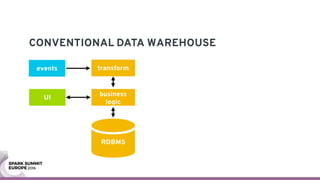
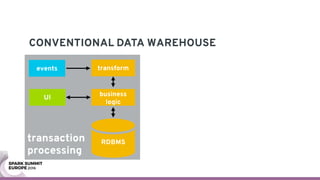
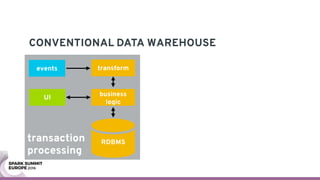
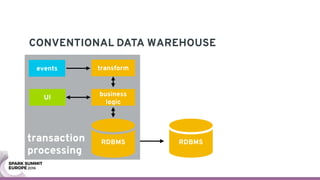
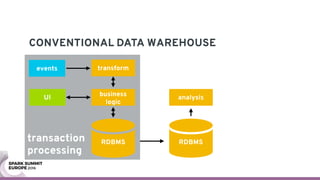
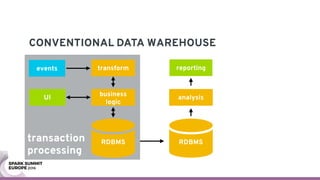
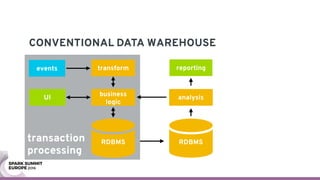
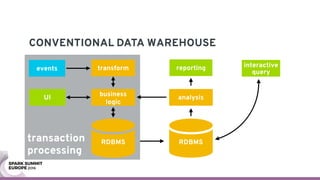
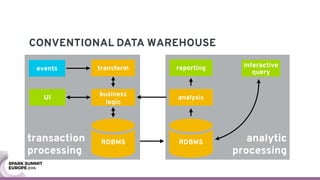
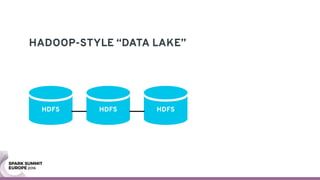
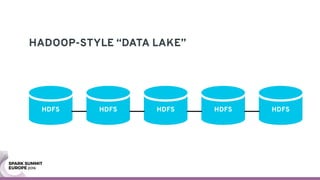
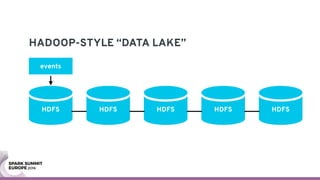

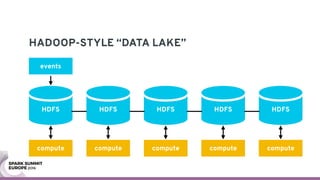

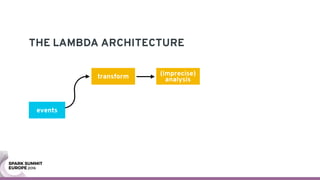
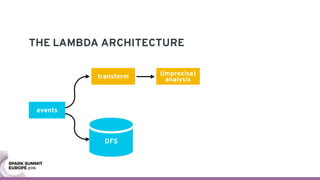
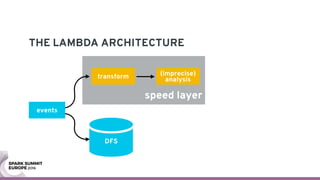
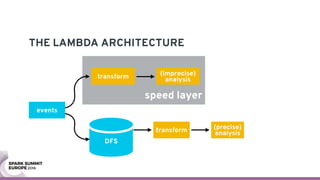
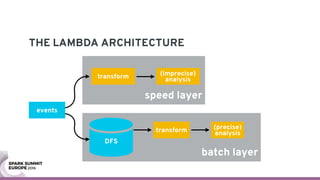

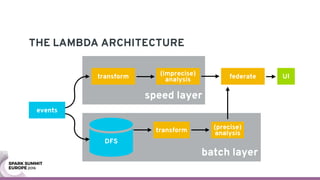
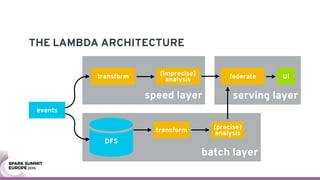

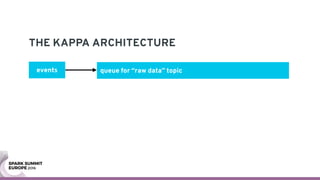

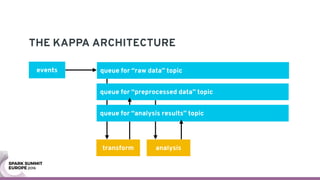
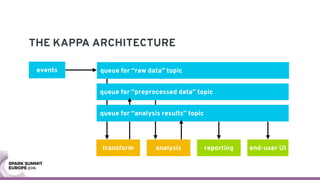


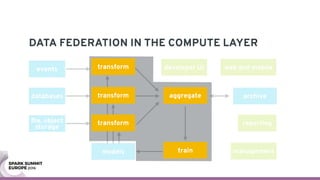
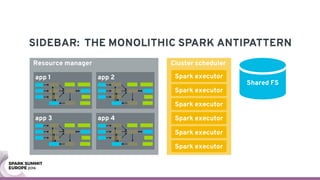


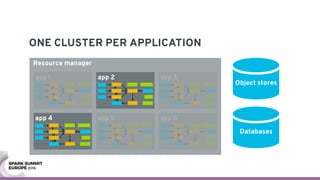

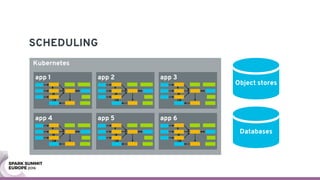
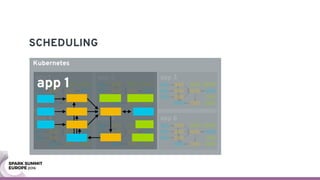
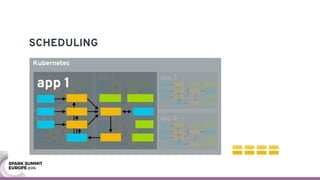
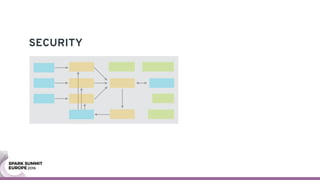
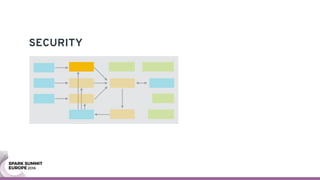
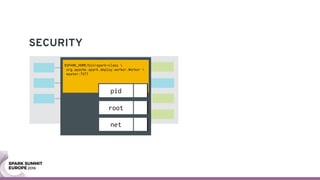
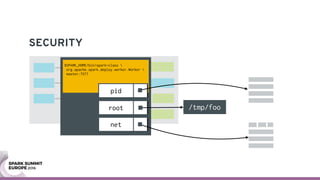
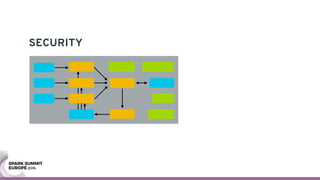
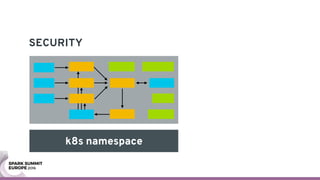
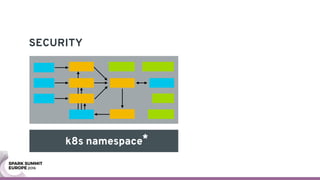
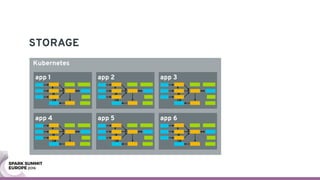
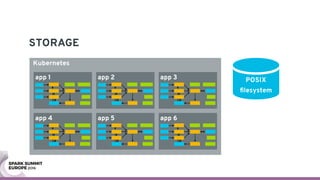
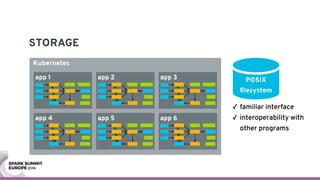
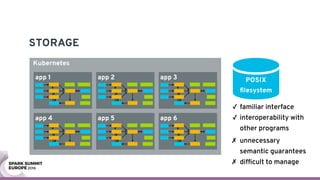
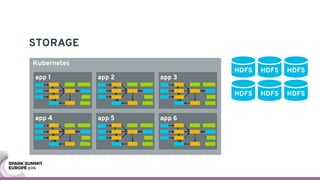
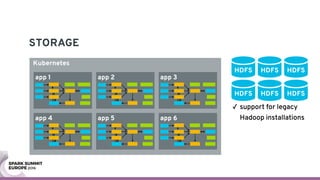
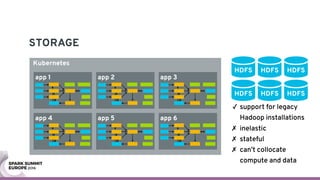
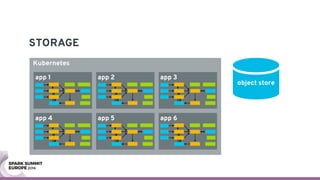
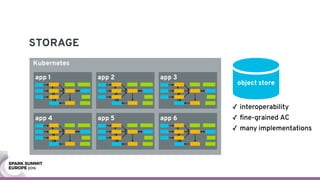
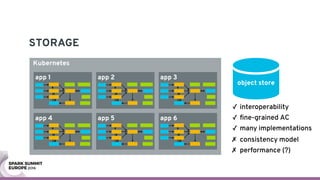
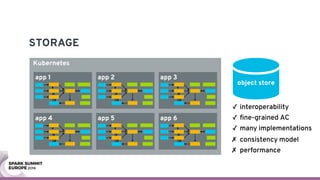

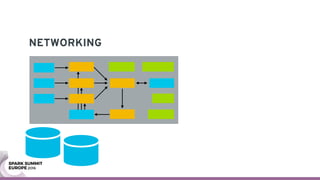
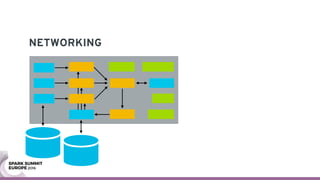
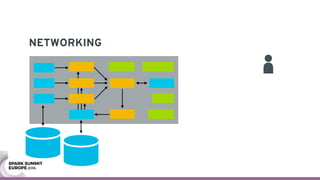
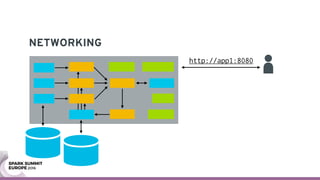
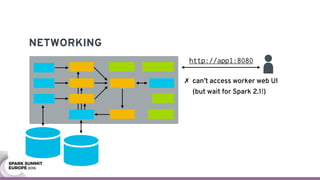

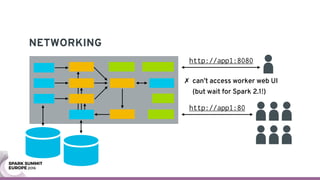





The document discusses containerizing Spark clusters on Kubernetes. It describes how the author's Spark cluster looked in 2014 running on Mesos with networked storage. It then covers motivations for microservices architectures and how Spark fits into this. The document outlines architectures for analytics and applications, including responsibilities like transformation, aggregation, training models, and more. It also discusses legacy architectures like data warehouses and Hadoop-style data lakes. Finally, it covers practical considerations and potential pitfalls of containerized Spark clusters like scheduling, security, and storage options.
























































































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)


















