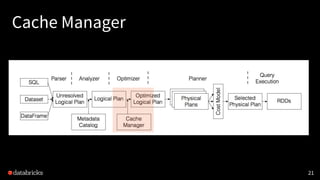
Deep Dive into Spark SQL with Advanced Performance Tuning
1.
Deep Dive Into
TakuyaUESHIN
Hadoop / Spark Conference 2019, Mar 2019
1
SQL
with Advanced Performance Tuning
2.
2
About Me
- SoftwareEngineer @databricks
- Apache Spark Committer
- Twitter: @ueshin
- GitHub: github.com/ueshin
3.
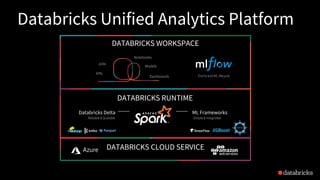
DATABRICKS WORKSPACE
Databricks DeltaML Frameworks
DATABRICKS CLOUD SERVICE
DATABRICKS RUNTIME
Reliable & Scalable Simple & Integrated
Databricks Unified Analytics Platform
APIs
Jobs
Models
Notebooks
Dashboards End to end ML lifecycle
4.
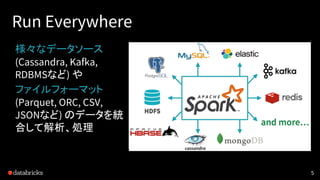
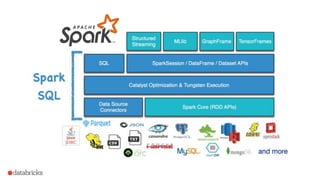
Spark SQL
A highlyscalable and efficient relational
processing engine with ease-to-use APIs and
mid-query fault tolerance.
4
Not Only SQL
Sparkアプリケーション、ライブラリもSparkSQLをベー
スにしている
• Structured streaming: ストリーム処理
• MLlib: 機械学習
• GraphFrame: グラフ計算
• Your own Spark applications: using SQL,
DataFrame and Dataset APIs
8
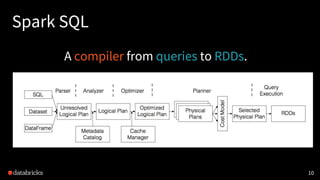
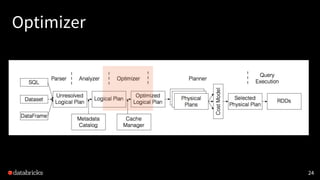
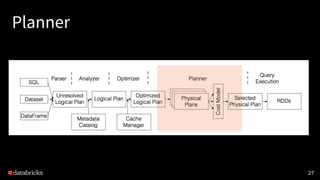
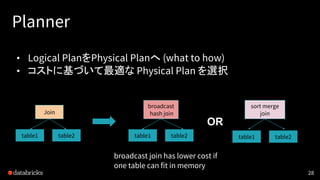
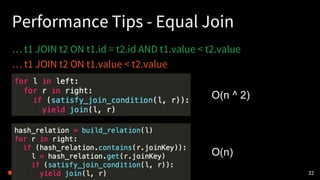
Planner
• Logical PlanをPhysicalPlanへ (what to how)
• コストに基づいて最適な Physical Plan を選択
28
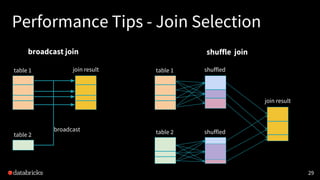
table1 table2
Join
broadcast
hash join
sort merge
join
OR
broadcast join has lower cost if
one table can fit in memory
table1 table2 table1 table2
Apache Spark™
• UseCases
• Research
• Technical Deep Dives
AI
• Productionizing ML
• Deep Learning
• Cloud Hardware
Fields
• Data Science
• Data Engineering
• Enterprise
5000+ ATTENDEES
Practitioners:
Data Scientists, Data Engineers,
Analysts, Architects
Leaders:
Engineering Management, VPs,
Heads of Analytics & Data, CxOs
TRACKS
databricks.com/sparkaisummit
43.
43
Nike: Enabling DataScientists to bring their Models to Market
Facebook: Vectorized Query Execution in Apache Spark at Facebook
Tencent: Large-scale Malicious Domain Detection with Spark AI
IBM: In-memory storage Evolution in Apache Spark
Capital One: Apache Spark and Sights at Speed: Streaming, Feature
management and Execution
Apple: Making Nested Columns as First Citizen in Apache Spark SQL
EBay: Managing Apache Spark workload and automatic optimizing.
Google: Validating Spark ML Jobs
HP: Apache Spark for Cyber Security in big company
Microsoft: Apache Spark Serving: Unifying Batch, Streaming and
RESTful Serving
ABSA Group: A Mainframe Data Source for Spark SQL and Streaming
Facebook: an efficient Facebook-scale shuffle service
IBM: Make your PySpark Data Fly with Arrow!
Facebook : Distributed Scheduling Framework for Apache Spark
Zynga: Automating Predictive Modeling at Zynga with PySpark
World Bank: Using Crowdsourced Images to Create Image Recognition
Models and NLP to Augment Global Trade indicator
JD.com: Optimizing Performance and Computing Resource.
Microsoft: Azure Databricks with R: Deep Dive
ICL: Cooperative Task Execution for Apache Spark
Airbnb: Apache Spark at Airbnb
Netflix: Migrating to Apache Spark at Netflix
Microsoft: Infrastructure for Deep Learning in
Apache Spark
Intel: Game playing using AI on Apache Spark
Facebook: Scaling Apache Spark @ Facebook
Lyft: Scaling Apache Spark on K8S at Lyft
Uber: Using Spark Mllib Models in a Production
Training and Serving Platform
Apple: Bridging the gap between Datasets and
DataFrames
Salesforce: The Rule of 10,000 Spark Jobs
Target: Lessons in Linear Algebra at Scale with
Apache Spark
Workday: Lesson Learned Using Apache Spark








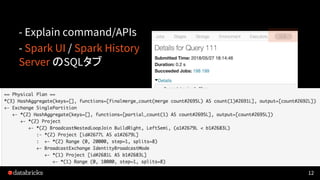
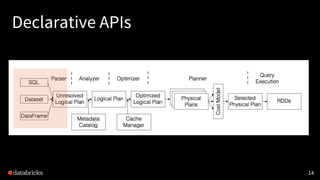

![Declarative APIs
16
SQL, DataFrame, Datasetの違い
• DataFrame API は untyped リレーショナル処理
• Dataset API は typed バージョン, ただし処理内容によっては
パフォーマンスペナルティがある
[SPARK-14083]
• http://dbricks.co/29xYnqR](https://image.slidesharecdn.com/2019-190314150127/85/Deep-Dive-into-Spark-SQL-with-Advanced-Performance-Tuning-16-320.jpg)
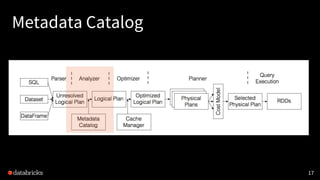
![Metadata Catalog
• Persistent Hive metastore [Hive 0.12 - Hive 2.3.3]
• Session-local temporary view manager
• Cross-session global temporary view manager
• Session-local function registry
18](https://image.slidesharecdn.com/2019-190314150127/85/Deep-Dive-into-Spark-SQL-with-Advanced-Performance-Tuning-18-320.jpg)

![Performance Tips - Catalog
Partition metadata 取得のコスト:
- Hive metastore のアップグレード
- Cardinality の高いパーティションカラムを避ける
- Partition pruning predicates (improved in [SPARK-20331])
20](https://image.slidesharecdn.com/2019-190314150127/85/Deep-Dive-into-Spark-SQL-with-Advanced-Performance-Tuning-20-320.jpg)



![Performance Tips - Optimizer
独自の Optimizer や Planner Rule の組み込み
• SparkSessionExtensions
• ExperimentalMethodsクラス
• var extraOptimizations: Seq[Rule[LogicalPlan]] = Nil
• var extraStrategies: Seq[Strategy] = Nil
• Examples in the Herman’s talk Deep Dive into Catalyst
Optimizer
• Join two intervals: http://dbricks.co/2etjIDY
26](https://image.slidesharecdn.com/2019-190314150127/85/Deep-Dive-into-Spark-SQL-with-Advanced-Performance-Tuning-26-320.jpg)















![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)














![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=640&height=640&fit=bounds)









![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)






















