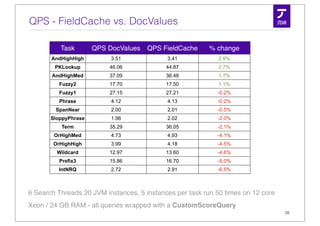
Downloaded 56 times





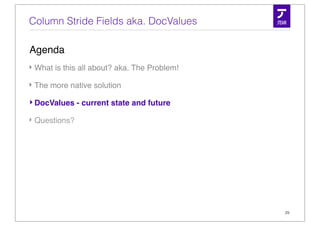
![Stored Fields under the hood
Document
title: title:
id: 108232
Deutschland Germany
absolute file pointers
[...][...][93438][...]
Field Index (.fdx)
[...][id:108232title:Deutschlandtitle:Germany][...]
Field Data (.fdt)
numFields(vint) [ fieldid(vint) length(vint) payload ]
8](https://image.slidesharecdn.com/simonwillanuerlucenerevolution2011-110609235251-phpapp01/85/Column-Stride-Fields-aka-DocValues-8-320.jpg)
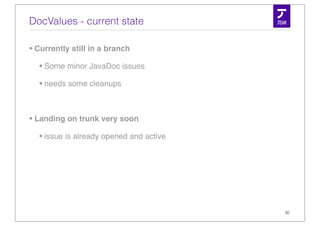
![Stored Fields - accessing a field
1 Lookup filepointer in .fdx
[...][...][93438][...]
Field Index (.fdx)
2 Scan on .fdt until you find the field by ID
[...][id:108232title:Deutschlandtitle:Germany][...]
Field Data (.fdt)
numFields(vint) [ fieldid(vint) length(vint) payload ]
9](https://image.slidesharecdn.com/simonwillanuerlucenerevolution2011-110609235251-phpapp01/85/Column-Stride-Fields-aka-DocValues-9-320.jpg)
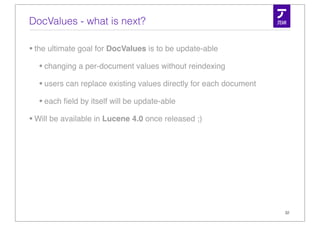
![Alternatives?
Lucene can un-invert a field into FieldCache
un-invert
weight term freq Posting list
5.8
1.0 1 16
1.0
2.7 1 23
2.7
parse
2.7 3.2 1 7
4.3 convert to datatype 4.3 1 4
7.9
4.7 1 8
1.0
3.2 5.8 1 0
4.7
7.9 1 59
7.9
array per field / 9.0 1 10
9.0 segment
float 32 string / byte[] 10](https://image.slidesharecdn.com/simonwillanuerlucenerevolution2011-110609235251-phpapp01/85/Column-Stride-Fields-aka-DocValues-10-320.jpg)

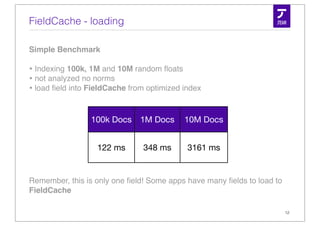
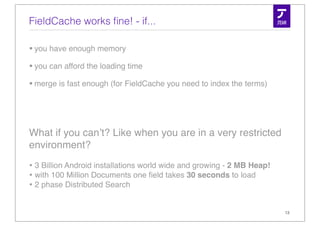

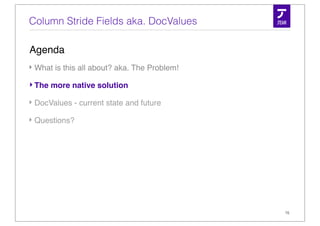
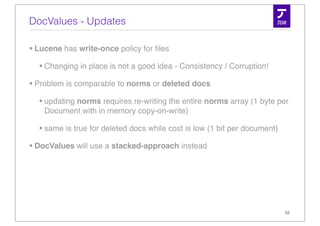
![The more native solution - Column Stride Fields
• A dense column based storage
• 1 value per document
• accepts primitives - no conversion from / to String
• int & long
• float & double
• byte[ ]
• each field has a DocValues Type but can still be indexed or stored
• Entirely optional
16](https://image.slidesharecdn.com/simonwillanuerlucenerevolution2011-110609235251-phpapp01/85/Column-Stride-Fields-aka-DocValues-16-320.jpg)
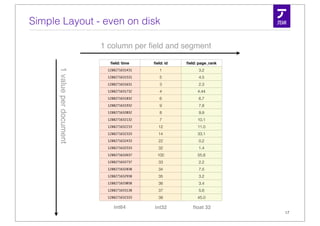
![Numeric Types - Int
Number of bit depend on the numeric
range in the field: field: id
7 - bit per doc 1
5
3
Math.max(1, (int) Math.ceil(
Math.log(1+maxValue)/Math.log(2.0)) 4
);
6
9
Random Access
8
7
12
14
• Integer are stored dense based on PackedInts 22
32
• Space depends on the value-range per segment 100
33
Example: [1, 100] maps to [0, 99] requires 7 bit per doc 34
35
36
• Floats are stored without compression 37
38
• either 32 or 64 bit per value
18](https://image.slidesharecdn.com/simonwillanuerlucenerevolution2011-110609235251-phpapp01/85/Column-Stride-Fields-aka-DocValues-18-320.jpg)
![Arbitrary Values - The byte[] variants
• Length Variants:
• Fixed / Variable
• Store Variants:
• Straight or Referenced
fixed / straight fixed / deref
data offsets data
10/01/2011 0 10/01/2011
12/01/2011 10 12/01/2011
Random Access
Random Access
10/04/2011 20 10/04/2011
10/06/2011 30
10/06/2011
10/05/2011 40
10/05/2011
10/01/2011 50
10/01/2011
10/07/2011 60
10/07/2011
10/04/2011 20
10/04/2011 20
10/04/2011 20 19](https://image.slidesharecdn.com/simonwillanuerlucenerevolution2011-110609235251-phpapp01/85/Column-Stride-Fields-aka-DocValues-19-320.jpg)

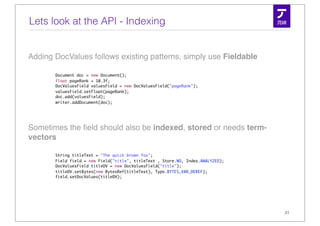
![Looking at the API - Search / Retrieve
On disk sequential access is exposed through DocValuesEnum
IndexReader reader = ...;
DocValues values = reader.docValues("pageRank");
DocValuesEnum floatEnum = values.getEnum();
int doc = 0;
FloatsRef ref = floatEnum.getFloat(); // values are filled when iterating
while((doc = floatEnum.nextDoc()) != DocValuesEnum.NO_MORE_DOCS) {
double value = ref.floats[0];
}
// equivalent to ...
int doc = 0;
while((doc = floatEnum.advance(doc+1)) != DocValuesEnum.NO_MORE_DOCS) {
double value = ref.floats[0];
}
DocValuesEnum is based on DocIdSetIterator just like Scorer or
DocsEnum
22](https://image.slidesharecdn.com/simonwillanuerlucenerevolution2011-110609235251-phpapp01/85/Column-Stride-Fields-aka-DocValues-22-320.jpg)
![Looking at the API - Search / Retrieve
RAM Resident API is very similar to FieldCache
IndexReader reader = ...;
DocValues values = reader.docValues("pageRank");
Source source = values.getSource();
double value = source.getFloat(x);
// still allows iterating over the RAM resident values
DocValuesEnum floatEnum = source.getEnum();
int doc;
FloatsRef ref = floatEnum.getFloat();
while((doc = floatEnum.nextDoc()) != DocValuesEnum.NO_MORE_DOCS) {
value = ref.floats[0];
}
DocValuesEnum still available on RAM Resident API
23](https://image.slidesharecdn.com/simonwillanuerlucenerevolution2011-110609235251-phpapp01/85/Column-Stride-Fields-aka-DocValues-23-320.jpg)




The document discusses column stride fields, also known as docvalues, as a solution for efficiently storing and accessing per-document values in Apache Lucene. It compares current storage methods like stored fields and fieldcache, highlighting the advantages of docvalues, including faster loading times and better memory efficiency. Future developments aim to make docvalues update-able without requiring full reindexing of documents.







































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



