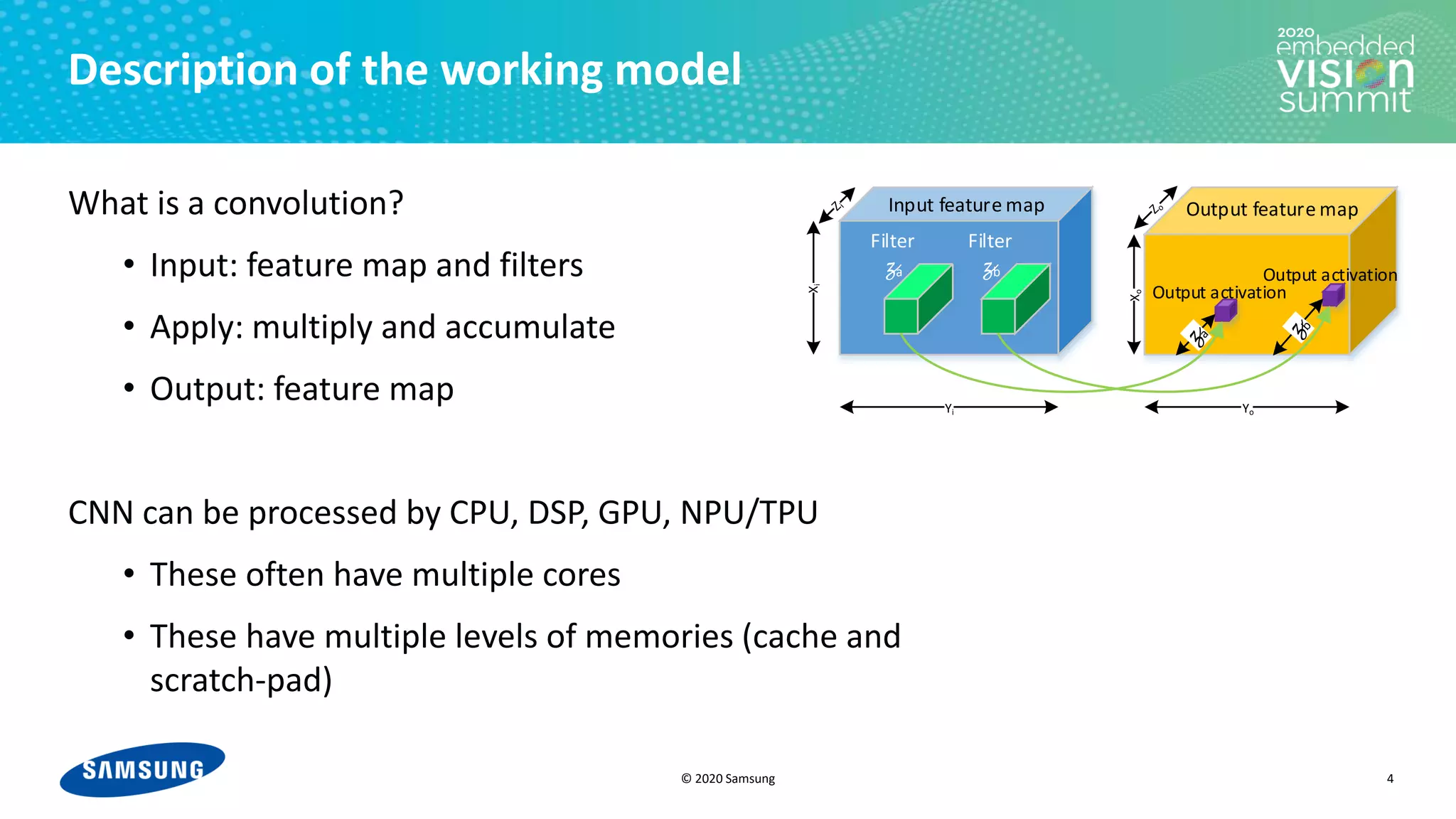
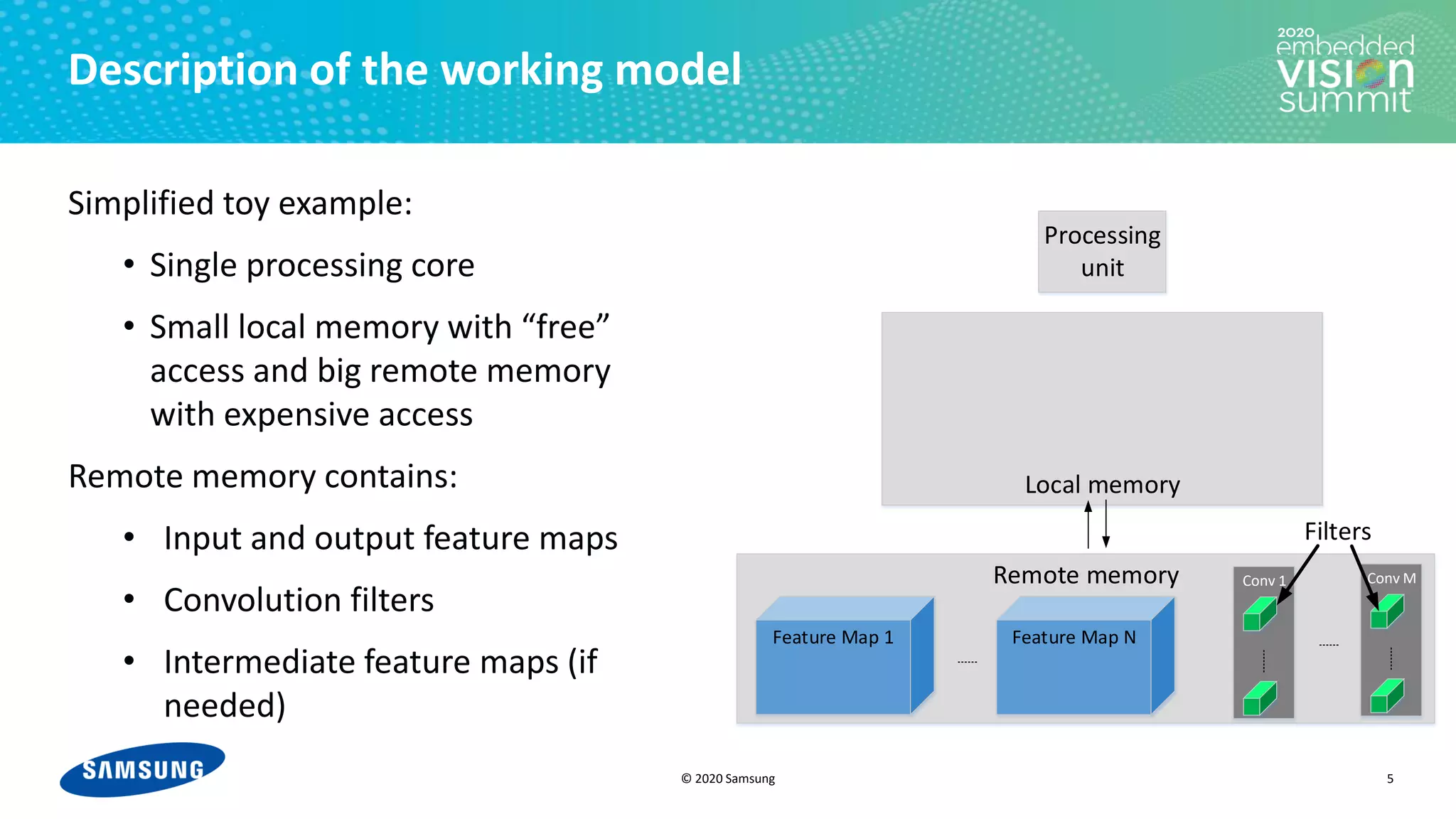
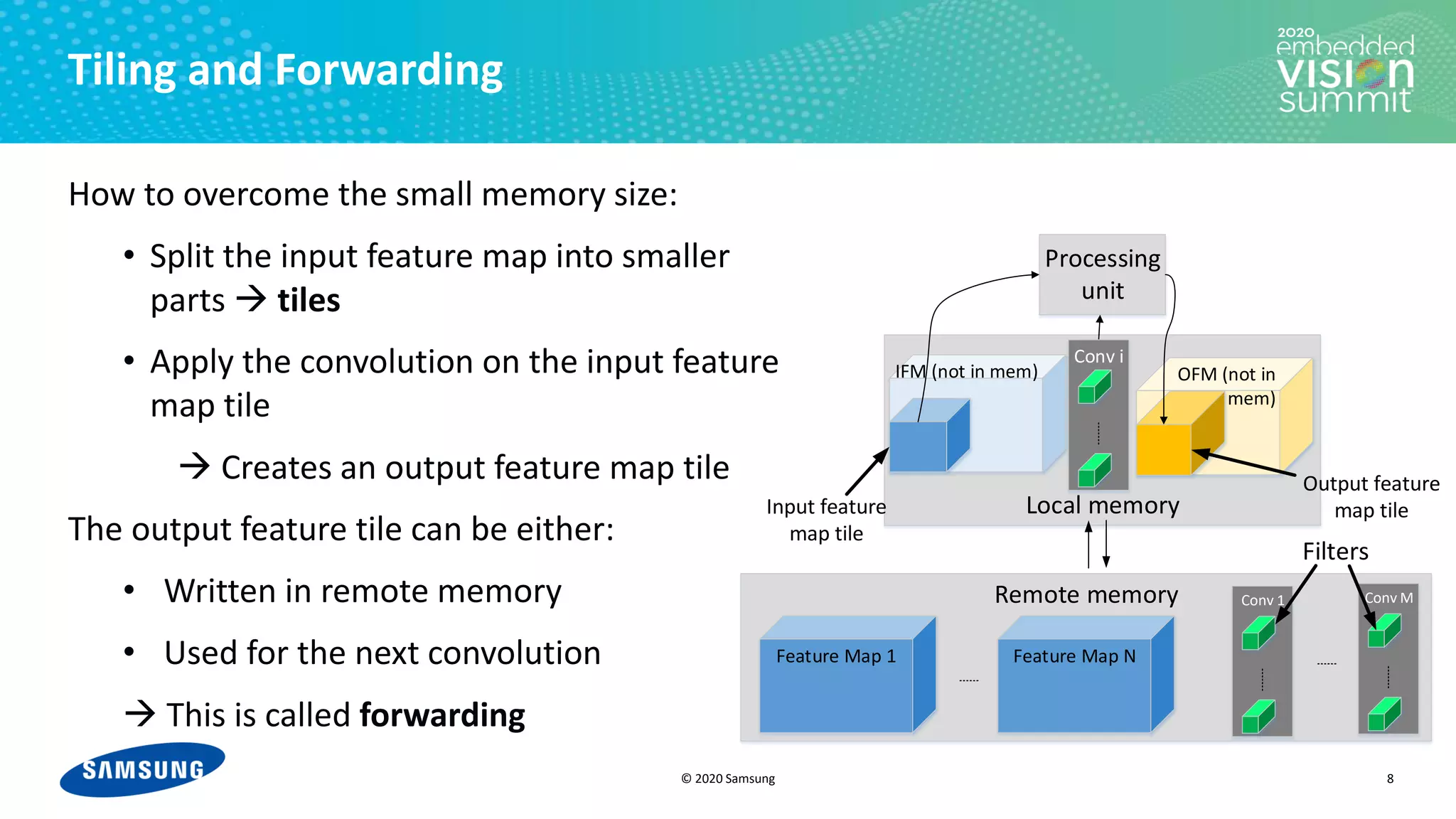
Download as PDF, PPTX



![© 2020 Samsung
Typical orders of magnitude for NPU
• The memory management problem
depends on the relative size of:
• The local memory of the processor
• The typical feature map of the
network
• Our working point:
Feature map size ~
10 * Local memory size
6
Local memory size [B]
Feature map size [B]
10k 100k 1M 10M
10k
100k
1M
10M
100M
IoT
Mobile
Automotive](https://image.slidesharecdn.com/levysamsung2020embeddedvisionsummitslidesfinal-210205200710/75/Improving-Power-Efficiency-for-Edge-Inferencing-with-Memory-Management-Optimizations-a-Presentation-from-Samsung-6-2048.jpg)


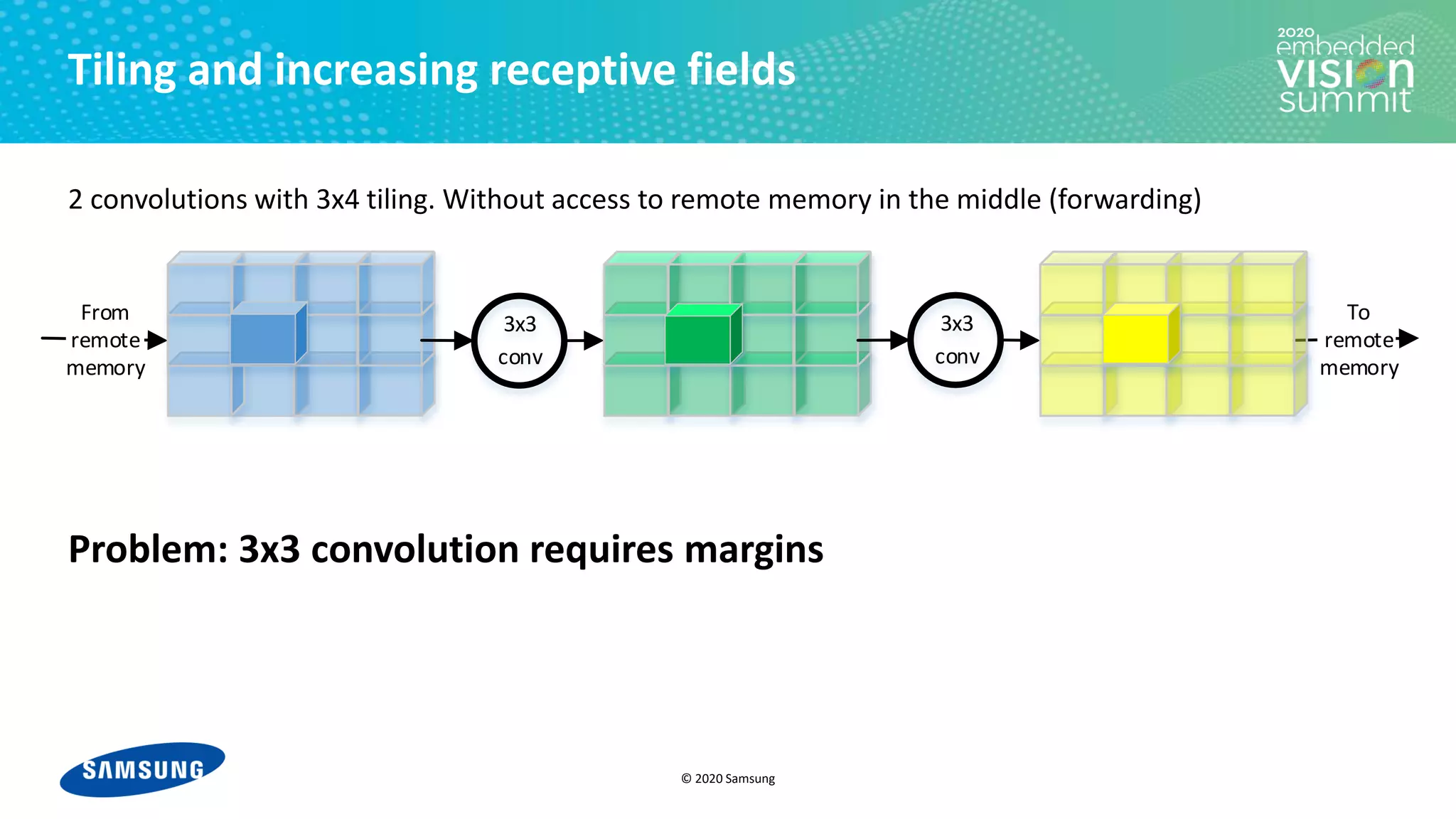
![© 2020 Samsung
3x3
conv
3x3
conv
From
remote
memory
To
remote
memory
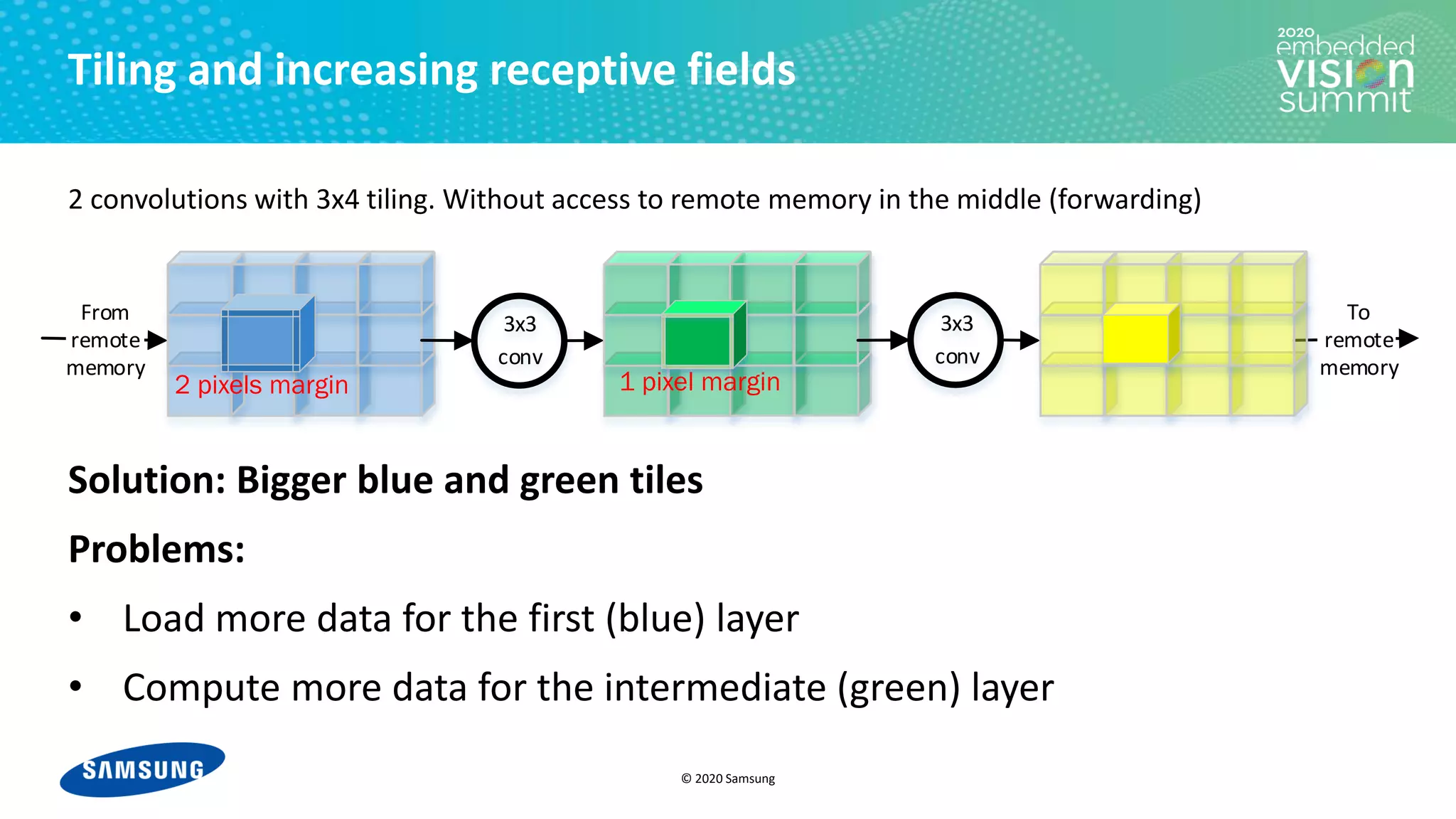
Tiling and increasing receptive fields
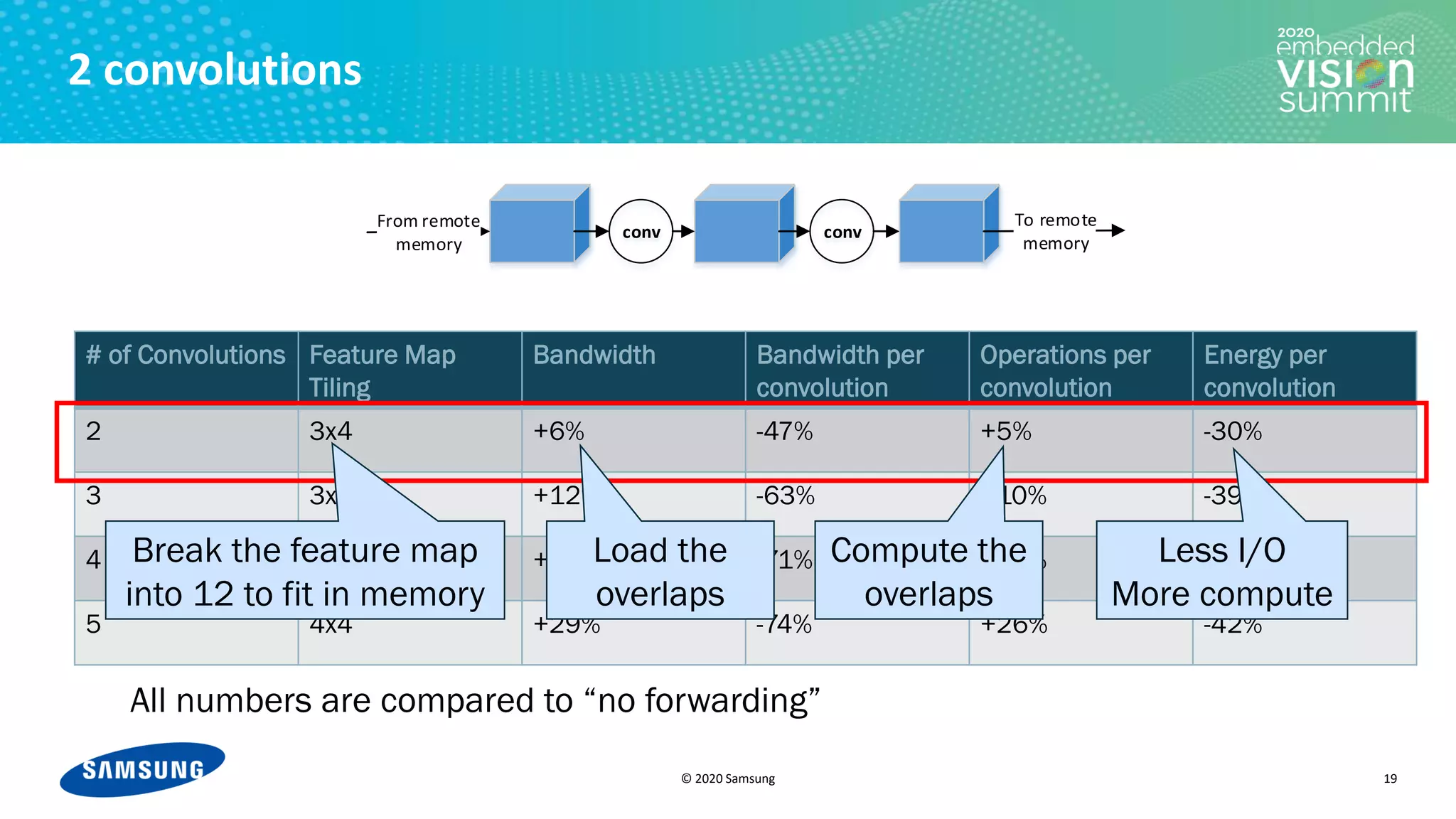
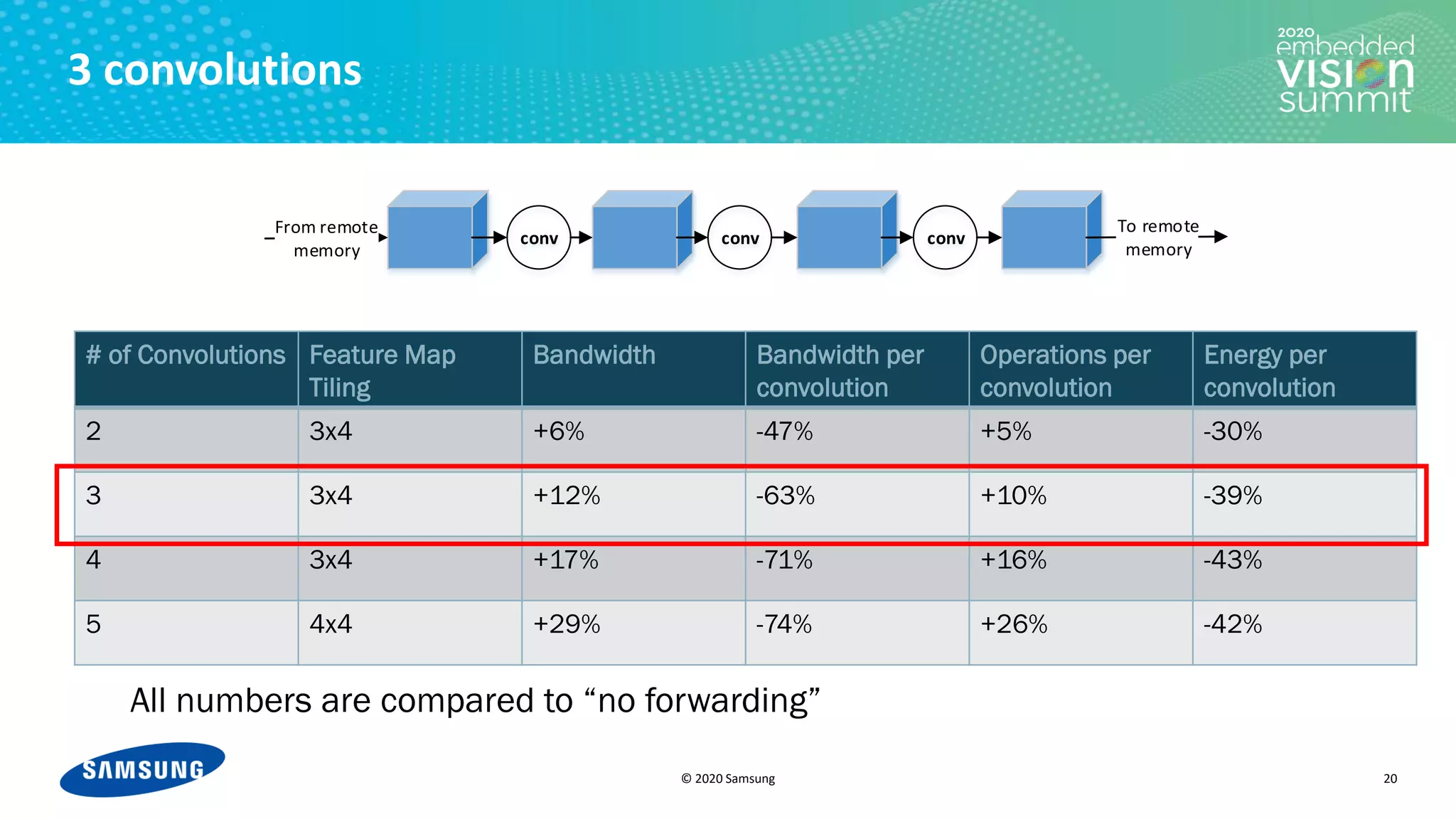
2 convolutions with 3x4 tiling. Without access to remote memory in the middle (forwarding)
For i in [1-12]:
• Load tile i of blue feature map from remote memory
• Run 1st convolution → tile i of green feature map
• Run 2nd convolution → tile i of yellow feature map
• Store tile i of yellow feature map to remote memory](https://image.slidesharecdn.com/levysamsung2020embeddedvisionsummitslidesfinal-210205200710/75/Improving-Power-Efficiency-for-Edge-Inferencing-with-Memory-Management-Optimizations-a-Presentation-from-Samsung-10-2048.jpg)
![© 2020 Samsung
Tiling and increasing receptive fields
2 convolutions with 3x4 tiling. Without access to remote memory in the middle (forwarding)
For i in [1-12]:
• Load tile i of blue feature map from remote memory
• Run 1st convolution → tile i of green feature map
• Run 2nd convolution → tile i of yellow feature map
• Store tile i of yellow feature map to remote memory
3x3
conv
3x3
conv
From
remote
memory
To
remote
memory](https://image.slidesharecdn.com/levysamsung2020embeddedvisionsummitslidesfinal-210205200710/75/Improving-Power-Efficiency-for-Edge-Inferencing-with-Memory-Management-Optimizations-a-Presentation-from-Samsung-11-2048.jpg)
![© 2020 Samsung
Tiling and increasing receptive fields
3x3
conv
3x3
conv
From
remote
memory
To
remote
memory
2 convolutions with 3x4 tiling. Without access to remote memory in the middle (forwarding)
For i in [1-12]:
• Load tile i of blue feature map from remote memory
• Run 1st convolution → tile i of green feature map
• Run 2nd convolution → tile i of yellow feature map
• Store tile i of yellow feature map to remote memory](https://image.slidesharecdn.com/levysamsung2020embeddedvisionsummitslidesfinal-210205200710/75/Improving-Power-Efficiency-for-Edge-Inferencing-with-Memory-Management-Optimizations-a-Presentation-from-Samsung-12-2048.jpg)
![© 2020 Samsung
3x3
conv
3x3
conv
From
remote
memory
To
remote
memory
Tiling and increasing receptive fields
2 convolutions with 3x4 tiling. Without access to remote memory in the middle (forwarding)
For i in [1-12]:
• Load tile i of blue feature map from remote memory
• Run 1st convolution → tile i of green feature map
• Run 2nd convolution → tile i of yellow feature map
• Store tile i of yellow feature map to remote memory](https://image.slidesharecdn.com/levysamsung2020embeddedvisionsummitslidesfinal-210205200710/75/Improving-Power-Efficiency-for-Edge-Inferencing-with-Memory-Management-Optimizations-a-Presentation-from-Samsung-13-2048.jpg)
![© 2020 Samsung
3x3
conv
3x3
conv
From
remote
memory
To
remote
memory
Tiling and increasing receptive fields
2 convolutions with 3x4 tiling. Without access to remote memory in the middle (forwarding)
For i in [1-12]:
• Load tile i of blue feature map from remote memory
• Run 1st convolution → tile i of green feature map
• Run 2nd convolution → tile i of yellow feature map
• Store tile i of yellow feature map to remote memory](https://image.slidesharecdn.com/levysamsung2020embeddedvisionsummitslidesfinal-210205200710/75/Improving-Power-Efficiency-for-Edge-Inferencing-with-Memory-Management-Optimizations-a-Presentation-from-Samsung-14-2048.jpg)
![© 2020 Samsung
3x3
conv
3x3
conv
From
remote
memory
To
remote
memory
Tiling and increasing receptive fields
2 convolutions with 3x4 tiling. Without access to remote memory in the middle (forwarding)
For i in [1-12]:
• Load tile i of blue feature map from remote memory
• Run 1st convolution → tile i of green feature map
• Run 2nd convolution → tile i of yellow feature map
• Store tile i of yellow feature map to remote memory](https://image.slidesharecdn.com/levysamsung2020embeddedvisionsummitslidesfinal-210205200710/75/Improving-Power-Efficiency-for-Edge-Inferencing-with-Memory-Management-Optimizations-a-Presentation-from-Samsung-15-2048.jpg)
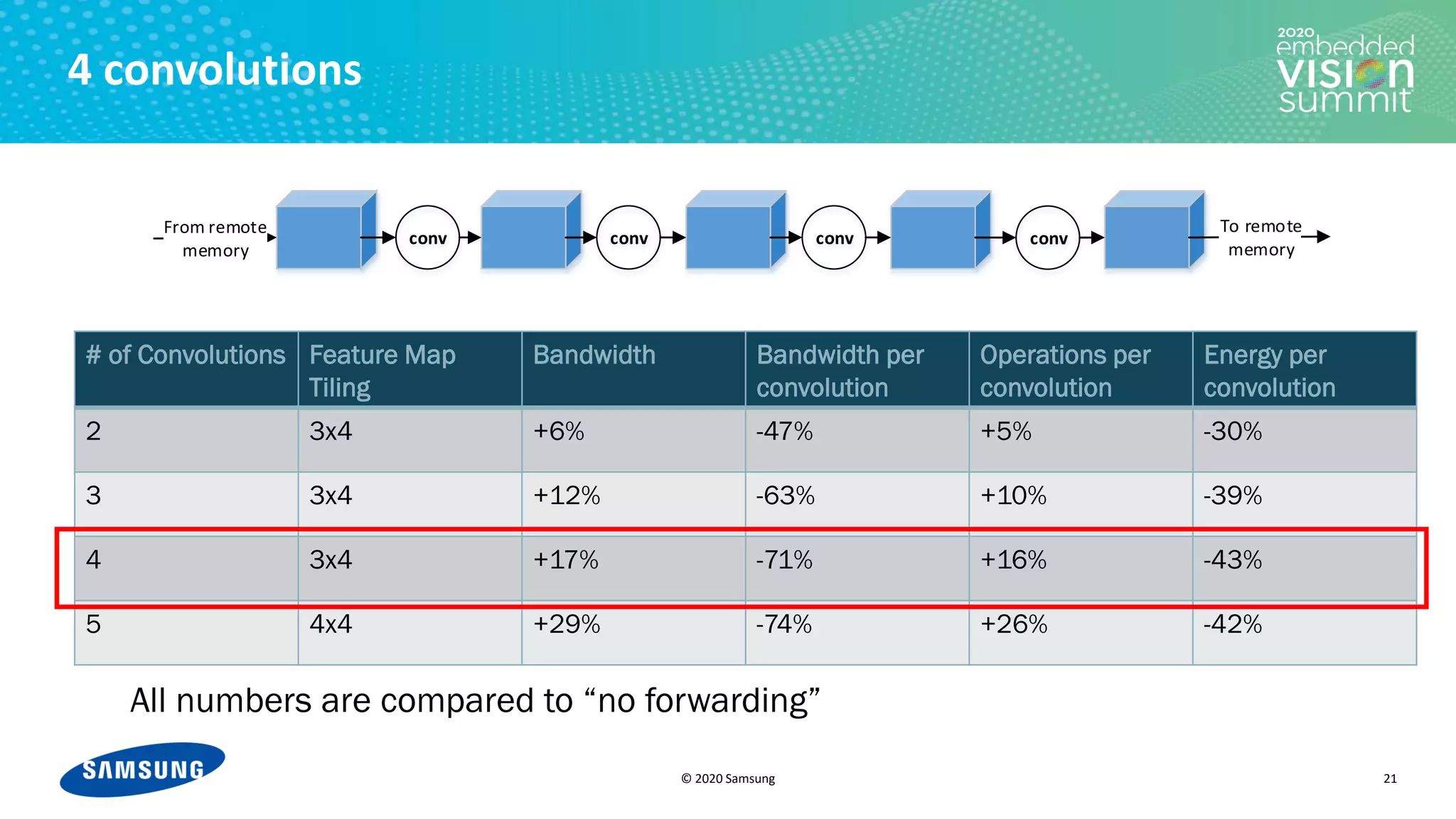
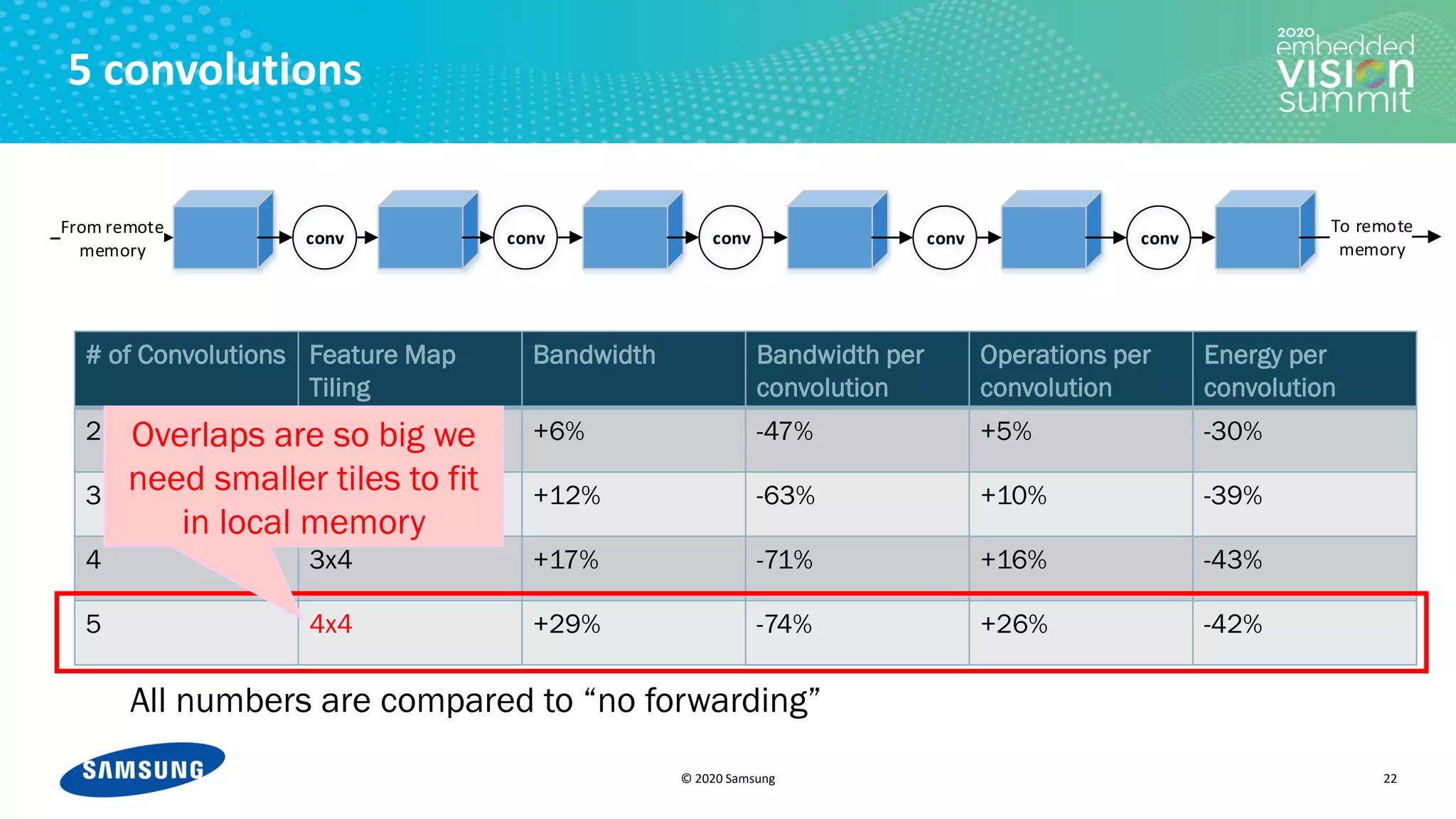
![© 2020 Samsung
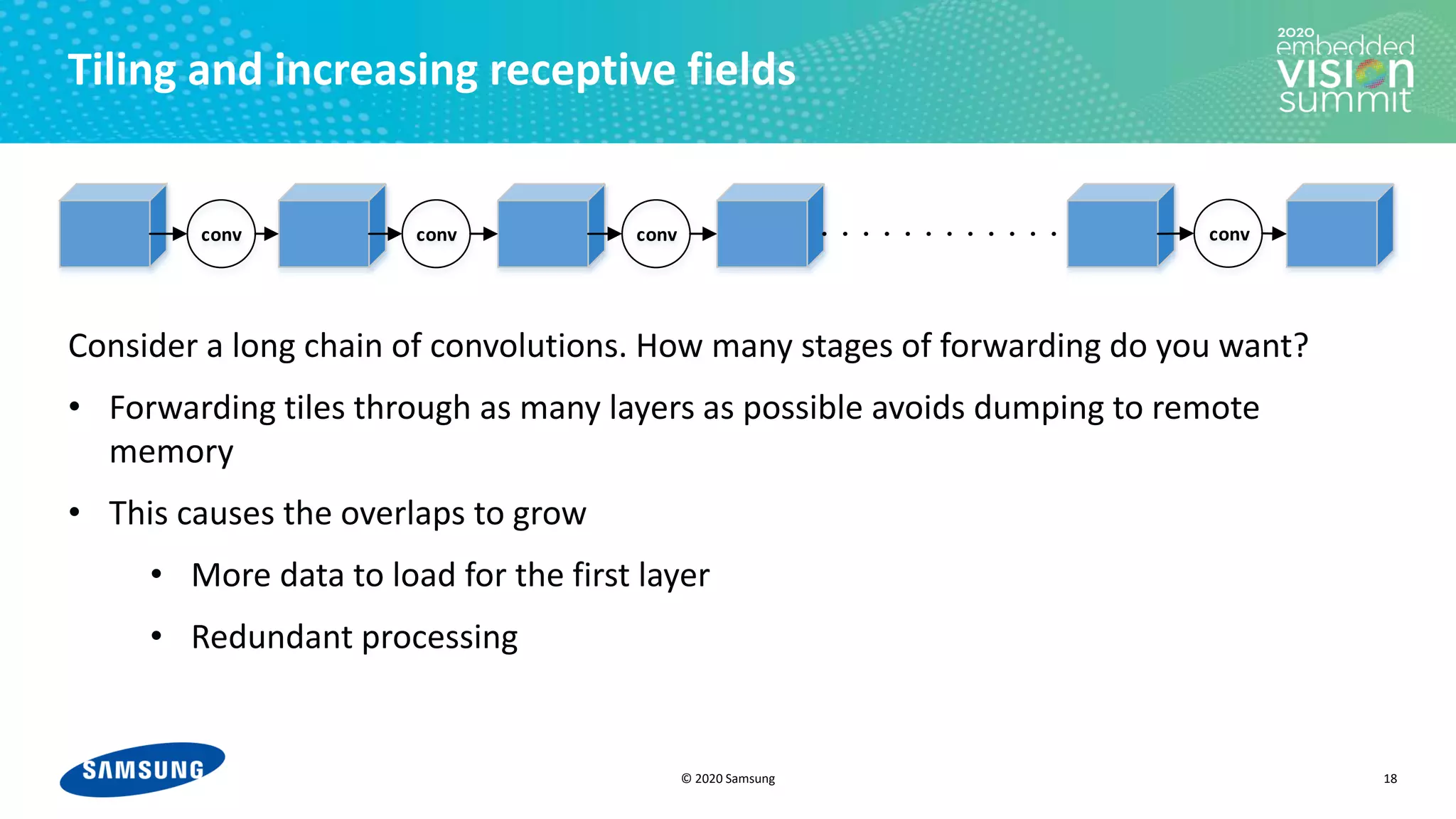
Tiling and increasing receptive fields
23
Minimal energy
Energy
[J]
• The trade-off between I/O and compute
power leads to a U-shaped behavior
• The trade-off requires an optimization
mechanism in the compiler
• In our toy example, all the convolutions
are identical
• In a real CNN, the convolutions are
different, so the optimization problem is
not one-dimensional
Number of convolutions](https://image.slidesharecdn.com/levysamsung2020embeddedvisionsummitslidesfinal-210205200710/75/Improving-Power-Efficiency-for-Edge-Inferencing-with-Memory-Management-Optimizations-a-Presentation-from-Samsung-23-2048.jpg)
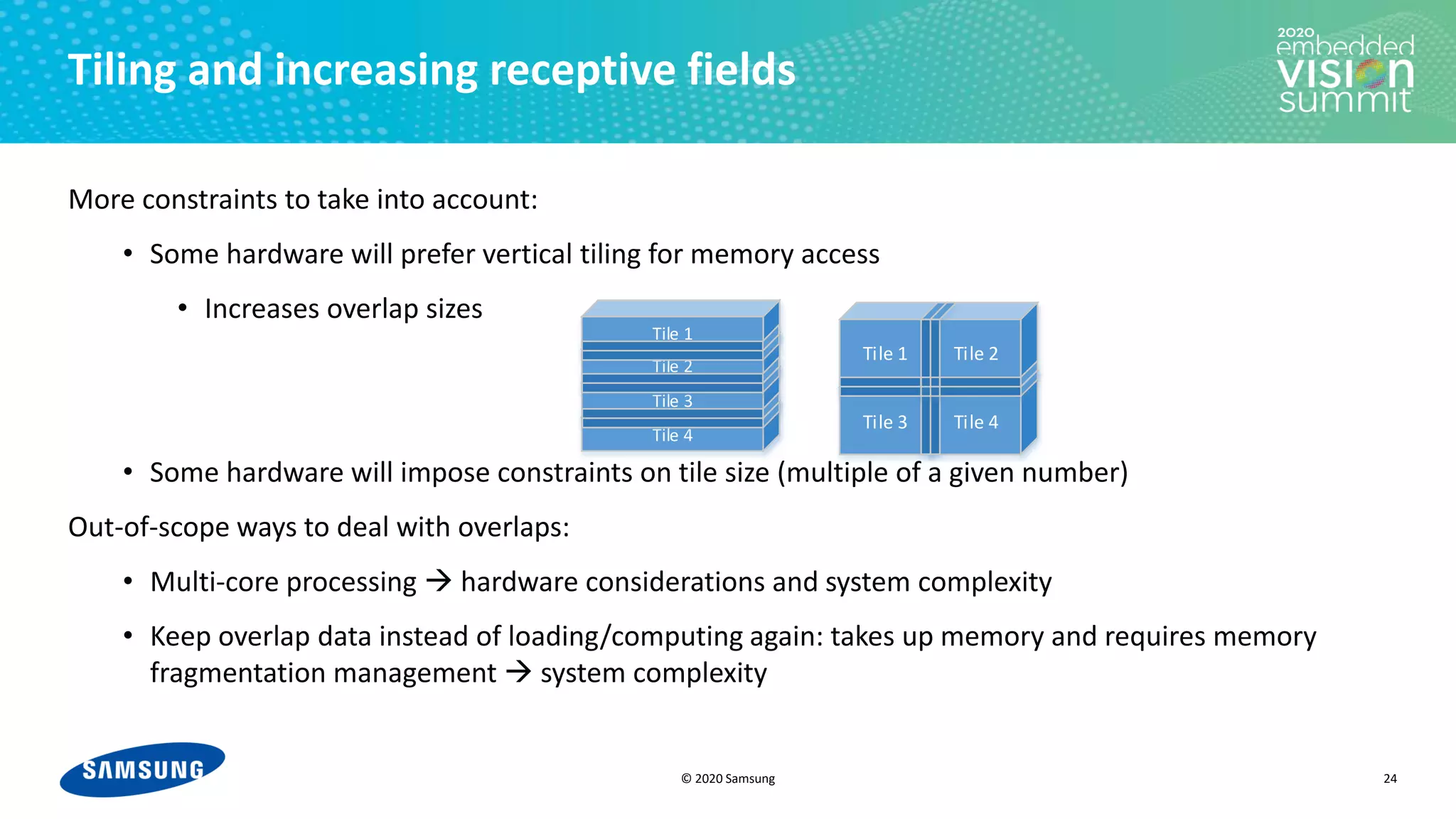


![© 2020 Samsung
Filters management
• No single strategy is the best all the time
• Choosing the right strategy can save up to
20% energy
• In practice, the problem is even more
complicated due to different convolutions
through the network
• The compiler should take the decision to
keep/reload the filters for each
convolution independently
27
0 100 200 300 400 500
Memory size [kB]
Energy
[J]
Local Memory Size [kB]](https://image.slidesharecdn.com/levysamsung2020embeddedvisionsummitslidesfinal-210205200710/75/Improving-Power-Efficiency-for-Edge-Inferencing-with-Memory-Management-Optimizations-a-Presentation-from-Samsung-27-2048.jpg)

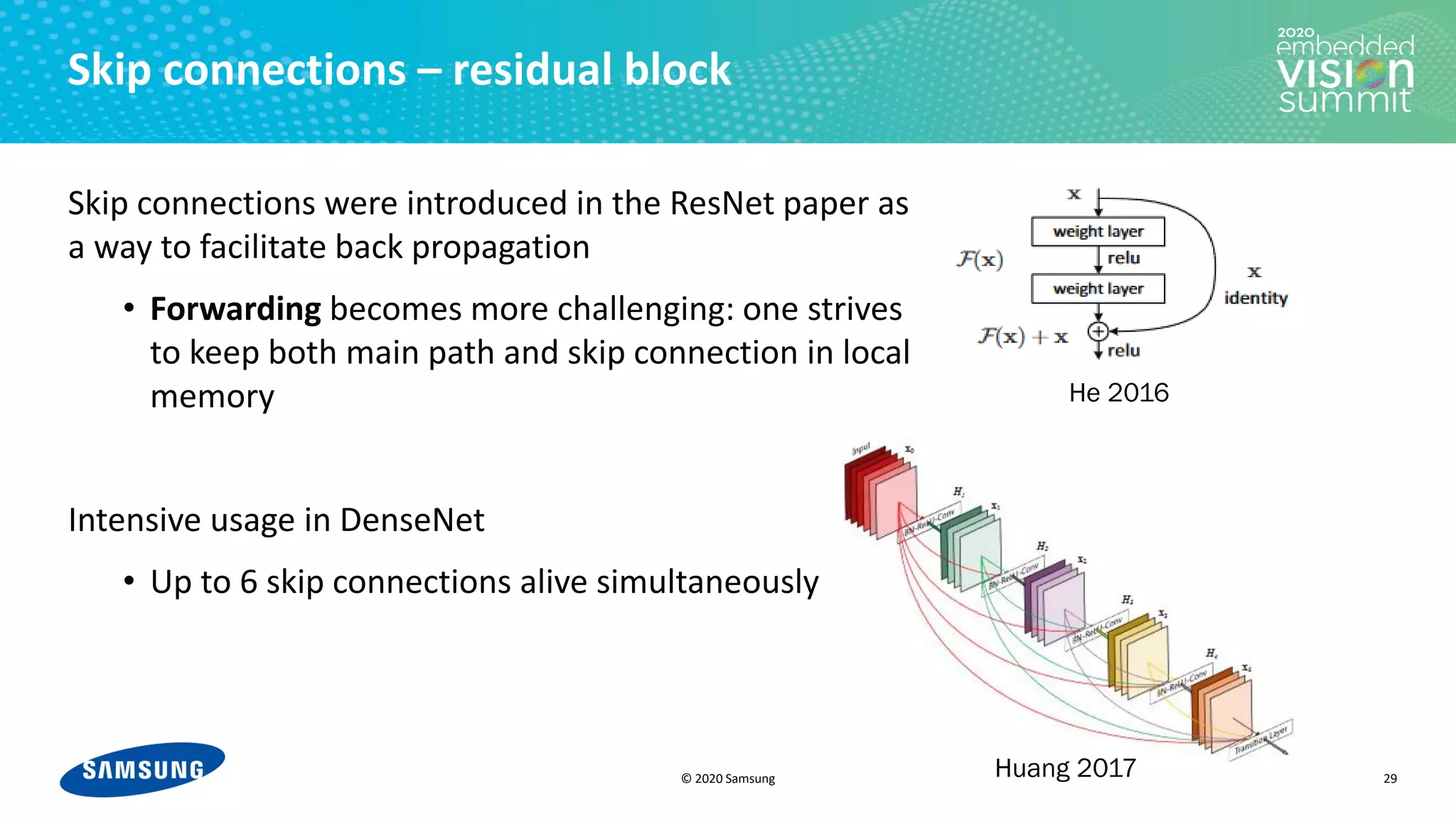
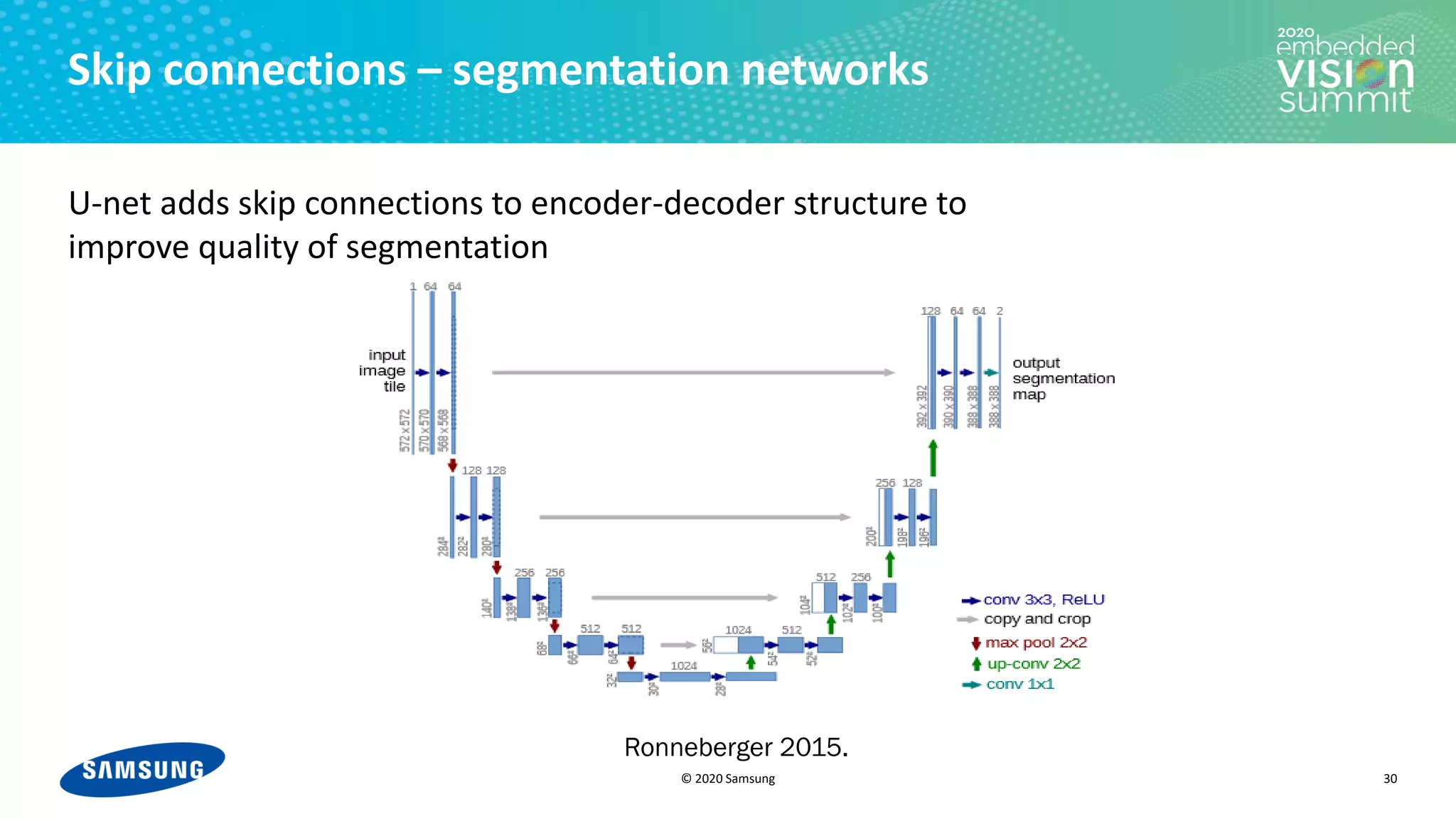
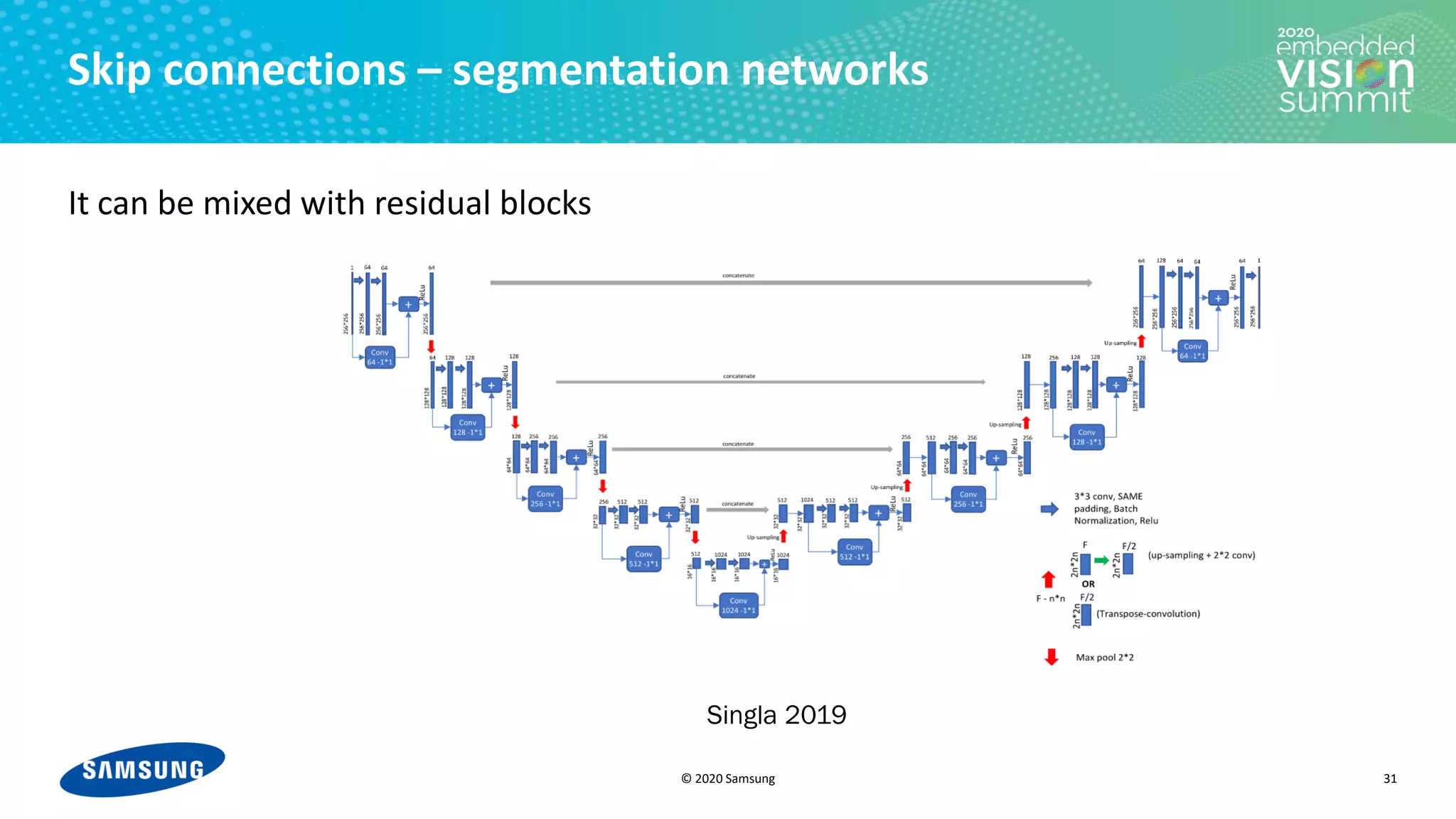
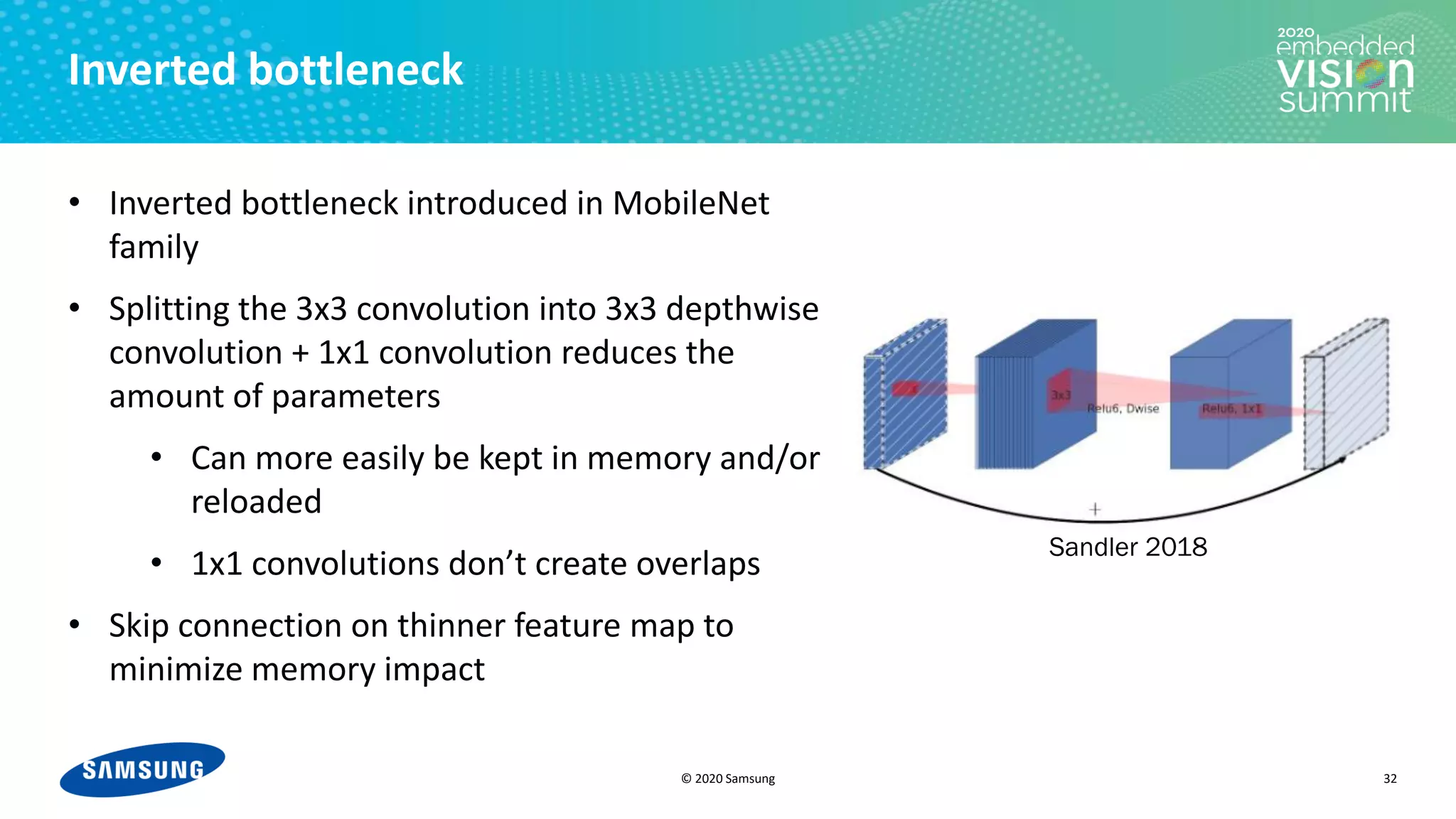




The document discusses optimizing power efficiency for edge inferencing in convolutional neural networks (CNNs) through improved memory management techniques. It covers the challenges of balancing compute power and I/O power, introduces methods like tiling and forwarding to optimize memory usage and reduce energy consumption, and highlights a case study on various modern CNN architectures. The conclusion emphasizes the complexity of memory management and the need for compilers to effectively analyze and optimize performance indices.






















































































