Download to read offline








![Transformers for Video Understanding (2020-Present)
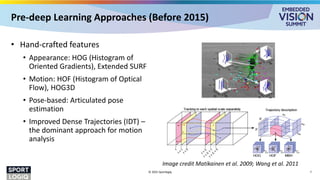
• Transformer characteristics:
• Scale with larger datasets
• Can naturally handle any input which
can get “tokenized”
• Inherent attention mechanism for
spatio-temporal information
encoding
• Handle long-range dependencies,
better scene understanding
• Can accommodate multiple
modalities
© 2025 Sportlogiq 12
3.1. Overview of Vision Transformers (ViT)
Vision Transformer (ViT) [18] adapts the transformer
architecture of [68] to process 2D images with minimal
changes. In particular, ViT extracts N non-overlapping im-
age patches, xi 2 Rh⇥w
, performs a linear projection and
then rasterises them into 1D tokens zi 2 Rd
. The sequence
of tokensinput to the following transformer encoder is
z = [zcls, Ex1, Ex2, . . . , ExN ] + p, (1)
wheretheprojection by E isequivalent to a2D convolution.
Asshown in Fig. 1, an optional learned classification token
zcl s is prepended to this sequence, and its representation at
the final layer of the encoder serves as the final represen-
tation used by the classification layer [17]. In addition, a
learned positional embedding, p 2 RN ⇥d
, is added to the
tokens to retain positional information, as the subsequent
self-attention operations in the transformer are permutation
invariant. The tokens are then passed through an encoder
consisting of asequenceof L transformer layers. Each layer
` comprisesof Multi-Headed Self-Attention [68], layer nor-
malisation (LN) [2], and MLPblocks asfollows:
y`
= MSA(LN(z`
)) + z`
(2)
z` + 1
= MLP(LN(y`
)) + y`
. (3)
The MLP consists of two linear projections separated by a
#
!
"
Figure 2: Uniform frame sampling: Wesimply sample nt frames,
and embed each 2D frameindependently following ViT [18].
!
"
#
Figure3: Tubelet embedding. Weextract and linearly embed non-
overlapping tubelets that span thespatio-temporal input volume.
Tubelet embedding An alternate method, as shown in
Fig. 3, is to extract non-overlapping, spatio-temporal
Image credit Arnab et al. 2021
3.1. Overview of Vision Transformers (ViT)
Vision Transformer (ViT) [18] adapts the transformer
architecture of [68] to process 2D images with minimal
changes. In particular, ViT extracts N non-overlapping im-
age patches, xi 2 Rh⇥w
, performs a linear projection and
then rasterises them into 1D tokens zi 2 Rd
. The sequence
of tokens input to thefollowing transformer encoder is
z = [zcl s, Ex1, Ex2, . . . , ExN ] + p, (1)
wheretheprojection by E isequivalent to a2D convolution.
As shown in Fig. 1, an optional learned classification token
zcl s is prepended to this sequence, and its representation at
the final layer of the encoder serves as the final represen-
tation used by the classification layer [17]. In addition, a
learned positional embedding, p 2 RN ⇥d
, is added to the
tokens to retain positional information, as the subsequent
self-attention operations in the transformer are permutation
invariant. The tokens are then passed through an encoder
consisting of asequenceof L transformer layers. Each layer
` comprisesof Multi-Headed Self-Attention [68], layer nor-
malisation (LN) [2], and MLPblocks asfollows:
y`
= MSA(LN(z`
)) + z`
(2)
z`+ 1
= MLP(LN(y`
)) + y`
. (3)
The MLP consists of two linear projections separated by a
#
!
"
Figure 2: Uniform frame sampling: Wesimply sample nt frames,
and embed each 2D frame independently following ViT [18].
!
"
#
Figure3: Tubelet embedding. Weextract and linearly embed non-
overlapping tubeletsthat span thespatio-temporal input volume.
Tubelet embedding An alternate method, as shown in
Fig. 3, is to extract non-overlapping, spatio-temporal
“tubes” from theinput volume, and tolinearly project thisto
Spatial Embedding
Tubelet Embedding](https://image.slidesharecdn.com/fr04javansportlogiq2025-251007142702-c6648868/85/Understanding-Human-Activity-from-Visual-Data-a-Presentation-from-Sportlogiq-12-320.jpg)
















For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/10/understanding-human-activity-from-visual-data-a-presentation-from-sportlogiq/ Mehrsan Javan, Chief Technology Officer at Sportlogiq, presents the “Understanding Human Activity from Visual Data” tutorial at the May 2025 Embedded Vision Summit. Activity detection and recognition are crucial tasks in various industries, including surveillance and sports analytics. In this talk, Javan provides an in-depth exploration of human activity understanding, covering the fundamentals of activity detection and recognition, and the challenges of individual and group activity analysis. He uses examples from the sports domain, which provides a unique test bed requiring analysis of activities involving multiple people, including complex interactions among them. Javan traces the evolution of technologies from early deep learning models to large-scale architectures, with a focus on recent technologies such as graph neural networks, transformer-based models, spatial and temporal attention and vision-language approaches, including their strengths and shortcomings. Additionally, he examines the computational and deployment challenges associated with dataset scale, annotation complexity, generalization and real-time implementation constraints. He concludes by outlining potential challenges and future research directions in activity detection and recognition.


























![[DSC Europe 23] Ivan Biliskov - Seeing Through the Lens of Transformers: A Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/ivanbiliskov-cvvisiontransformers-231129094209-d32f1292-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] Multiscale Vision Transformers(MVit)](https://cdn.slidesharecdn.com/ss_thumbnails/papermultiscalevisiontransformers-210808092058-thumbnail.jpg?width=640&height=640&fit=bounds)







































