Download to read offline





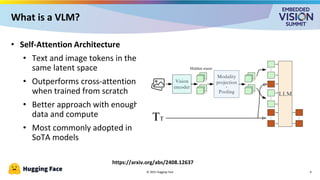


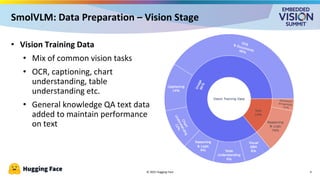
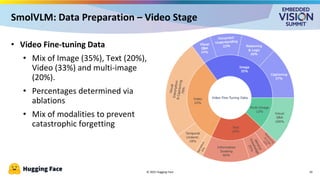



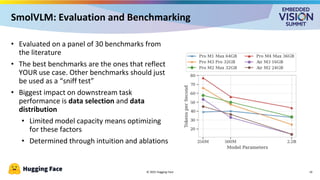





For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/09/vision-language-models-on-the-edge-a-presentation-from-hugging-face/ Cyril Zakka, Health Lead at Hugging Face, presents the “Vision-language Models on the Edge” tutorial at the May 2025 Embedded Vision Summit. In this presentation, Zakka provides an overview of vision-language models (VLMs) and their deployment on edge devices using Hugging Face’s recently released SmolVLM as an example. He examines the training process of VLMs, including data preparation, alignment techniques and optimization methods necessary for embedding visual understanding capabilities within resource-constrained environments. Zakka explains practical evaluation approaches, emphasizing how to benchmark these models beyond accuracy metrics to ensure real-world viability. And to illustrate how these concepts play out in practice, he shares data from recent work implementing SmolVLM in an edge device.
























![[OSGeo-KR Tech Workshop] Deep Learning for Single Image Super-Resolution](https://cdn.slidesharecdn.com/ss_thumbnails/osgeo-krdeeplearningforsingleimagesuper-resolution-180223175347-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DSC Europe 24] Renat Khizbullin DSC.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/dsceurope24renatkhizbullindsc-241127224518-45bc8c85-thumbnail.jpg?width=640&height=640&fit=bounds)








































