

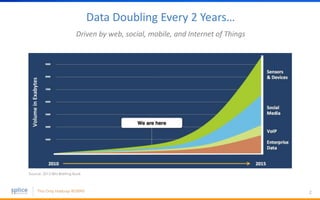



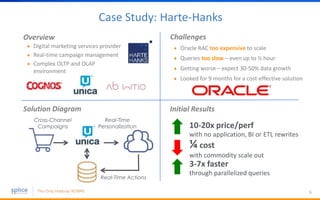
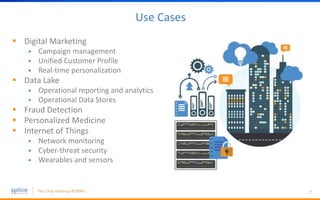
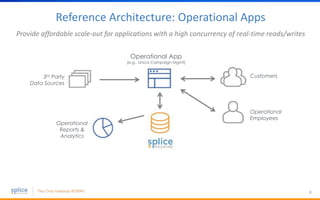
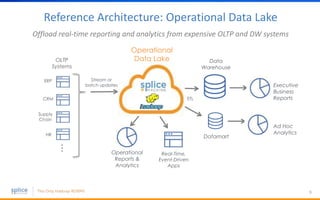
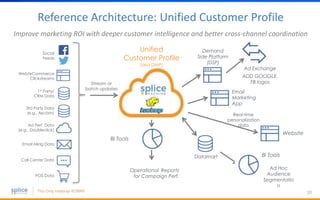
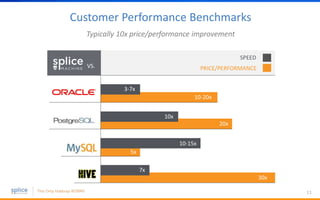







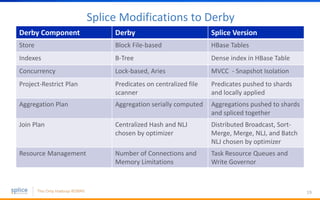
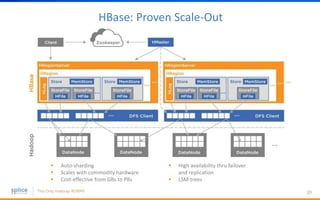
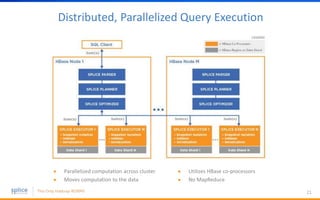



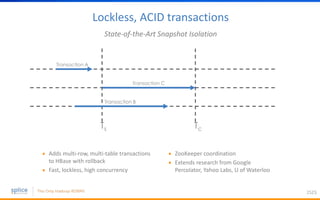


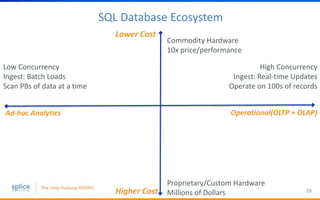
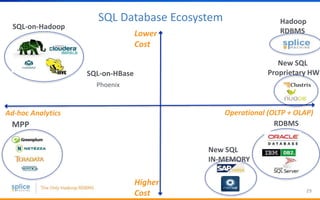




The document discusses the advantages of replacing traditional relational databases, like Oracle, with Hadoop-based scale-out SQL databases, emphasizing significant cost savings and performance improvements. It highlights successful case studies, particularly in digital marketing, where companies experienced 10-20x improvements in price/performance without the need for application rewrites. The document also details the underlying technology, features of the Hadoop RDBMS, and its operational benefits across various use cases.





![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)































![[R022] Problem Solving e Decision Making](https://cdn.slidesharecdn.com/ss_thumbnails/r022problemsolvingedecisionmaking-120705083007-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























































