Downloaded 116 times







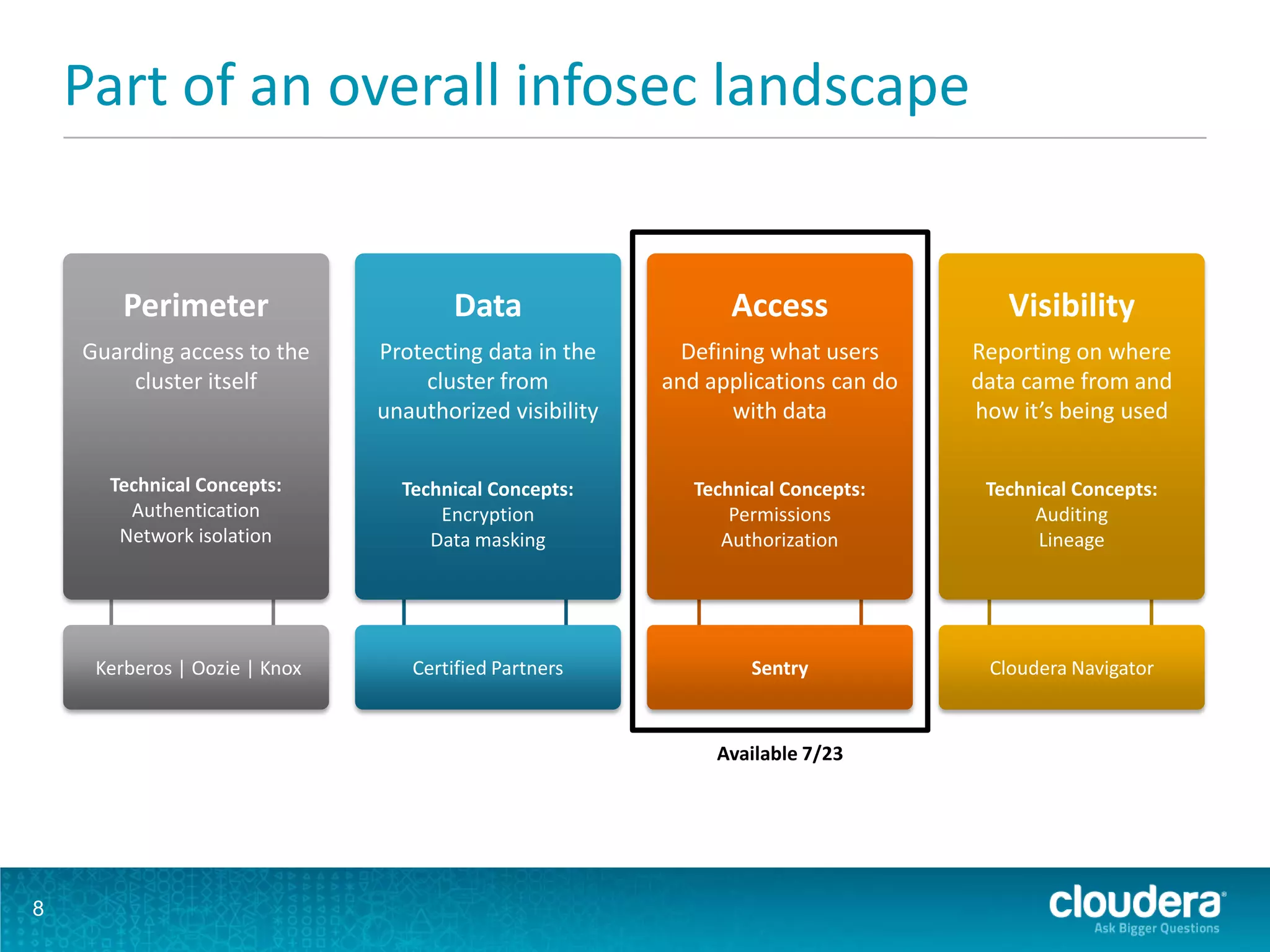

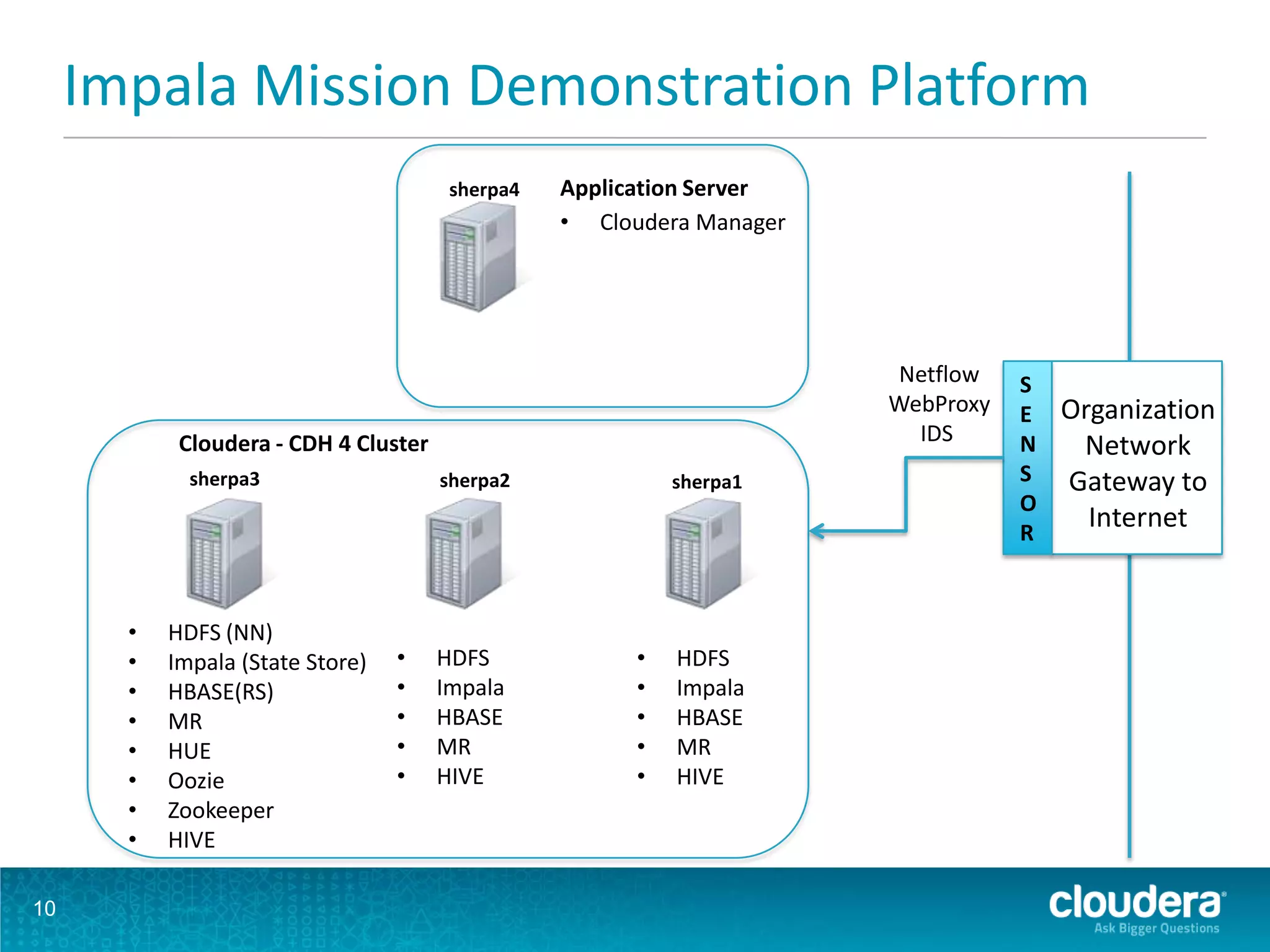





The document discusses the features and advancements in Cloudera Impala 1.1, focusing on its application in cybersecurity through fine-grained and role-based authorization with Sentry. It highlights the benefits of using Impala for interactive SQL queries on Hadoop, emphasizing its low-latency performance, cost efficiency, and ability to handle both structured and unstructured data securely. Furthermore, it includes a demonstration platform utilizing diverse data sets for cyber threat monitoring and analysis.








































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














