Downloaded 45 times



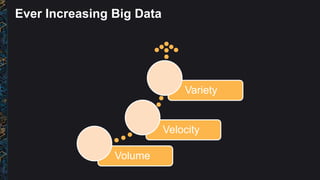
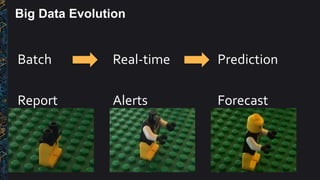



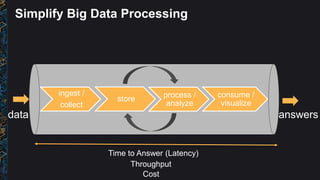

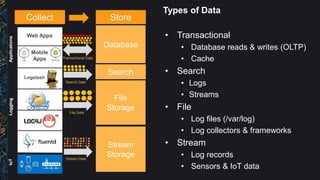

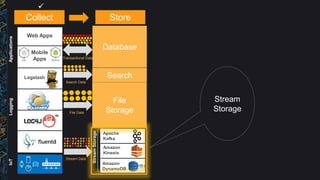

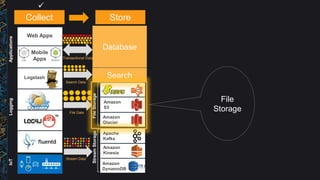


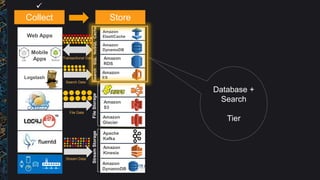

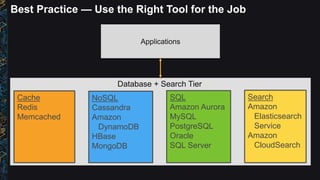

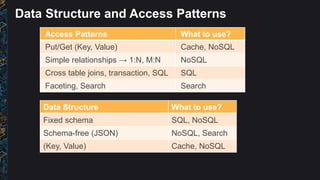

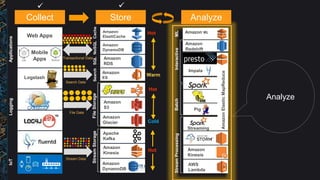



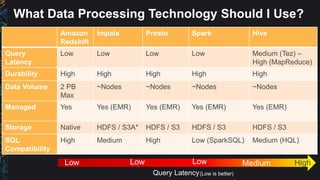


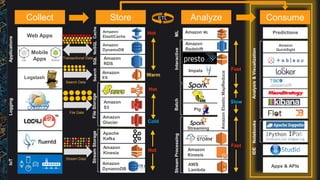
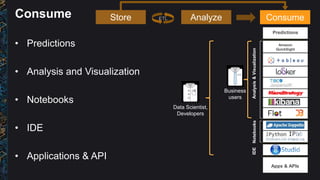

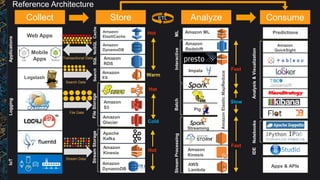


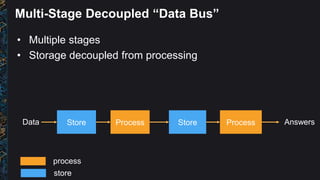
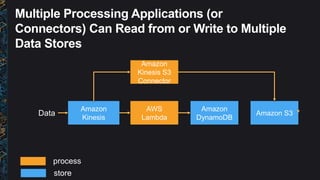
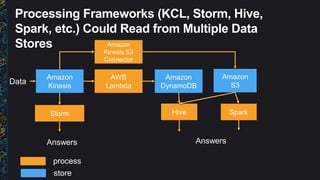
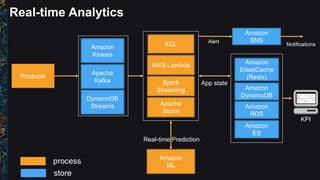
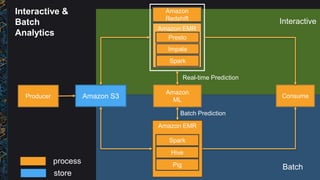
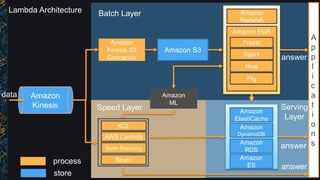




The document outlines best practices and architectural patterns for managing big data on AWS, highlighting the importance of using the right technologies for various data types and processing needs. It emphasizes a decoupled 'data bus' approach to simplify data processing, detailing the appropriate AWS services for data collection, storage, analysis, and visualization. Additionally, it suggests leveraging AWS managed services for efficiency and cost-effectiveness in big data projects.



































































