Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
KN
Uploaded by
Kouhei Nakajima
PPTX, PDF
463 views
ImageNet Classification with Deep Convolutional Neural Networks
「ImageNet Classification with Deep Convolutional Neural Networks」の紹介スライドです. ゼミの論文紹介で使用しました.
Engineering
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 19
2
/ 19
3
/ 19
4
/ 19
5
/ 19
6
/ 19
7
/ 19
8
/ 19
9
/ 19
10
/ 19
11
/ 19
12
/ 19
13
/ 19
14
/ 19
15
/ 19
16
/ 19
17
/ 19
18
/ 19
19
/ 19
More Related Content
PPTX
ResNetの仕組み
by
Kota Nagasato
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PDF
[DL Hacks]Semantic Instance Segmentation with a Discriminative Loss Function
by
Deep Learning JP
PDF
semantic segmentation サーベイ
by
yohei okawa
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PPTX
[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation
by
Deep Learning JP
PPTX
情報検索とゼロショット学習
by
kt.mako
PPTX
[DL輪読会]Objects as Points
by
Deep Learning JP
ResNetの仕組み
by
Kota Nagasato
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
[DL Hacks]Semantic Instance Segmentation with a Discriminative Loss Function
by
Deep Learning JP
semantic segmentation サーベイ
by
yohei okawa
Attentionの基礎からTransformerの入門まで
by
AGIRobots
[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation
by
Deep Learning JP
情報検索とゼロショット学習
by
kt.mako
[DL輪読会]Objects as Points
by
Deep Learning JP
What's hot
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
PDF
サポートベクトルマシン(SVM)の勉強
by
Kazuki Adachi
PDF
論文紹介:Dueling network architectures for deep reinforcement learning
by
Kazuki Adachi
PDF
[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...
by
Deep Learning JP
PPTX
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
PPTX
プロジェクトマネージャのための機械学習工学入門
by
Nobukazu Yoshioka
PDF
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
PDF
Trust Region Policy Optimization
by
mooopan
PDF
自由エネルギー原理から エナクティヴィズムへ
by
Masatoshi Yoshida
PDF
Data-Centric AI開発における データ生成の取り組み
by
Takeshi Suzuki
PPTX
データサイエンス概論第一=2-1 データ間の距離と類似度
by
Seiichi Uchida
PDF
第11回 全日本コンピュータビジョン勉強会(前編)_TableFormer_carnavi.pdf
by
RyoKawanami
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
PDF
MixMatch: A Holistic Approach to Semi- Supervised Learning
by
harmonylab
PDF
R-CNNの原理とここ数年の流れ
by
Kazuki Motohashi
PDF
Deep High Resolution Representation Learning for Human Pose Estimation
by
harmonylab
PDF
正則化項について
by
Arata Honda
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PDF
Bayesian Neural Networks : Survey
by
tmtm otm
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
サポートベクトルマシン(SVM)の勉強
by
Kazuki Adachi
論文紹介:Dueling network architectures for deep reinforcement learning
by
Kazuki Adachi
[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...
by
Deep Learning JP
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
プロジェクトマネージャのための機械学習工学入門
by
Nobukazu Yoshioka
三次元表現まとめ(深層学習を中心に)
by
Tomohiro Motoda
Trust Region Policy Optimization
by
mooopan
自由エネルギー原理から エナクティヴィズムへ
by
Masatoshi Yoshida
Data-Centric AI開発における データ生成の取り組み
by
Takeshi Suzuki
データサイエンス概論第一=2-1 データ間の距離と類似度
by
Seiichi Uchida
第11回 全日本コンピュータビジョン勉強会(前編)_TableFormer_carnavi.pdf
by
RyoKawanami
不均衡データのクラス分類
by
Shintaro Fukushima
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
MixMatch: A Holistic Approach to Semi- Supervised Learning
by
harmonylab
R-CNNの原理とここ数年の流れ
by
Kazuki Motohashi
Deep High Resolution Representation Learning for Human Pose Estimation
by
harmonylab
正則化項について
by
Arata Honda
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
Bayesian Neural Networks : Survey
by
tmtm otm
Similar to ImageNet Classification with Deep Convolutional Neural Networks
PPTX
Image net classification with deep convolutional neural network
by
ga sin
PDF
【Deep Learning】AlexNetの解説&実装 by PyTorch (colabリンク付き)
by
Daichi Hayashi
PPTX
画像認識 6.3-6.6 畳込みニューラル ネットワーク
by
Shion Honda
PDF
(2021年8月版)深層学習によるImage Classificaitonの発展
by
Takumi Ohkuma
PDF
Convolutional Neural Networks のトレンド @WBAFLカジュアルトーク#2
by
Daiki Shimada
PDF
(2022年3月版)深層学習によるImage Classificaitonの発展
by
Takumi Ohkuma
PDF
SAS ViyaのCNNを活用したProcess Innovation ~機械は解析図表をどう見ているのか~
by
SAS Institute Japan
PDF
20160601画像電子学会
by
nlab_utokyo
PDF
深層学習 - 画像認識のための深層学習 ②
by
Shohei Miyashita
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
by
nlab_utokyo
PPTX
Alex net-survey-
by
shunkimurakami
PDF
研究紹介
by
Ryosuke Tanno
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
PDF
SSII2014 詳細画像識別 (FGVC) @OS2
by
nlab_utokyo
PPTX
TensorFlowとCNTK
by
maruyama097
PDF
MIRU_Preview_JSAI2019
by
Takayoshi Yamashita
PPTX
画像認識と深層学習
by
Yusuke Uchida
PPTX
MIRU2014 tutorial deeplearning
by
Takayoshi Yamashita
PDF
20150930
by
nlab_utokyo
Image net classification with deep convolutional neural network
by
ga sin
【Deep Learning】AlexNetの解説&実装 by PyTorch (colabリンク付き)
by
Daichi Hayashi
画像認識 6.3-6.6 畳込みニューラル ネットワーク
by
Shion Honda
(2021年8月版)深層学習によるImage Classificaitonの発展
by
Takumi Ohkuma
Convolutional Neural Networks のトレンド @WBAFLカジュアルトーク#2
by
Daiki Shimada
(2022年3月版)深層学習によるImage Classificaitonの発展
by
Takumi Ohkuma
SAS ViyaのCNNを活用したProcess Innovation ~機械は解析図表をどう見ているのか~
by
SAS Institute Japan
20160601画像電子学会
by
nlab_utokyo
深層学習 - 画像認識のための深層学習 ②
by
Shohei Miyashita
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
by
nlab_utokyo
Alex net-survey-
by
shunkimurakami
研究紹介
by
Ryosuke Tanno
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
SSII2014 詳細画像識別 (FGVC) @OS2
by
nlab_utokyo
TensorFlowとCNTK
by
maruyama097
MIRU_Preview_JSAI2019
by
Takayoshi Yamashita
画像認識と深層学習
by
Yusuke Uchida
MIRU2014 tutorial deeplearning
by
Takayoshi Yamashita
20150930
by
nlab_utokyo
ImageNet Classification with Deep Convolutional Neural Networks
1.
ImageNet Classification with
Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geofferey E. Hinton University of Tronto 2012 1 発表者: 中島康平 (B4)
2.
Abstract (概要) • タスク ImageNet上の画像120万枚を1000クラスに分類する.(ILSVRC) •
構成 パラメータ数: 6000万, ニューロン数: 65万, 畳み込み層: 5つ (いくつかの畳み込み層の後ろにプーリング層がある), 全結合層: 2つ , 出力層1つ からなるCNNを構成した. • 結果 top1- エラー率: 26.2%, top5- エラー率: 15.3% → ILSVRC-2012優勝! (これにより, 深層学習が注目されるようになった.) 2
3.
Introduction (導入) • データセットの整備 機械学習は一般的に,
データ数が多いほど精度が上がる. 特に画像の分類では大規模なデータセットが必要である. → ImageNet などの大規模データセットの登場により解決. • 計算コスト ニューラルネットワークを用いた学習は計算量が多く, 学習にコストがかかる. → GPU性能の向上により解決. これらの要因により, CNNの性能を十分に発揮できるようになった. 3
4.
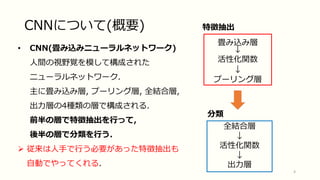
CNNについて(概要) 畳み込み層 ↓ 活性化関数 ↓ プーリング層 4 全結合層 ↓ 活性化関数 ↓ 出力層 特徴抽出 分類 • CNN(畳み込みニューラルネットワーク) 人間の視野覚を模して構成された ニューラルネットワーク. 主に畳み込み層, プーリング層,
全結合層, 出力層の4種類の層で構成される. 前半の層で特徴抽出を行って, 後半の層で分類を行う. 従来は人手で行う必要があった特徴抽出も 自動でやってくれる.
5.
CNNについて(特徴抽出) • 畳み込み層 入力画像からフィルタ数と同じ枚数の特徴マップ(画像)を生成する. (右画像ではフィルタ3つで3枚の 特徴マップを生成している.) • ブーリング層 位置変化に対して頑健性を持たせる. (詳しくは後で) 5 画像:
https://www.slideshare.net/nmhkahn/case-study-of-convolutional-neural-network-615563
6.
The Architecture (構成) •
活性化関数 ReLU関数: を使用. (シグモイド関数などを使用した場合と比べて学習が速く進む.) • 2枚のGPUで同時に学習 大規模なネットワークモデルが構成可能に. • 輝度の正規化 LRN(次のページ)を用いて, プーリング層で最大プーリングをする前に 正規化行う. 6
7.
LRN(局所応答正規化) 7 同一位置(ピクセル)において複数の特徴マップを正規化する. : 番目の特徴マップの()座標におけるピクセル値 :
正規化された番目の特徴マップの()座標におけるピクセル値 N : 特徴マップの総数 はハイパーパラメータで, 本研究ではそれぞれ と設定している.
8.
8 • Overlapping Pooling
(プーリング層の重複) プーリング範囲をz×zとして, スライド幅をsとすると, 一般的には s = z となるように設定される. (下画像は z = 2, s = 2) → 各ユニットを重複しないように選ぶ. 今回の研究では, s = 2, z = 3としてプーリングを行う. → 各ユニットがすこしかぶるように選ぶ. (これにより汎化性能が向上した.) 画像: https://deepage.net/deep_learning/2016/11/07/convolutional_neural_network.html
9.
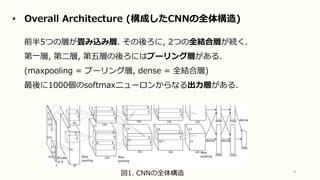
9 • Overall Architecture
(構成したCNNの全体構造) 前半5つの層が畳み込み層. その後ろに, 2つの全結合層が続く. 第一層, 第二層, 第五層の後ろにはプーリング層がある. (maxpooling = プーリング層, dense = 全結合層) 最後に1000個のsoftmaxニューロンからなる出力層がある. 図1. CNNの全体構造
10.
Reducing Overfitting (過学習を防止する) •
今回構成したCNNモデルは, パラメータ数が約6000万であり, 過学習を考慮する必要がある. • 過学習を防ぐためには? 訓練データ数を増やす → データ拡張 ドロップアウト 10
11.
データ拡張 11 • 訓練用の画像にノイズを加えたり, 輝度を変えることで,
訓練データの水増 しをして, モデルの汎化性能を高める手法. • データの加工の仕方によっては逆にモデルの性能を下げることもあるため, データの特徴を考慮して加工する必要がある. 画像:http://aidiary.hatenablog.com/entry/20161212/1481549365
12.
ドロップアウト • 学習時に, ある更新で層の中のノードの重みを一部0とする
(ノードが存在して いないように扱う)ことで, ネットワークの自由度を小さくする. その次の更新 では別のノードを無視する. これにより, 汎化性能を上げることができる. しかし, 学習に要する時間が増加する というデメリットもある. 12 画像: http://sonickun.hatenablog.com/entry/2016/07/18/191656
13.
本研究におけるデータの拡張・ドロップアウト • データの拡張 画像の水平移動・反転 RGB強度を変える • ドロップアウト 全結合層で,
各ノードの重みを50%の確率で0にする. 13
14.
DataSet (データセット) • ISVRC-2010のデータセットを使用. 訓練データ
: 120万枚 検証データ : 5万枚 テストデータ: 15万枚 • 画像サイズはリサイズして, 256×256に統一する. 14
15.
• バッチ学習 (バッチサイズは128) •
各重みパラメータの初期値は平均: 0, 標準偏差: 0.01の ガウス分布に従ってランダムに設定 • バイアスパラメータは, 第二層, 第四層, 第五層, 全結合層は1, それ以外の層ではすべて0とする. • epoch数: 約90 • 学習時間: 5 〜 6日 (GPU2台で計算) 15 Details of learning (学習の内容)
16.
重みの更新式 16 𝑤𝑖: 学習ステップ i番目の重み 𝑣𝑖:
学習ステップ i番目の重みの変化量 𝜖: 学習率 (初期値は0.01) 𝐿: 誤差関数 学習が進まなくなった時は, 学習率を10で割る.
17.
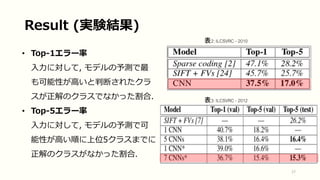
Result (実験結果) 17 • Top-1エラー率 入力に対して,
モデルの予測で最 も可能性が高いと判断されたクラ スが正解のクラスでなかった割合. • Top-5エラー率 入力に対して, モデルの予測で可 能性が高い順に上位5クラスまでに 正解のクラスがなかった割合. 表2: ILCSVRC - 2010 表3: ILCSVRC - 2012
18.
Discussion (考察) • 層の数(深さ)が結果に大きく影響を与える. →
ILSVRC-2015 では層数152のモデルが優勝 (本研究のモデルは層数8) • 学習には結構時間がかかる. • 人間の視覚レベルに達するにはまだ課題が多い. ( 訓練回数, 層の数を増やすだけでは厳しい ) • 最終的には, さらに層を深くして, 動画を学習データとして 試してみたい. 18
19.
参考 • これならわかる深層学習入門 瀧
雅人 講談社 • 高卒でもわかる機械学習(7) 畳み込みニューラルネットワーク http://hokuts.com/2016/12/13/cnn1/ • Deep learningで画像認識④〜畳み込みニューラルネット ワークの構成〜 https://lp-tech.net/articles/LVB9R • 定番のConvolutional Neural Networkをゼロから理解する https://deepage.net/deep_learning/2016/11/07/convolut ional_neural_network.html 19
Download



















![[DL Hacks]Semantic Instance Segmentation with a Discriminative Loss Function](https://cdn.slidesharecdn.com/ss_thumbnails/taniai20180528-180528084124-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DLHacks 実装]Network Dissection: Quantifying Interpretability of Deep Visual R...](https://cdn.slidesharecdn.com/ss_thumbnails/171030netdissectimple1-171030120240-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)


































