Downloaded 25 times








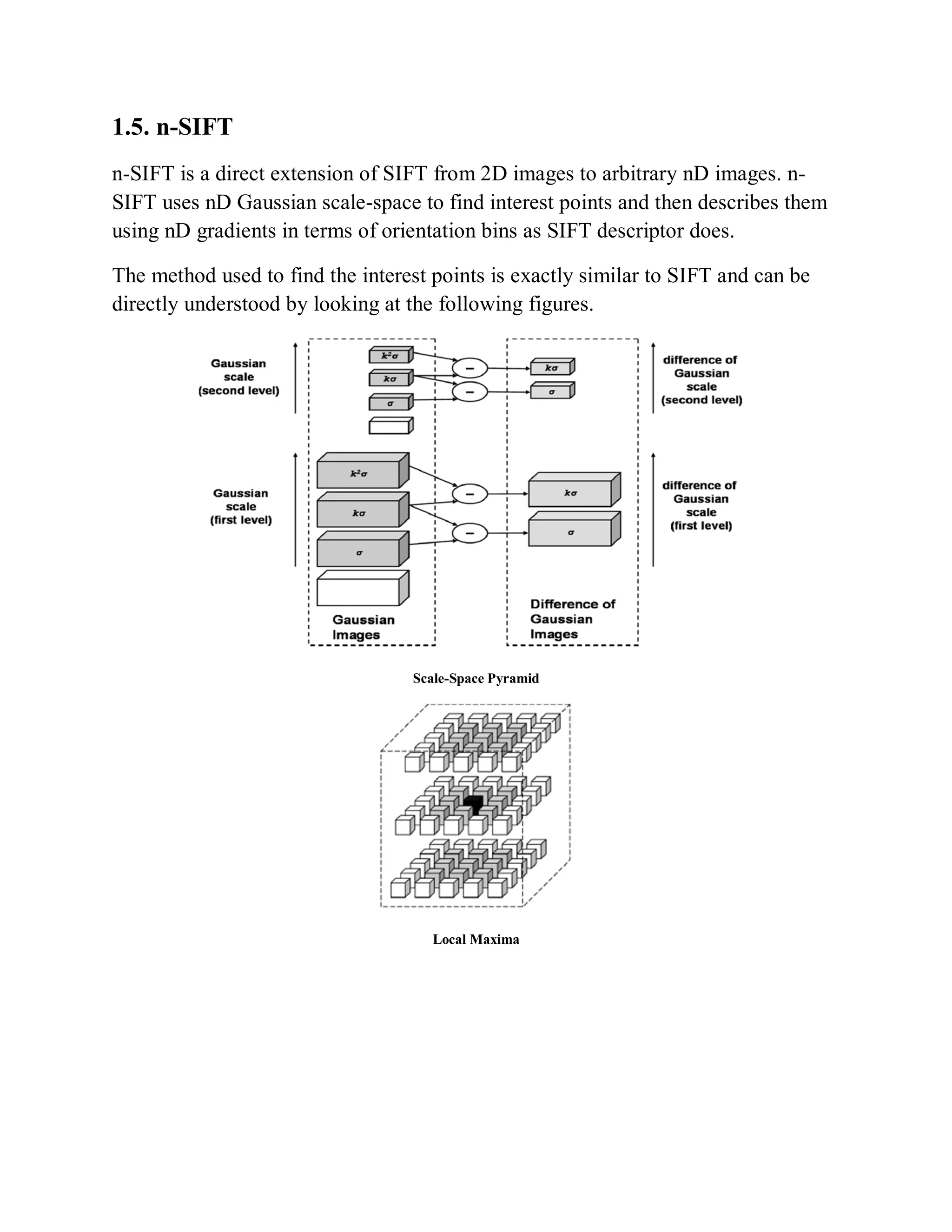

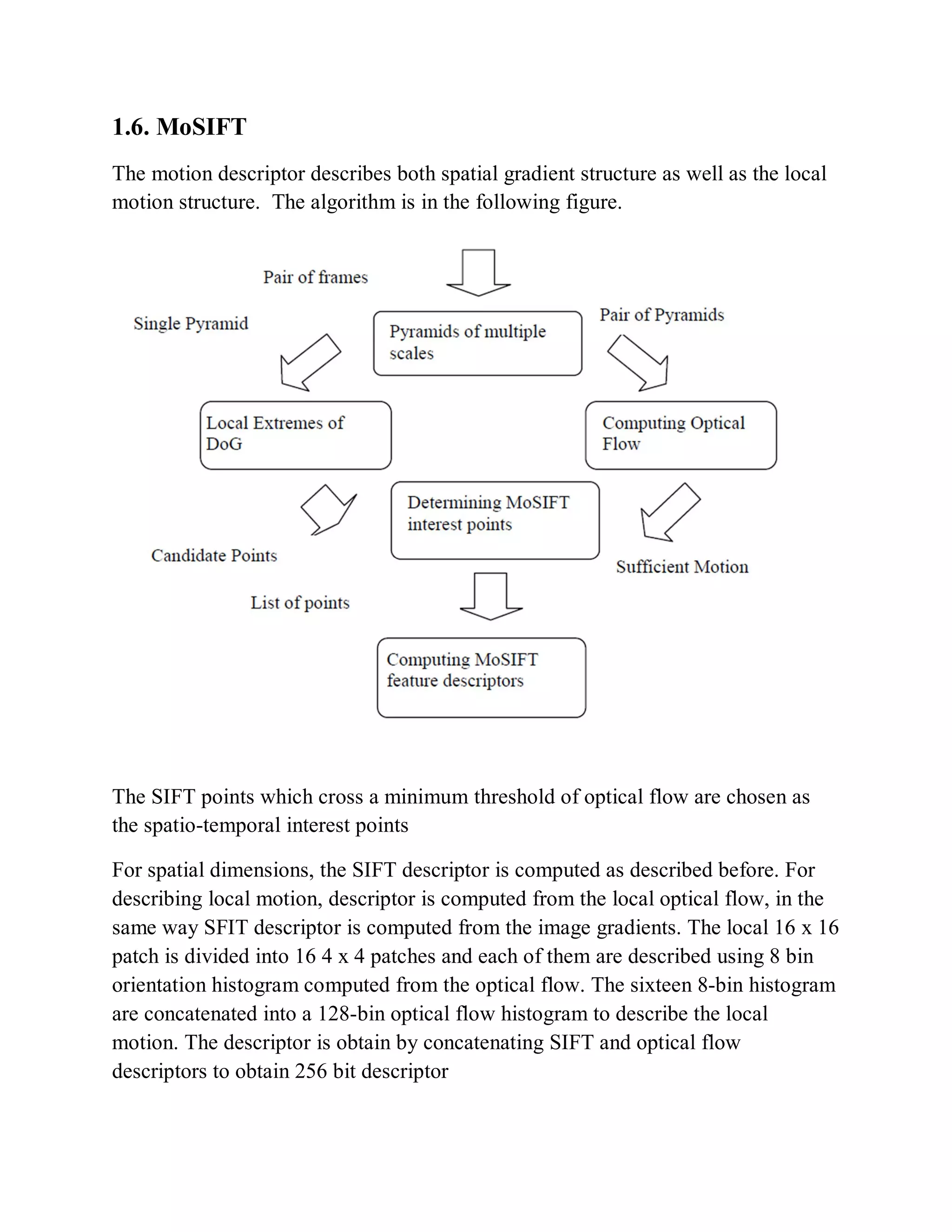


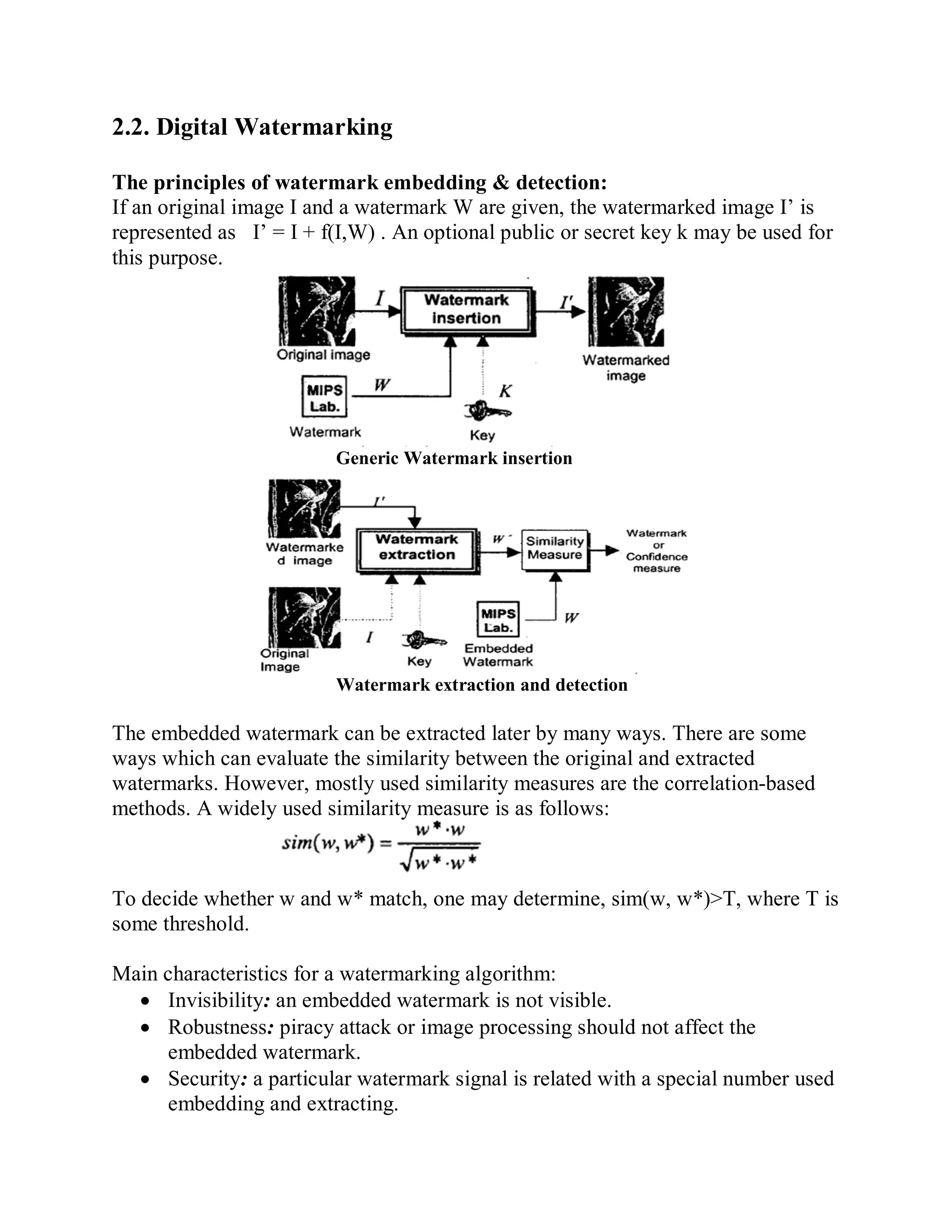













This document provides a literature survey on SIFT-based video watermarking. It discusses several interest point detectors such as Harris corner detector, scale invariant feature transform (SIFT) detector, Harris 3D detector, n-SIFT, and MoSIFT. These detectors aim to identify stable feature points in videos that are invariant to geometric transformations. The document also provides an overview of digital watermarking techniques and applications of SIFT for image watermarking. It discusses challenges in video watermarking such as resisting geometric attacks and collusion. The trends in video watermarking include extending techniques from still images and exploiting video compression formats. The document aims to explore applying SIFT to video watermarking.













































































