Downloaded 69 times











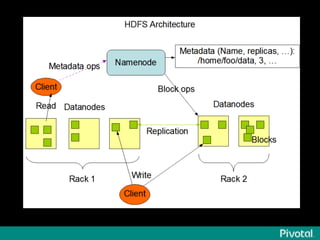






































![[Close to] real-time SQL
• Impala (inspired by Google’s F1)
• Hive/Tez (AKA Stinger)
• Facebook’s Presto (Hive’s lineage)
• Pivotal’s HAWQ](https://image.slidesharecdn.com/elephantinthecloud-140323204848-phpapp01/85/Elephant-in-the-cloud-68-320.jpg)







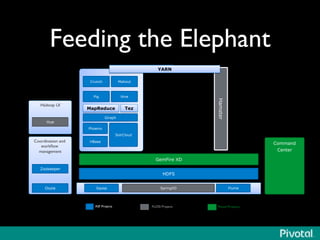

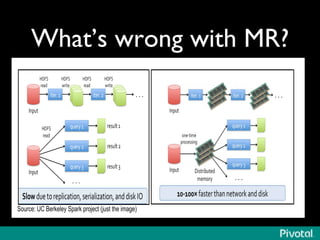

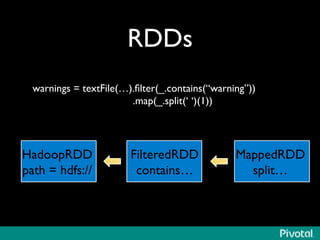






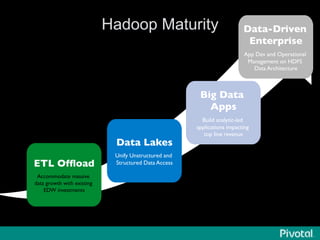

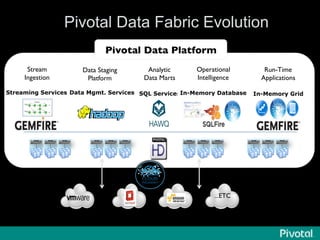

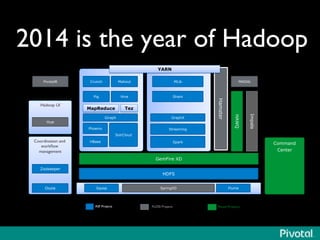




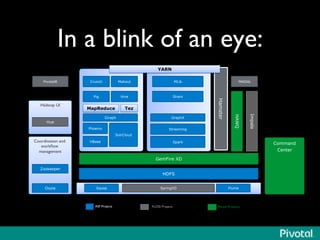
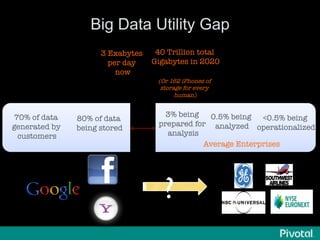
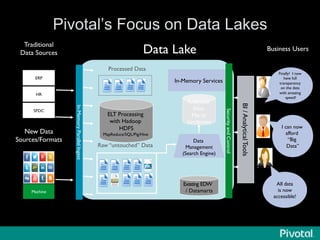
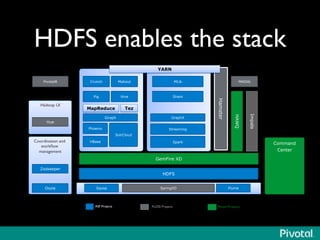
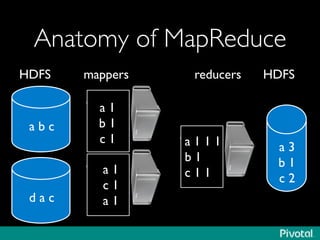
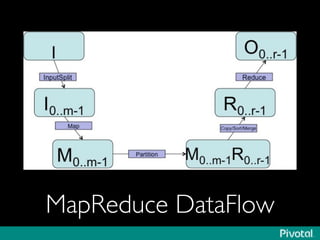
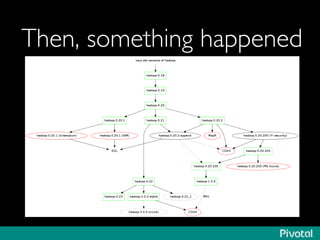
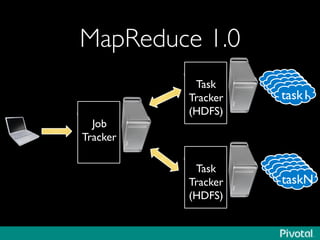
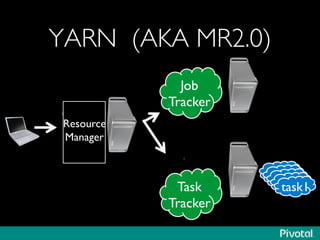
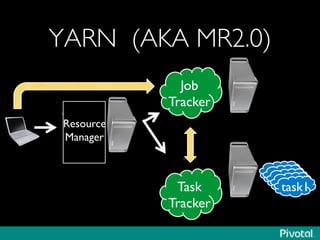
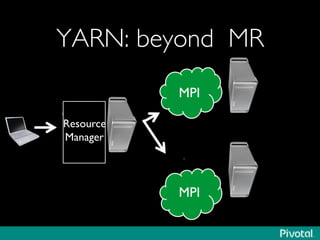
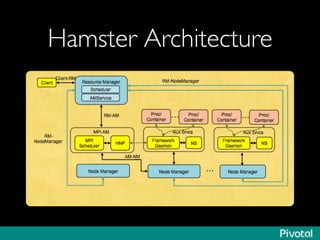
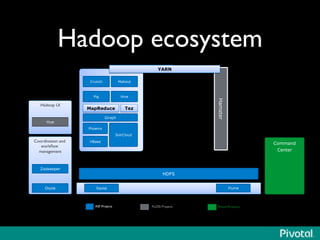
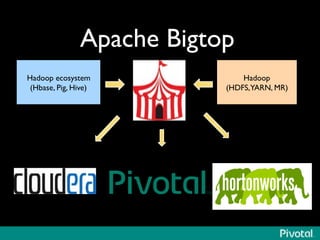
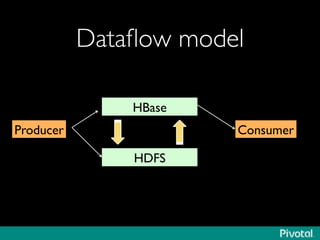
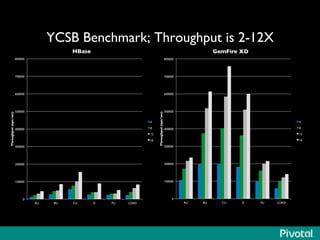
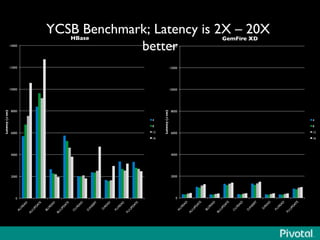
The document presents an overview of the evolution and architecture of Hadoop, emphasizing its role in big data processing and analysis. It discusses the transition from older versions of Hadoop to the integration of YARN and new tools like Tez and Hamster, outlining the ecosystem's capabilities for data lakes and processing frameworks. The summary also highlights the advancements in querying technologies like Hive and Spark, along with infrastructure implications for cloud computing in large-scale data management.