![Using Apache Hive
with HBase
And Recent Improvements
Enis Soztutar
enis [at] apache [dot] org
@enissoz
© Hortonworks Inc. 2011 Page 1](https://image.slidesharecdn.com/hivewithhbase-120329184748-phpapp01/75/Mar-2012-HUG-Hive-with-HBase-1-2048.jpg)





















![Hbase Security – Closer look
• The ACL lists can be defined at the global/table/column
family or column qualifier level for users and groups
• No roles yet
• There are 5 actions (privileges): READ, WRITE, EXEC,
CREATE, and ADMIN (RWXCA)
grant 'bobsmith', 'RW', 't1' [,'f1']
[,'col1']
revoke 'bobsmith', 't1', 'f1' [,'f1']
[,'col1']
user_permission 'table1'
Architecting the Future of Big Data
Page 29
© Hortonworks Inc. 2011](https://image.slidesharecdn.com/hivewithhbase-120329184748-phpapp01/75/Mar-2012-HUG-Hive-with-HBase-29-2048.jpg)


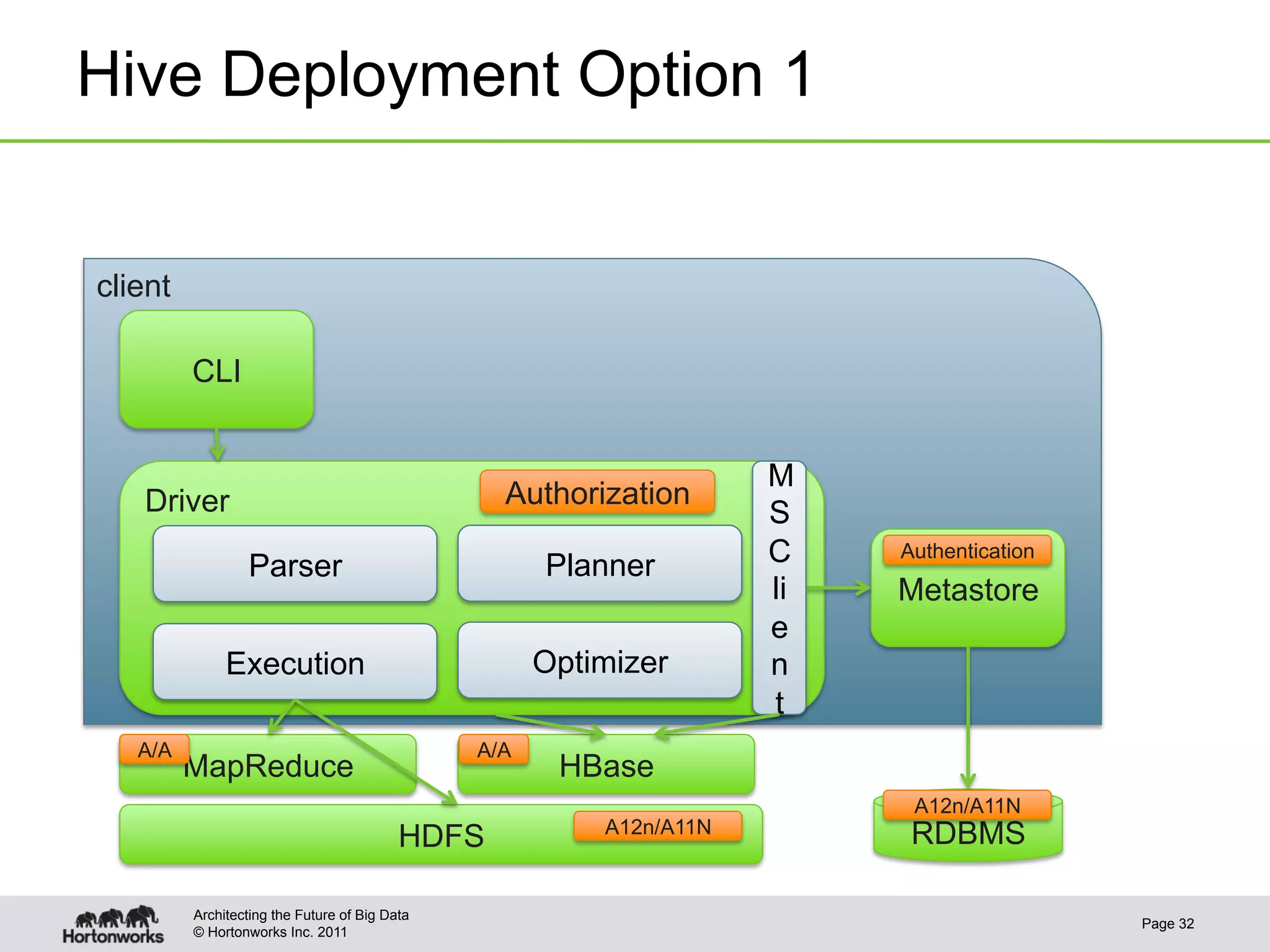
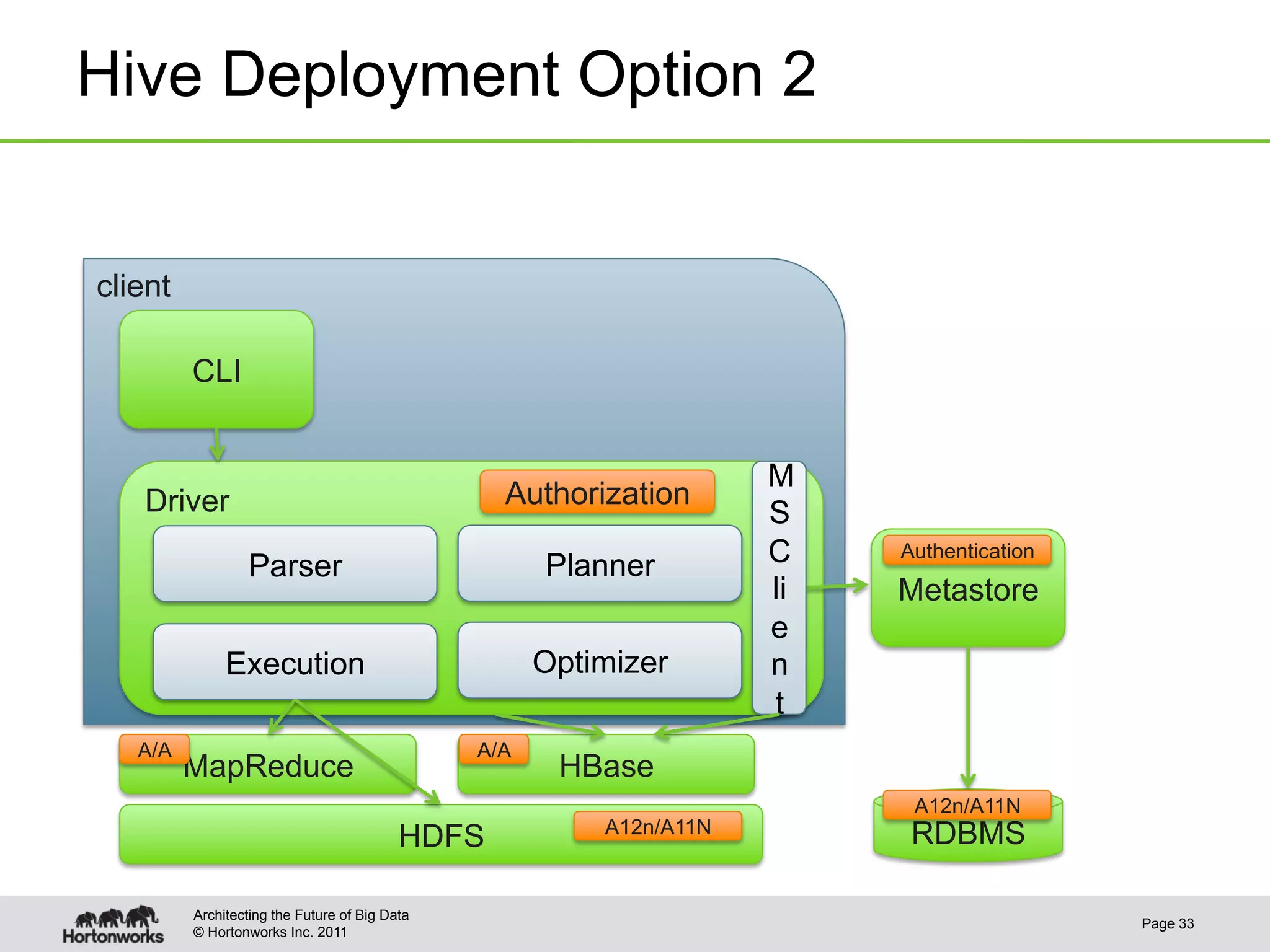
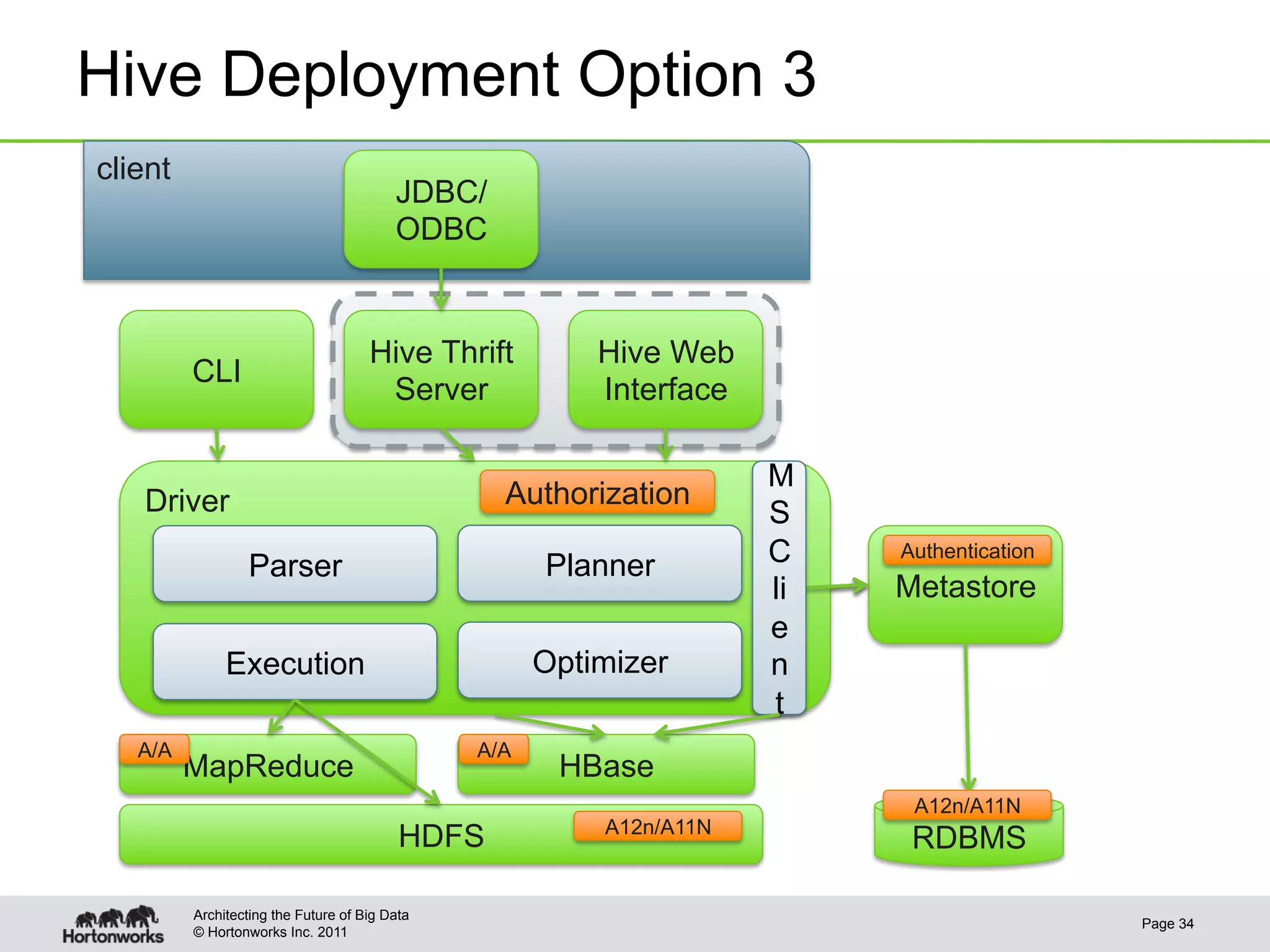






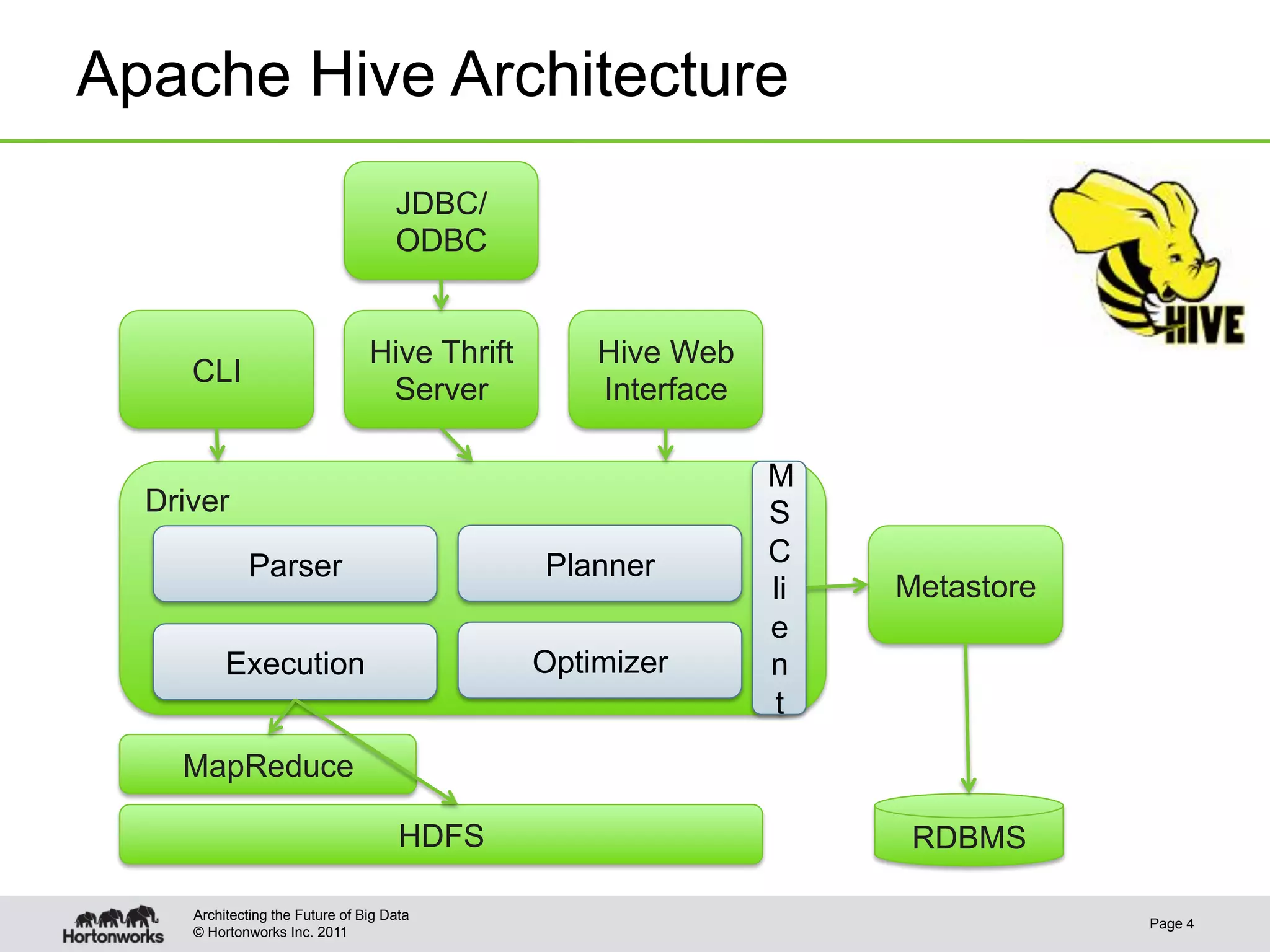
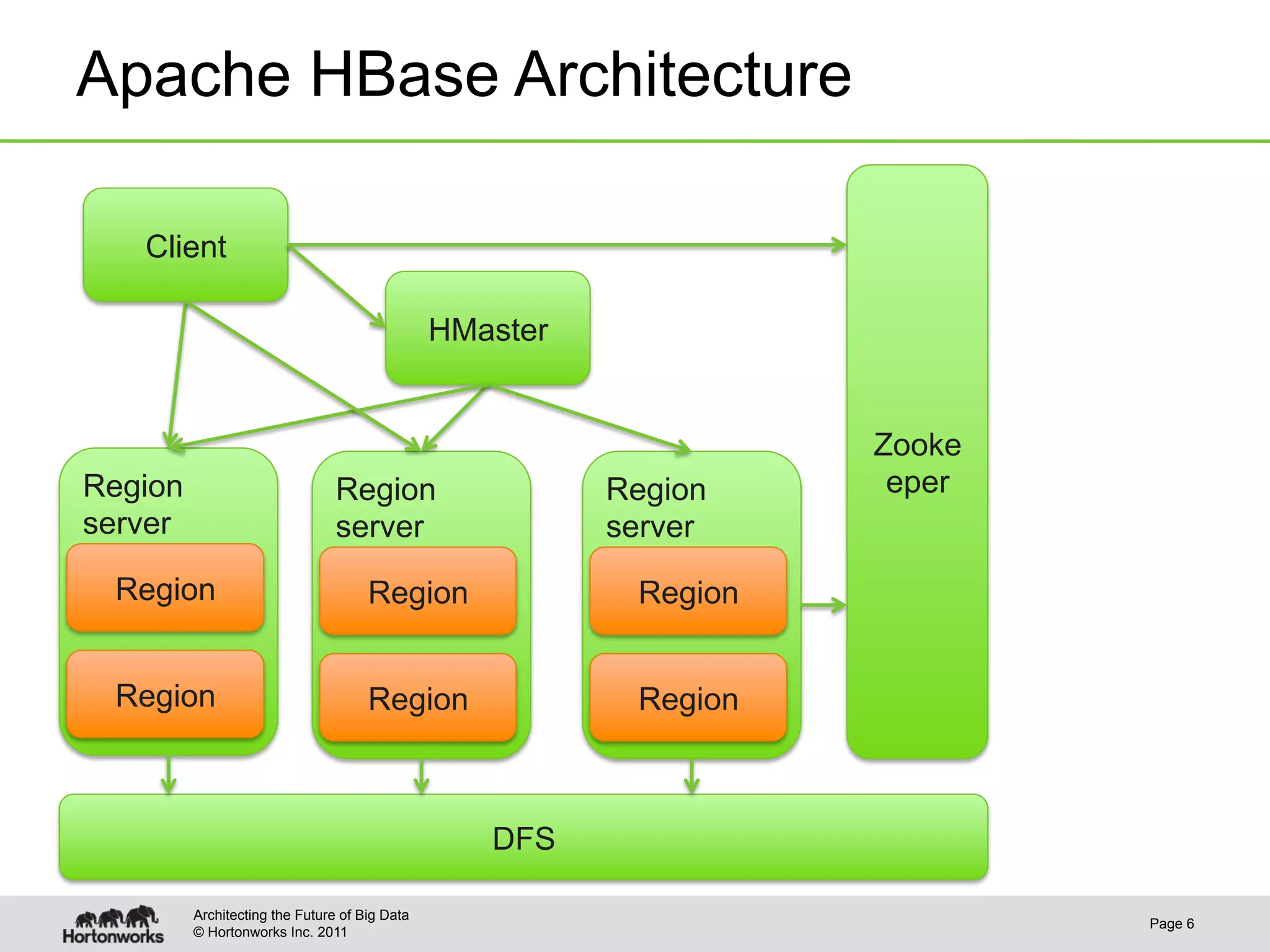
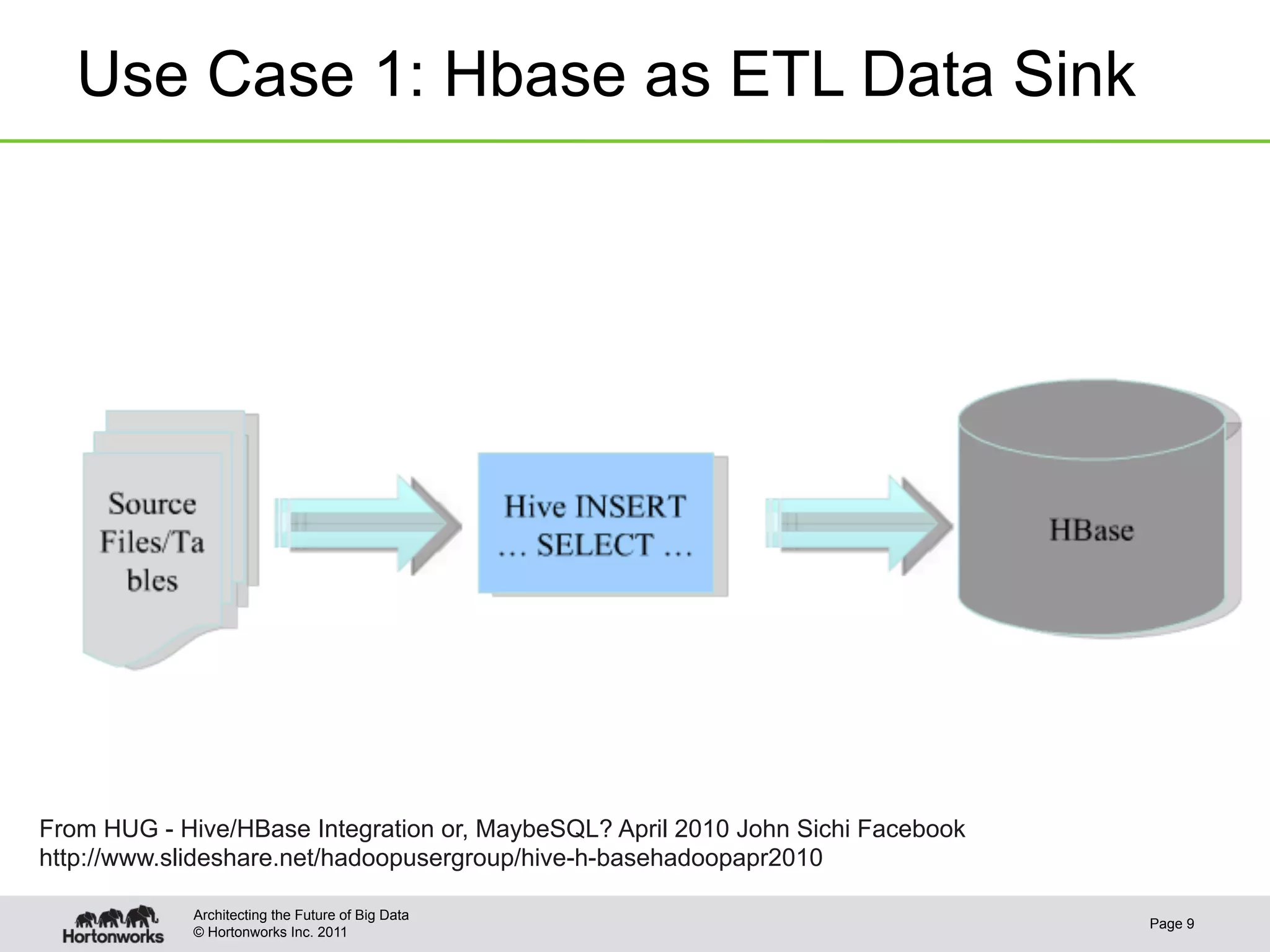
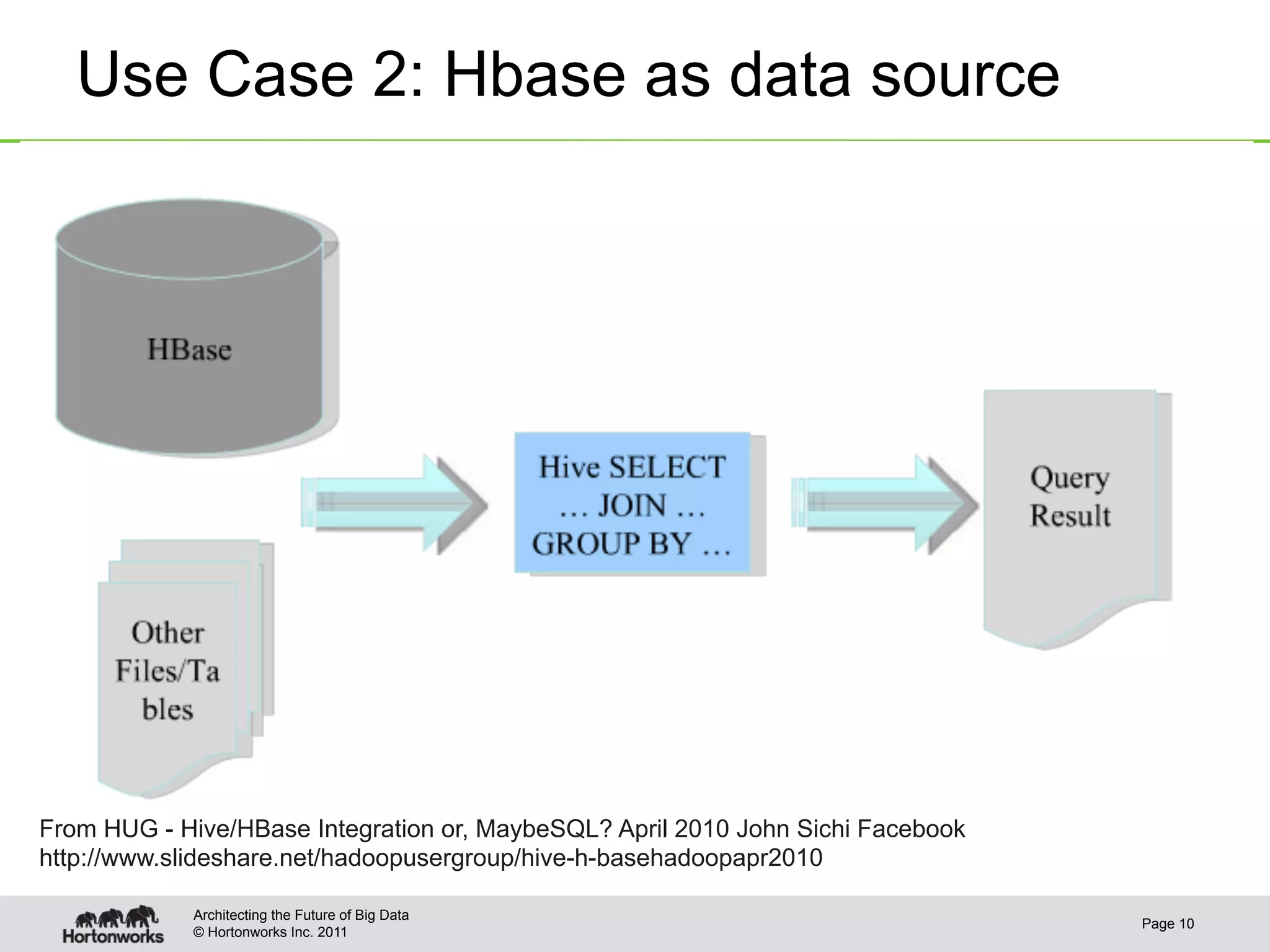
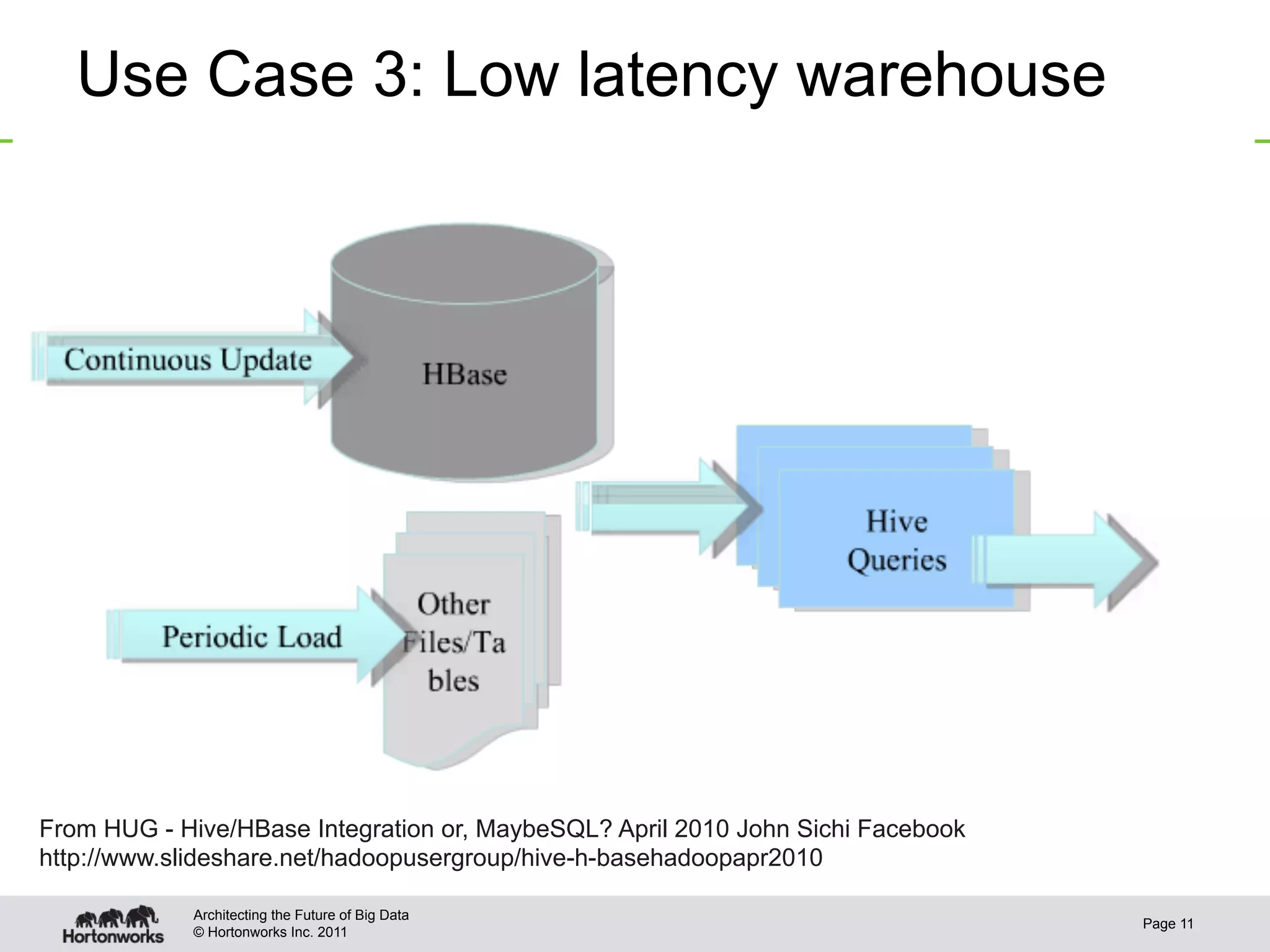
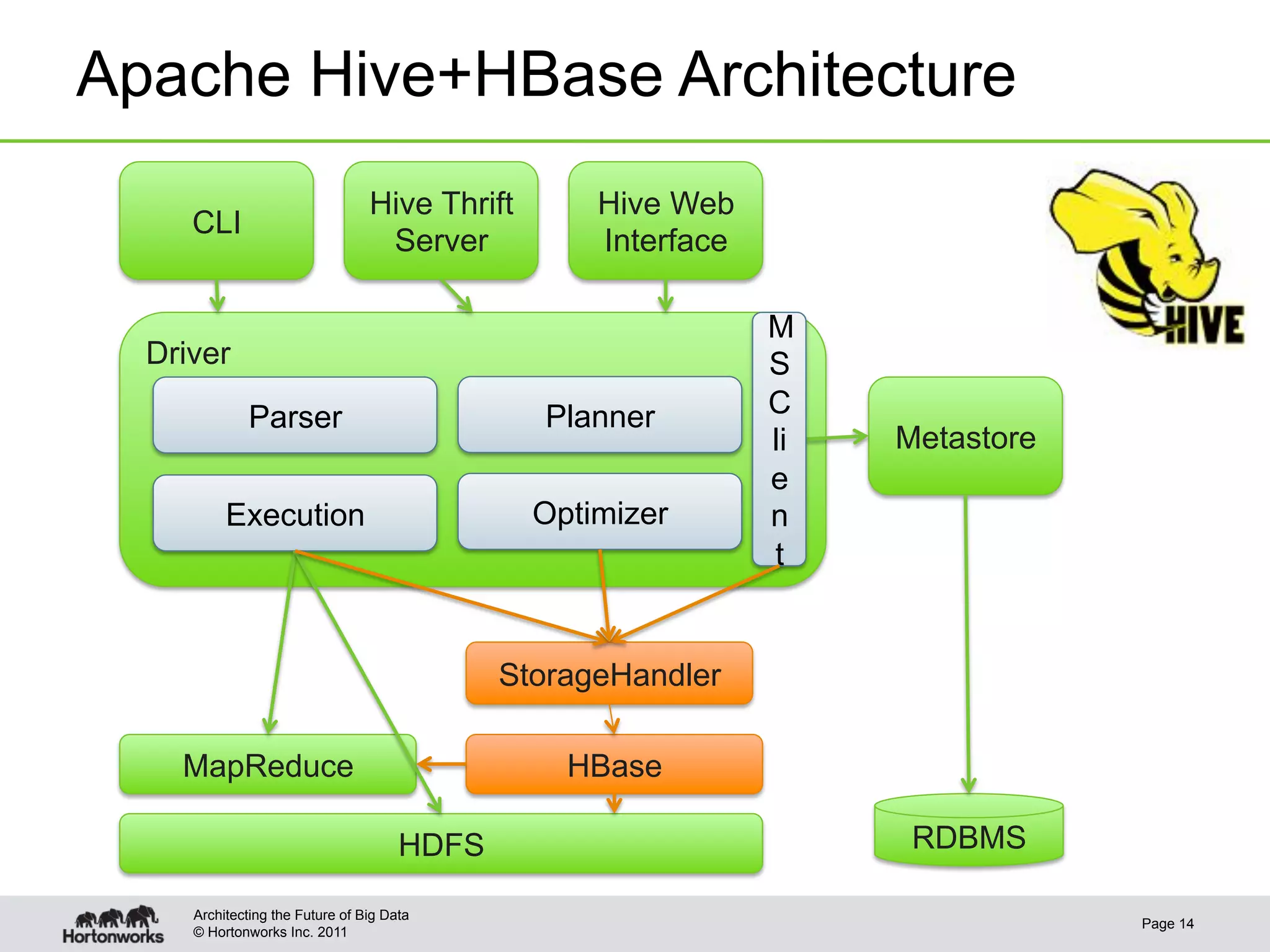
This document discusses integrating Apache Hive with Apache HBase. It provides an overview of Hive and HBase, the motivation for integrating the two systems, and how the integration works. Specifically, it covers how the schema and data types are mapped between Hive and HBase, how filters can be pushed down from Hive to HBase to optimize queries, bulk loading data from Hive into HBase, and security aspects of the integrated system. The document is intended to provide background and technical details on using Hive and HBase together.






























































































