Download as PDF, PPTX




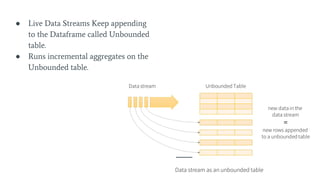

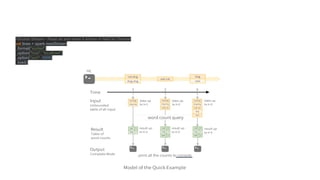







Structured Streaming in Apache Spark 2.0 introduces a continuous data flow programming model. It processes live data streams using a streaming query that is expressed similarly to batch queries on static data. The streaming query continuously appends incoming data to an unbounded table and performs incremental aggregations. This allows for exactly-once processing semantics without users needing to handle micro-batching or fault tolerance. Structured Streaming queries can be written using the Spark SQL DataFrame/Dataset API and output to sinks like files, databases, and dashboards. It is still experimental but provides an alternative to the micro-batch model of earlier Spark Streaming.



































































