Downloaded 70 times




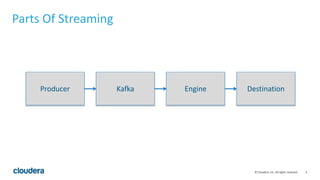
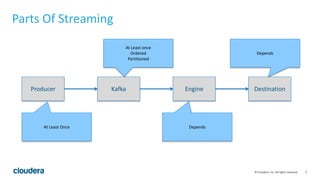









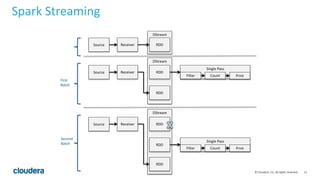
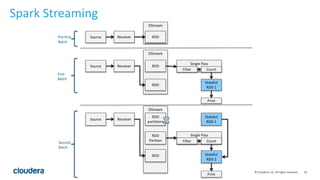

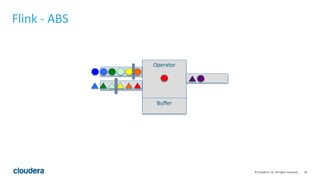
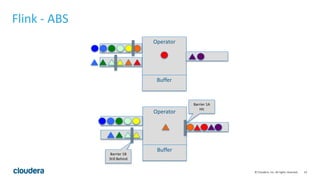
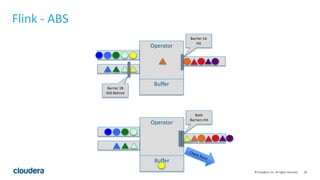
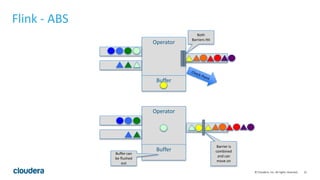





This document discusses streaming data ingestion and processing options. It provides an overview of common streaming architectures including Kafka as an ingestion hub and various streaming engines. Spark Streaming is highlighted as a popular and full-featured option for processing streaming data due to its support for SQL, machine learning, and ease of transition from batch workflows. The document also briefly profiles StreamSets Data Collector as a higher-level tool for building streaming data pipelines.











































































































