Downloaded 20 times



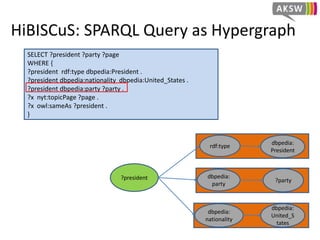
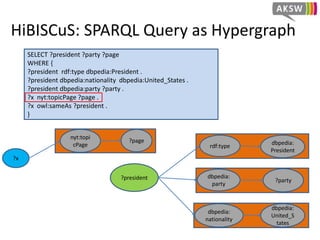
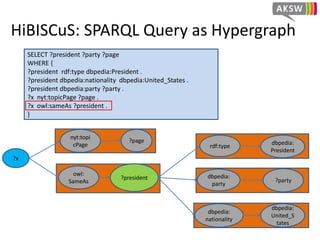
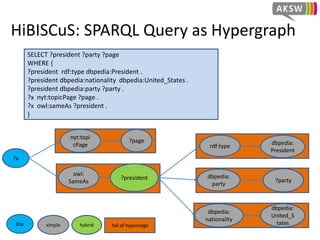

![HiBISCuS: Data Summaries
[] a ds:Service ;
ds:endpointUrl <http://dbpedia.org/sparql> ;
ds:capability [
ds:predicate dbpedia:party ;
ds:sbjAuthority <http://dbpedia.org/> ;
ds:objAuthority <http://dbpedia.org/> ;
] ;
ds:capability [
ds:predicate rdf:type ;
ds:sbjAuthority <http://dbpedia.org/> ;
ds:objAuthority owl:Thing, dbpedia:President; #we store all distinct
classes
] ;
ds:capability [
ds:predicate dbpedia:postalCode ;
ds:sbjAuthority <http://dbpedia.org/> ;
#No objAuthority as the object value for dbpedia:postalCode is string
] ;](https://image.slidesharecdn.com/hibiscuseswc2014-140528085736-phpapp02/85/HiBISCuS-Hypergraph-Based-Source-Selection-for-SPARQL-Endpoint-Federation-20-320.jpg)
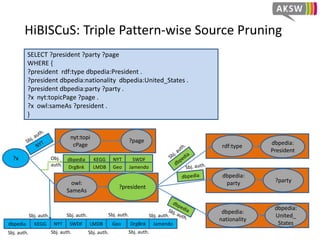
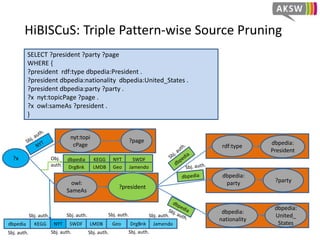
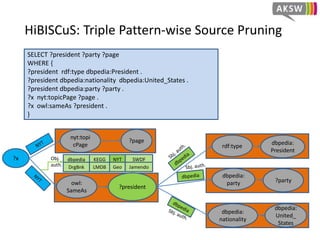
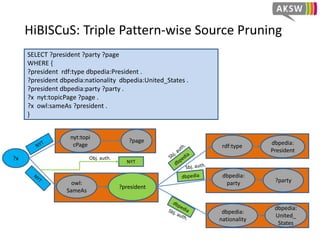
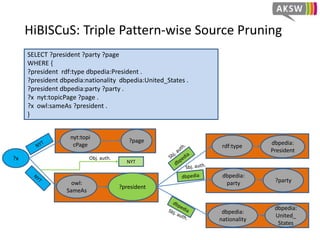
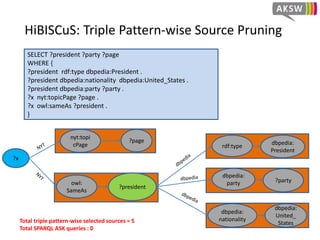


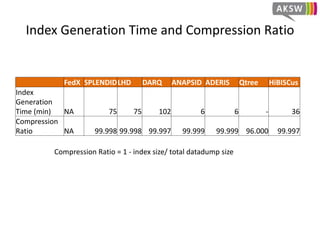
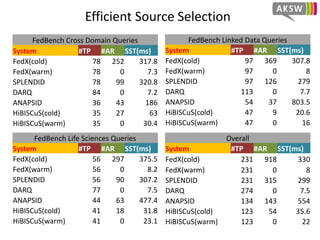
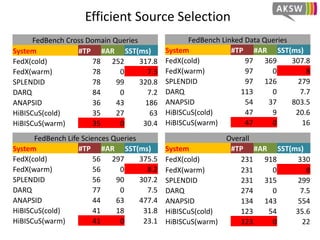
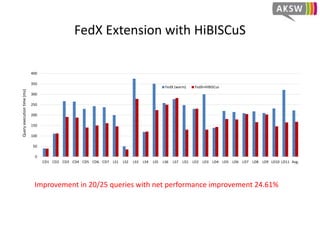
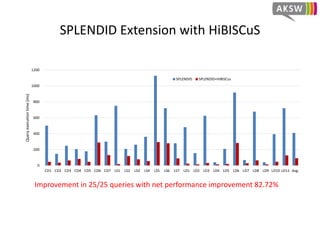
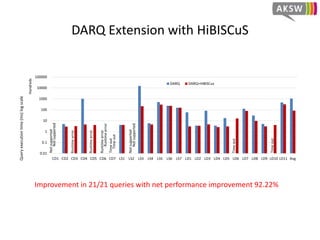
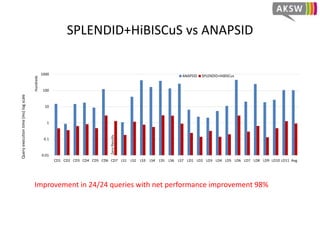





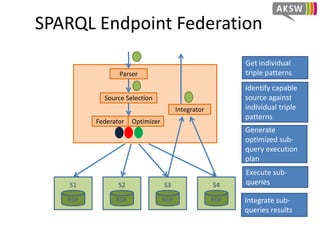
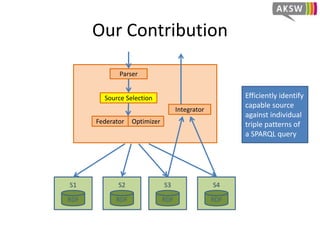
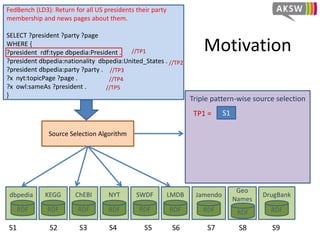
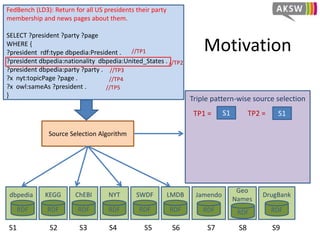
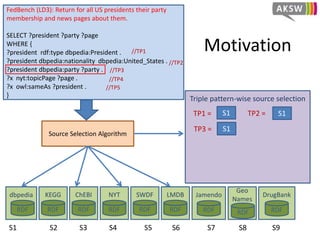
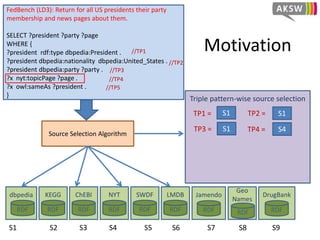
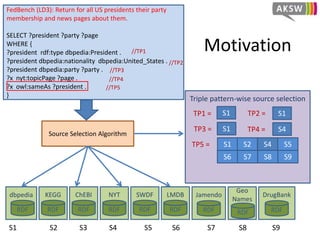
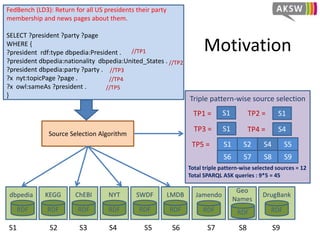
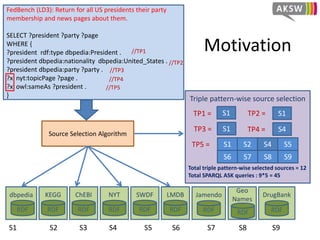
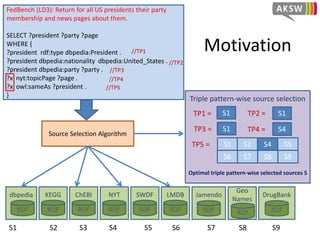
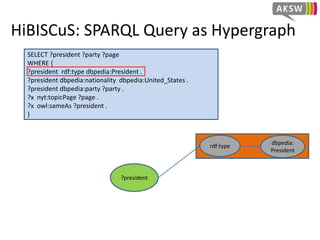
The document presents 'hibiscus', a hypergraph-based approach for efficient source selection in SPARQL endpoint federation, aimed at optimizing query execution plans for RDF data. It addresses challenges in overestimating source selection which can waste resources and increase query runtimes by introducing techniques for join-aware triple pattern-wise source selection. The study utilizes real-world datasets from FedBench to evaluate the performance of hibiscus against other existing systems and measures various metrics, including index generation time and source selection efficiency.
















































































