Downloaded 371 times







































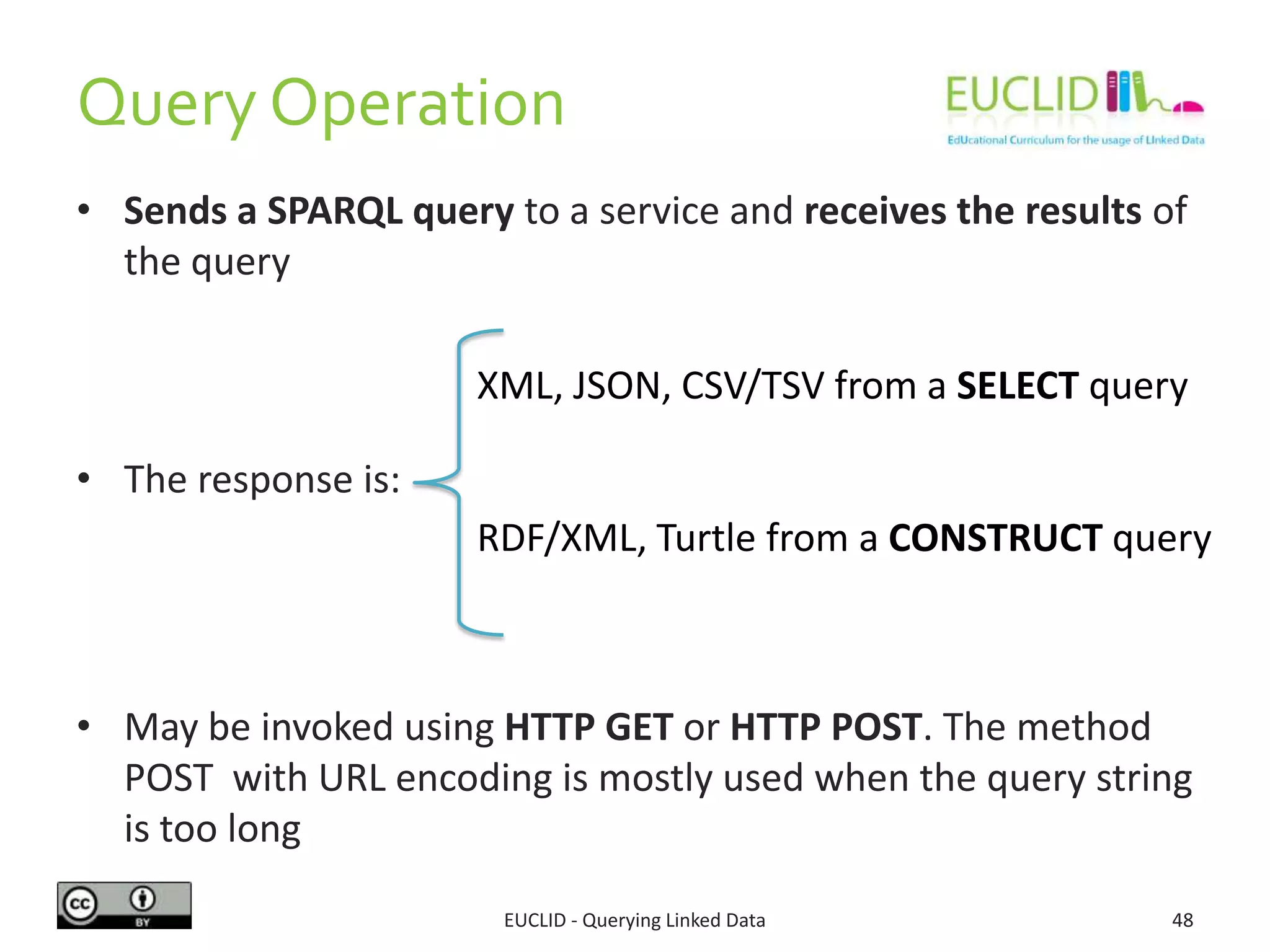
![SPARQL 1.1. Protocol
EUCLID - Querying Linked Data 49
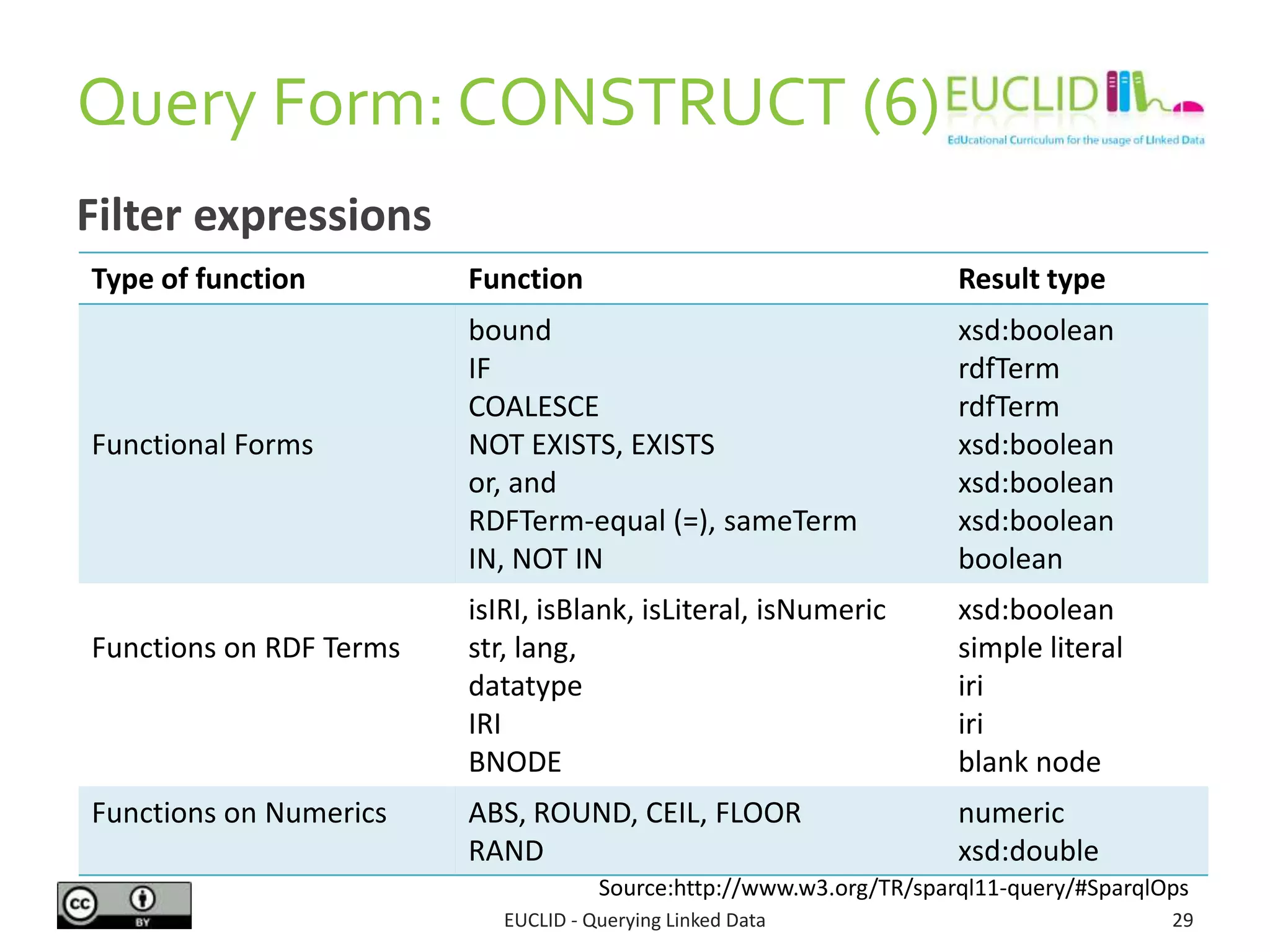
• Consists of two operations: query and update
• An operation defines:
• The HTTP method (GET or POST)
• The HTTP query string parameters
• The message content included in the HTTP request body
• The message content included in the HTTP response body
SPARQL Client SPARQL Endpoint
Request
alt [no errors]
[else]
Success Response
Failure Response](https://image.slidesharecdn.com/queryinglinkeddata-130228094134-phpapp02/75/Querying-Linked-Data-49-2048.jpg)




















![Class Construction (2)
EUCLID - Querying Linked Data 81
These class constructs are available in OWL, not in RDFS
The class of female music artists
ObjectIntersectionOf(:Female :MusicArtist)
[a owl:Class;
owl:intersectionOf(:Female :MusicArtist)]
The class of music artists
ObjectUnionOf(:SoloMusicArtist :MusicGroup)
[a owl:Class;
owl:unionOf(:SoloMusicArtist :MusicGroup)]
Everything that’s not instrumental music
ObjectComplementOf(:InstrumentalMusic)
[a owl:Class;
owl:complementOf(:InstrumentalMusic)]
Female
Music Artist
Solo
Group
Instrumental
≡
≡
≡
NOTE: Anonymous classes!](https://image.slidesharecdn.com/queryinglinkeddata-130228094134-phpapp02/75/Querying-Linked-Data-81-2048.jpg)
![Naming Class Constructions
EUCLID - Querying Linked Data 82
• Direct naming can be achieved via owl:equivalentClass
• This construction provides necessary and sufficient conditions
for class membership
• Class naming can be also achieved using rdfs:subClassOf,
it provides a necessary but insufficient condition for class
membership
Music Artist
Solo
Group
EquivalentClass(:MusicArtist
ObjectUnionOf(:SoloMusicArtist
:MusicGroup))
:MusicArtist owl:equivalentClass
[owl:unionOf (:SoloMusicArtist :MusicGroup)]
≡](https://image.slidesharecdn.com/queryinglinkeddata-130228094134-phpapp02/75/Querying-Linked-Data-82-2048.jpg)





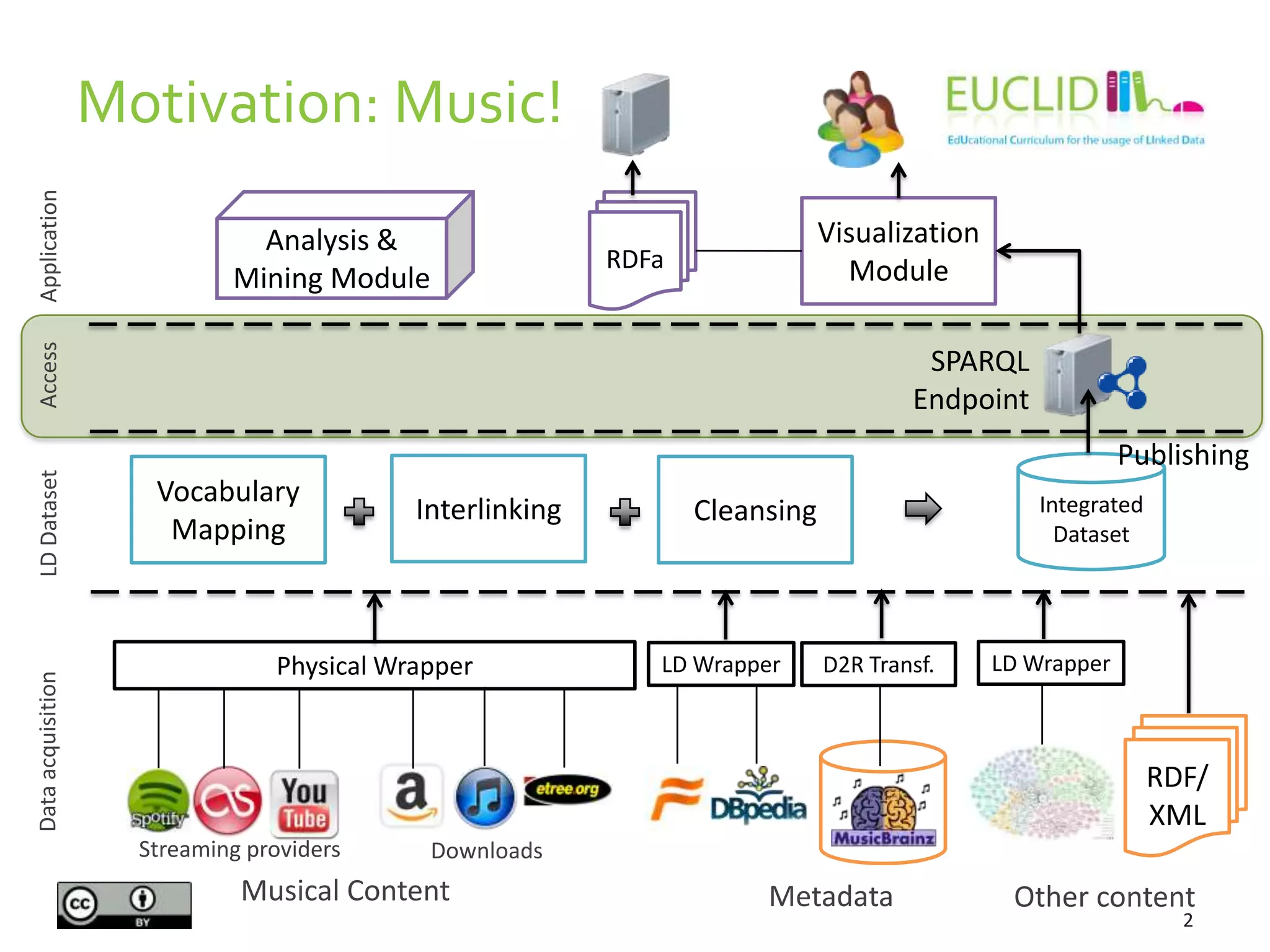
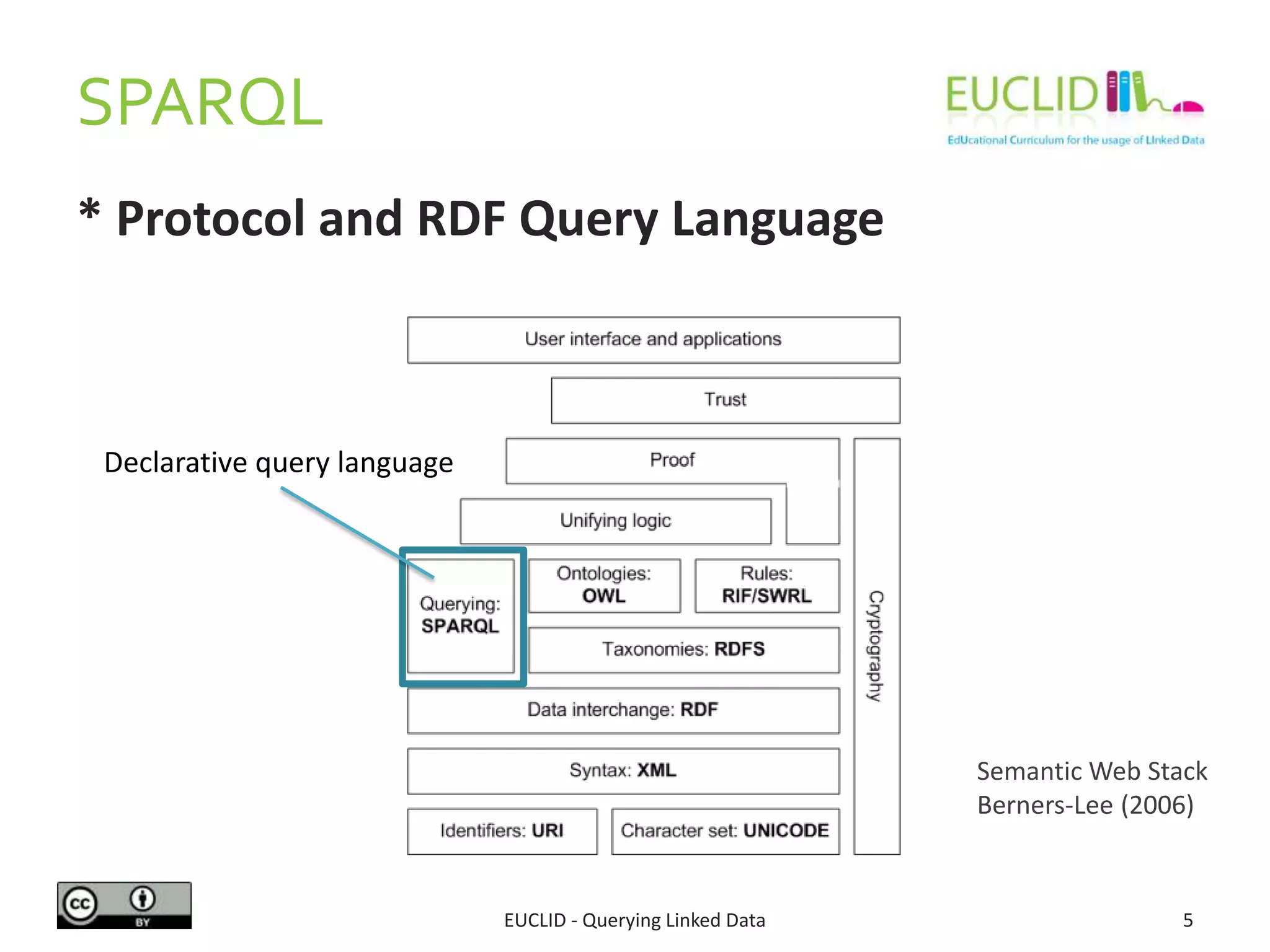
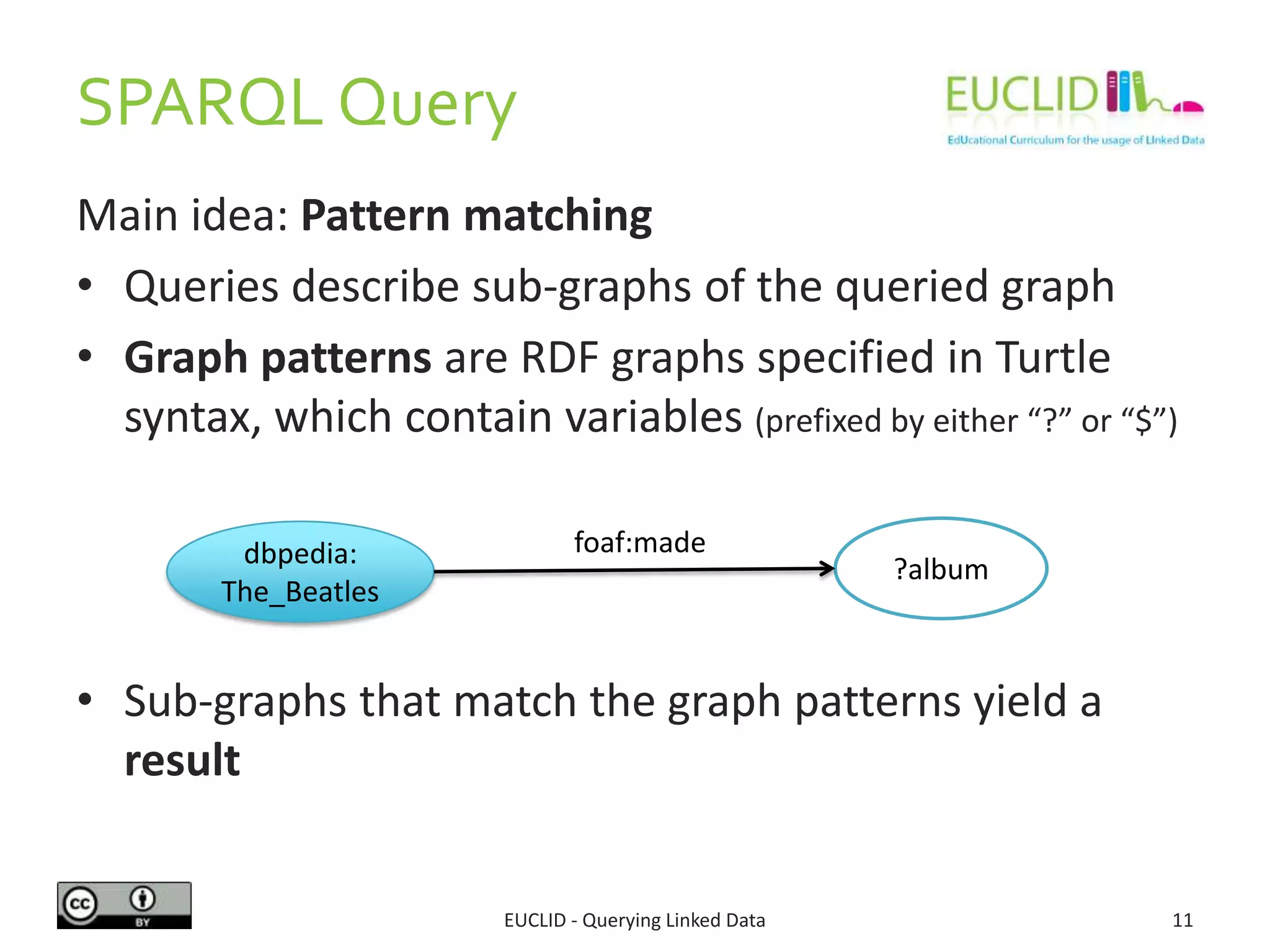
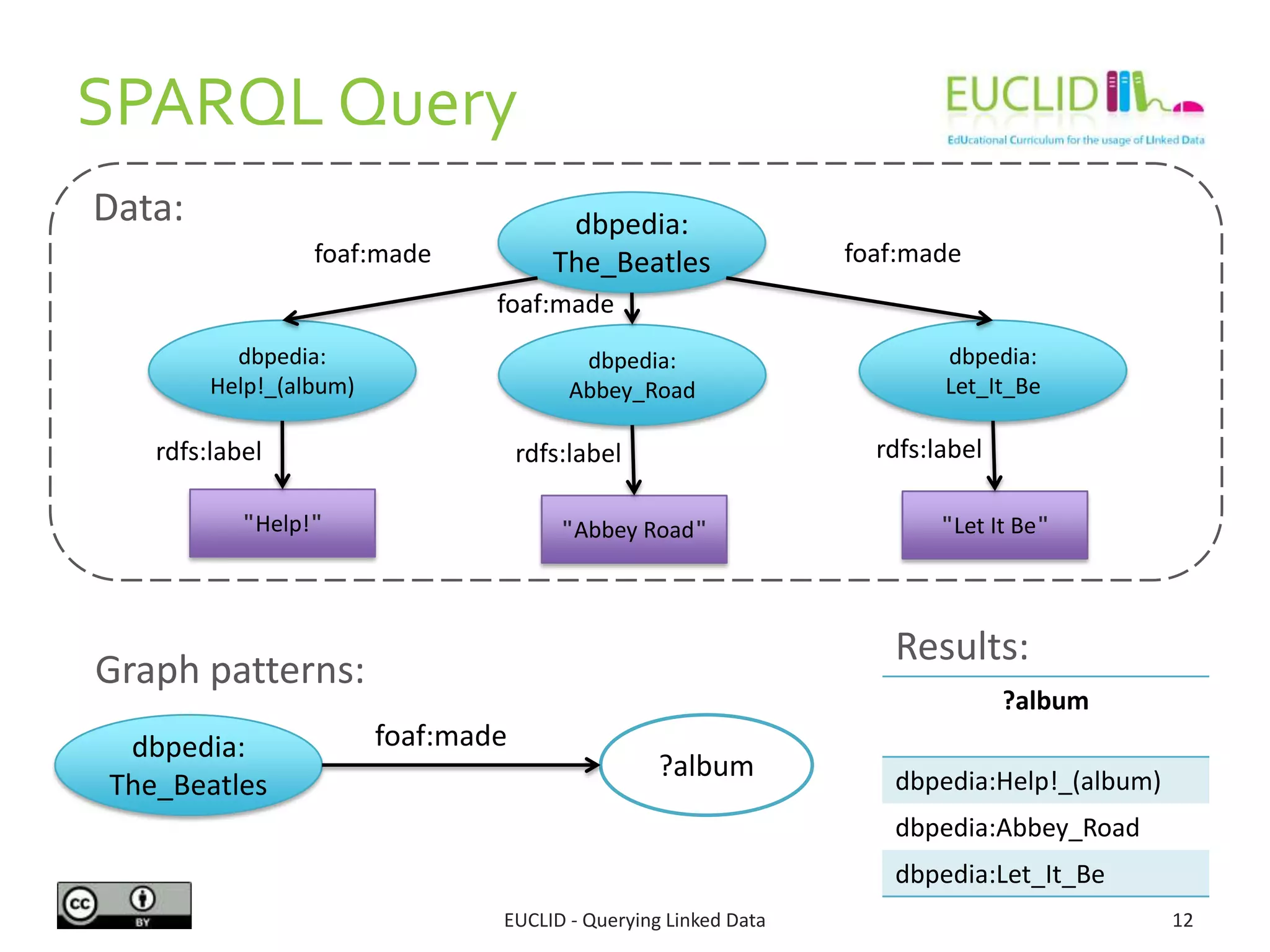
The document provides an overview of querying linked data using SPARQL, including its syntax, features, and capabilities for RDF data manipulation. It covers various aspects such as query forms (select, ask, describe, construct), filters, aggregates, and data management operations introduced in SPARQL 1.1. Additionally, it offers examples related to music content, demonstrating how to structure queries to retrieve information about artists and albums.























































































