Downloaded 11 times


![Introduction
The Semantic Web, as originally envisioned, is a system that enables
machines to "understand" and respond to complex human requests
based on their meaning. Such an "understanding" requires that the
relevant information sources be semantically structured.
Tim Berners-Lee originally expressed the vision of the Semantic Web as
follows:
I have a dream for the Web [in which computers] become capable of analysing all the
data on the Web – the content, links, and transactions between people and
computers. A "Semantic Web", which makes this possible, has yet to emerge, but
when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives
will be handled by machines talking to machines.](https://image.slidesharecdn.com/semanticweb-151207200843-lva1-app6891/85/A-Little-SPARQL-in-your-Analytics-2-320.jpg)



![RDF Representation
@prefix p: <http://www.example.org/personal_details#> .
@prefix m: <http://www.example.org/meeting_organization#> .
@prefix g: <http://www.another.example.org/geographical#>
<http://www.example.org/people#fred>
p:GivenName "fred";
p:hasEmail <mailto:fred@example.com>;
m:attending <http://meetings.example.com/cal#m1> .
<http://meetings.example.com/cal#m1> g:Location [
g:zip "02139";
g:lat "14.124425";
g:long "14.245" ];
<http://meetings.example.com/cal#m1> m:homePage <http://meetings.example.com/m1/hp>
“14.124425".
g:zip
g:lat
g:long
“02139".
“14.245".
http://meetings.example.com/cal#m1
g:location
CURIE](https://image.slidesharecdn.com/semanticweb-151207200843-lva1-app6891/85/A-Little-SPARQL-in-your-Analytics-9-320.jpg)


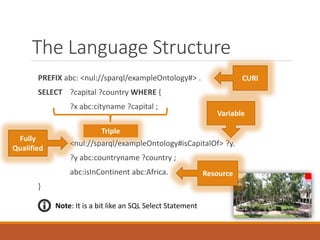
![SPARQL
SPARQL(pronounced "sparkle", a recursive
acronym[2] for SPARQL Protocol and RDF Query Language) is an RDF
query language, that is, a semantic query language for databases, able
to retrieve and manipulate data stored in Resource Description
Framework (RDF) format. It was made a standard by the RDF Data
Access Working Group (DAWG) of the World Wide Web Consortium, and
is recognized as one of the key technologies of the semantic web. On 15
January 2008, SPARQL 1.0 became an official W3C
Recommendation, and SPARQL 1.1 in March, 2013.
Note: Source Wikipedia](https://image.slidesharecdn.com/semanticweb-151207200843-lva1-app6891/85/A-Little-SPARQL-in-your-Analytics-13-320.jpg)








![Property Paths
Syntax Form Matches
uri
A URI or a prefixed name. A path
of length one.
^elt Inverse path (object to subject).
(elt)
A group path elt, brackets control
precedence.
elt1 / elt2
A sequence path of elt1, followed
by elt2
elt1 ^ elt2
Shorthand for elt1 / ^elt2, that
is elt1 followed by the inverse
of elt2.
elt1 | elt2
A alternative path of elt1,
or elt2 (all possibilities are tried).
elt*
A path of zero or more
occurrences of elt.
elt+
A path of one or more occurrences
of elt.
elt? A path of zero or one elt.
elt{n,m}
A path between n and m
occurrences of elt.
elt{n}
Exactly n occurrences of elt. A
fixed length path.
elt{n,} n or more occurrences of elt.
elt{,n}
Between 0 and n occurrences
of elt.
SELECT ?value WHERE {
:list rdf:rest* []
[] rdf:first ?value
}
Note: Note the use [] this tells
the SPARQL parser that the triples
share a common resource.](https://image.slidesharecdn.com/semanticweb-151207200843-lva1-app6891/85/A-Little-SPARQL-in-your-Analytics-27-320.jpg)









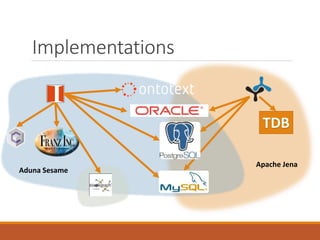





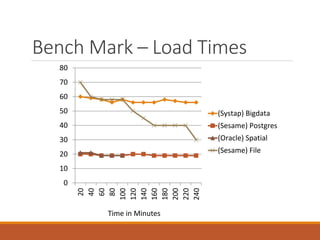




The document discusses Semantic Web technologies including RDF, SPARQL and ontologies. It provides: 1) An introduction to the Semantic Web vision of machines being able to understand and respond to complex requests based on meaning. This requires information to be semantically structured. 2) A brief overview of key concepts in RDF including triples, nodes, blank nodes, and predefined RDF structures like bags and lists. 3) An explanation of the SPARQL query language, which is similar to SQL but interrogates the Semantic Web. SPARQL clauses like SELECT, CONSTRUCT, DESCRIBE and ASK are covered. 4) A discussion of ontological representations including R



















































































