Downloaded 18 times




























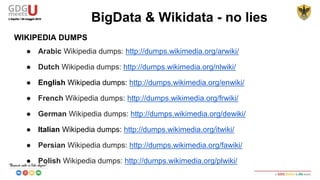
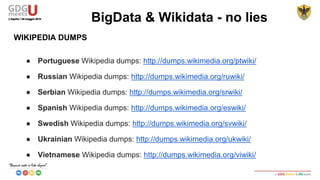
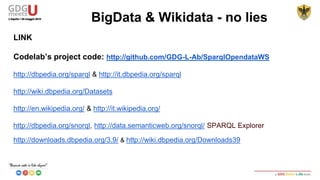
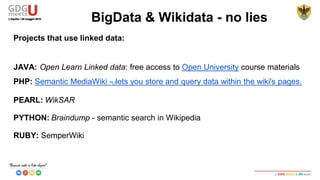

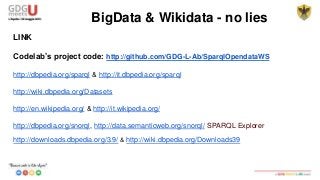
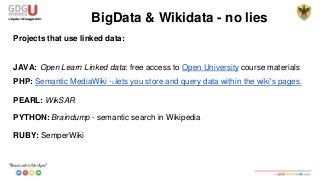


This document discusses using SPARQL to query RDF data from DBPedia. It provides an overview of key concepts like RDF triples, SPARQL, and Apache Jena framework. It also includes a sample SPARQL query to retrieve cities in Abruzzo, Italy with a population over 50,000. Resources and prefixes for working with DBPedia, Wikidata, and other linked data sets are listed.





























































































