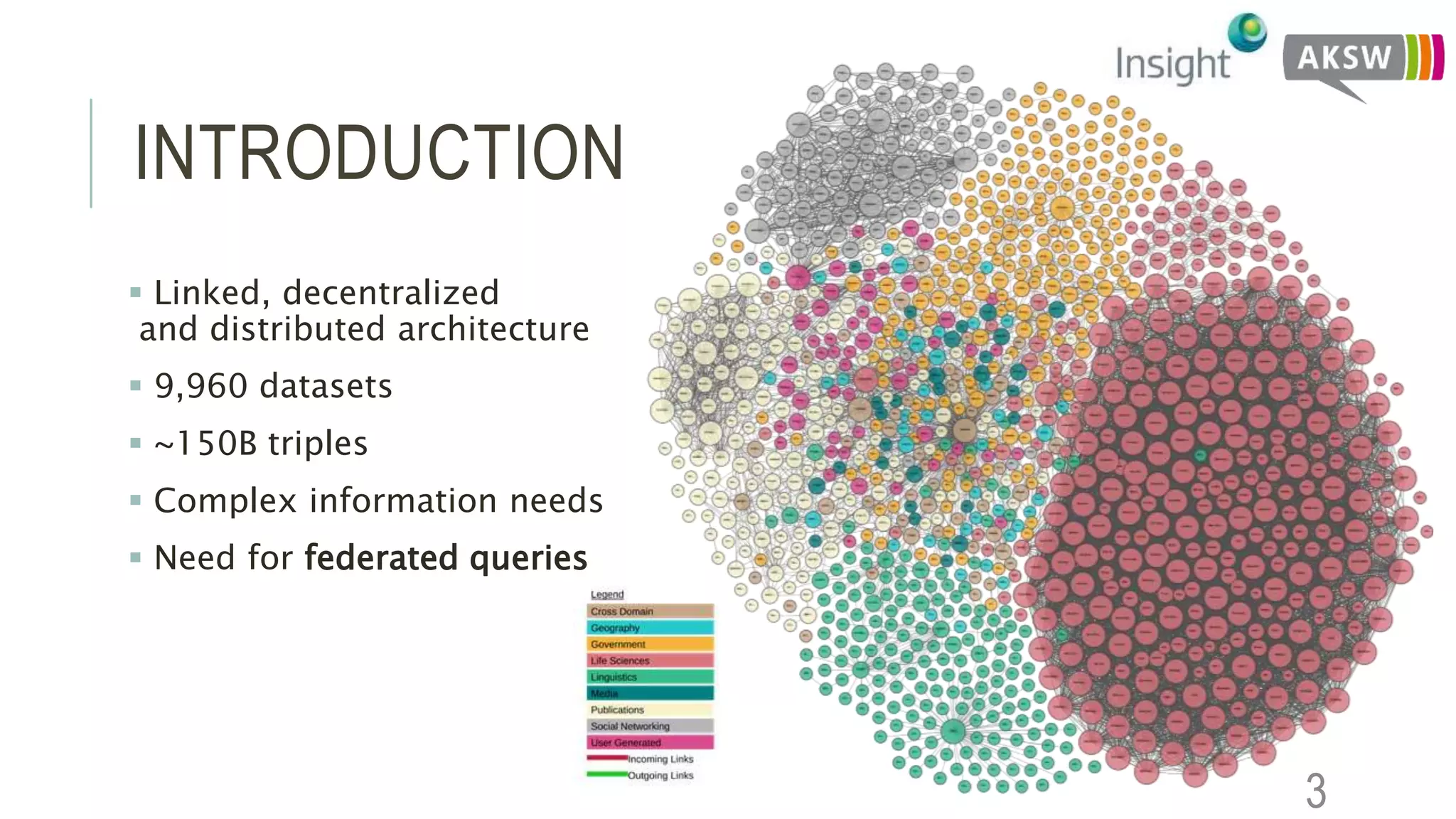
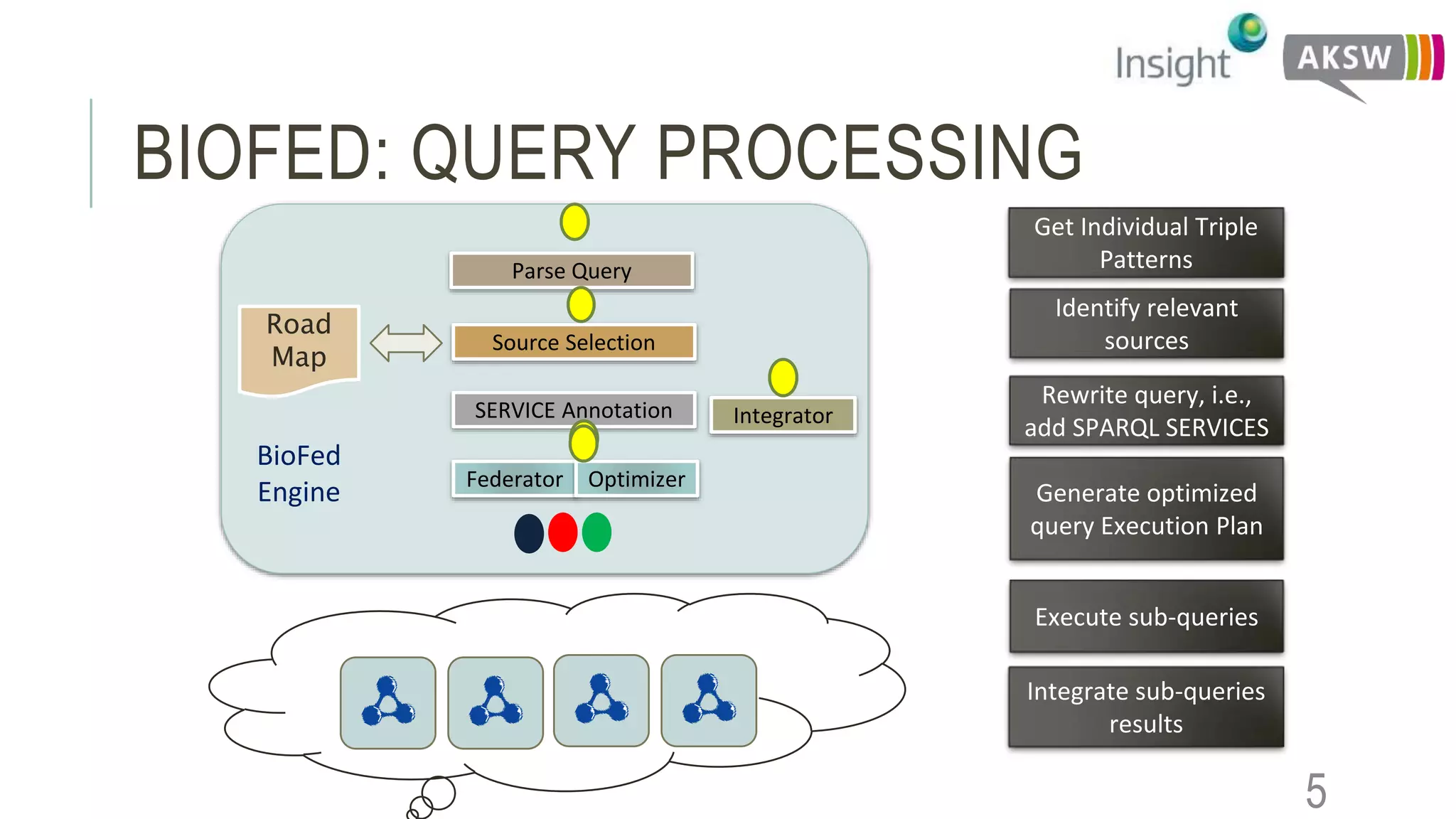
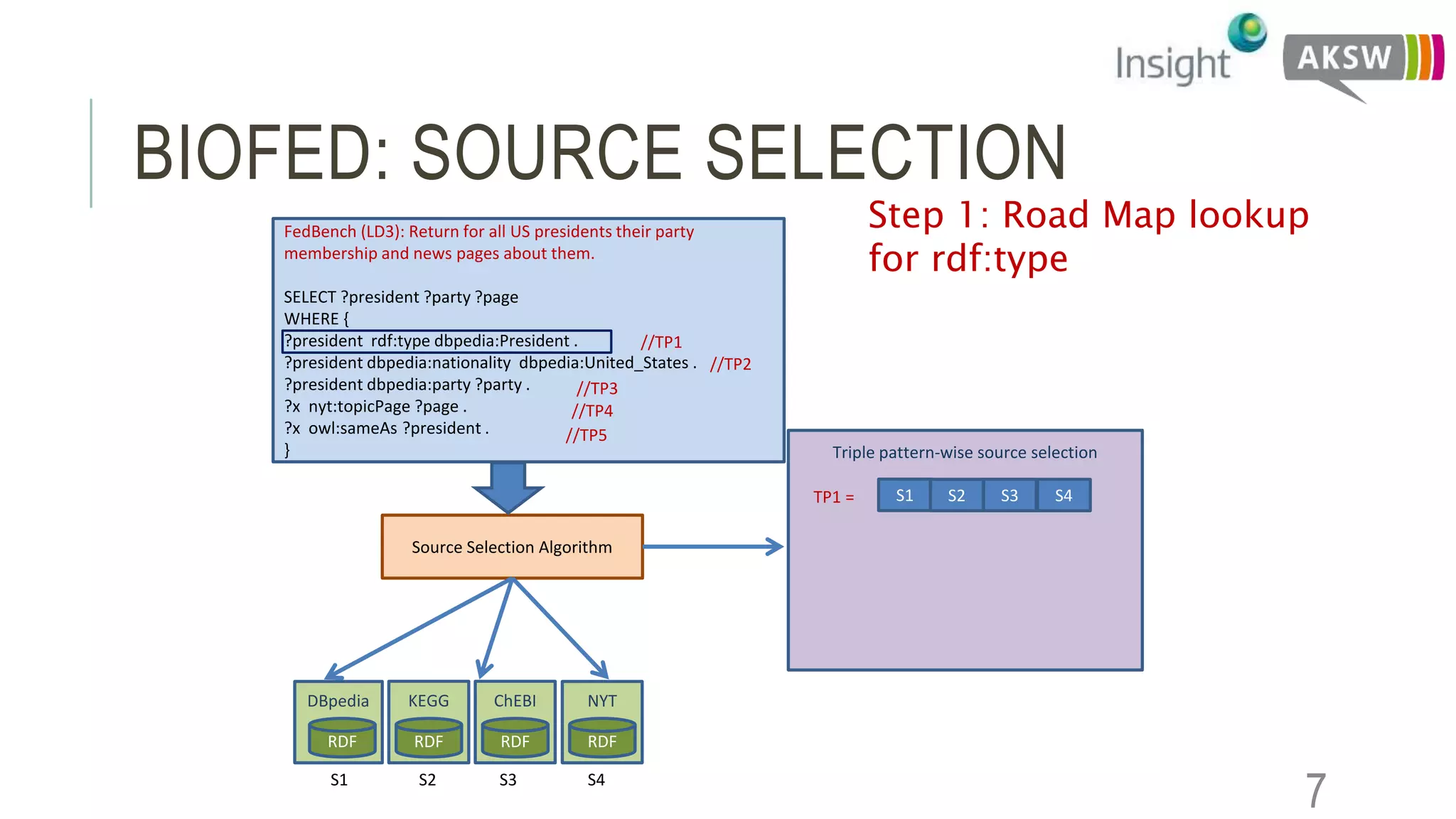
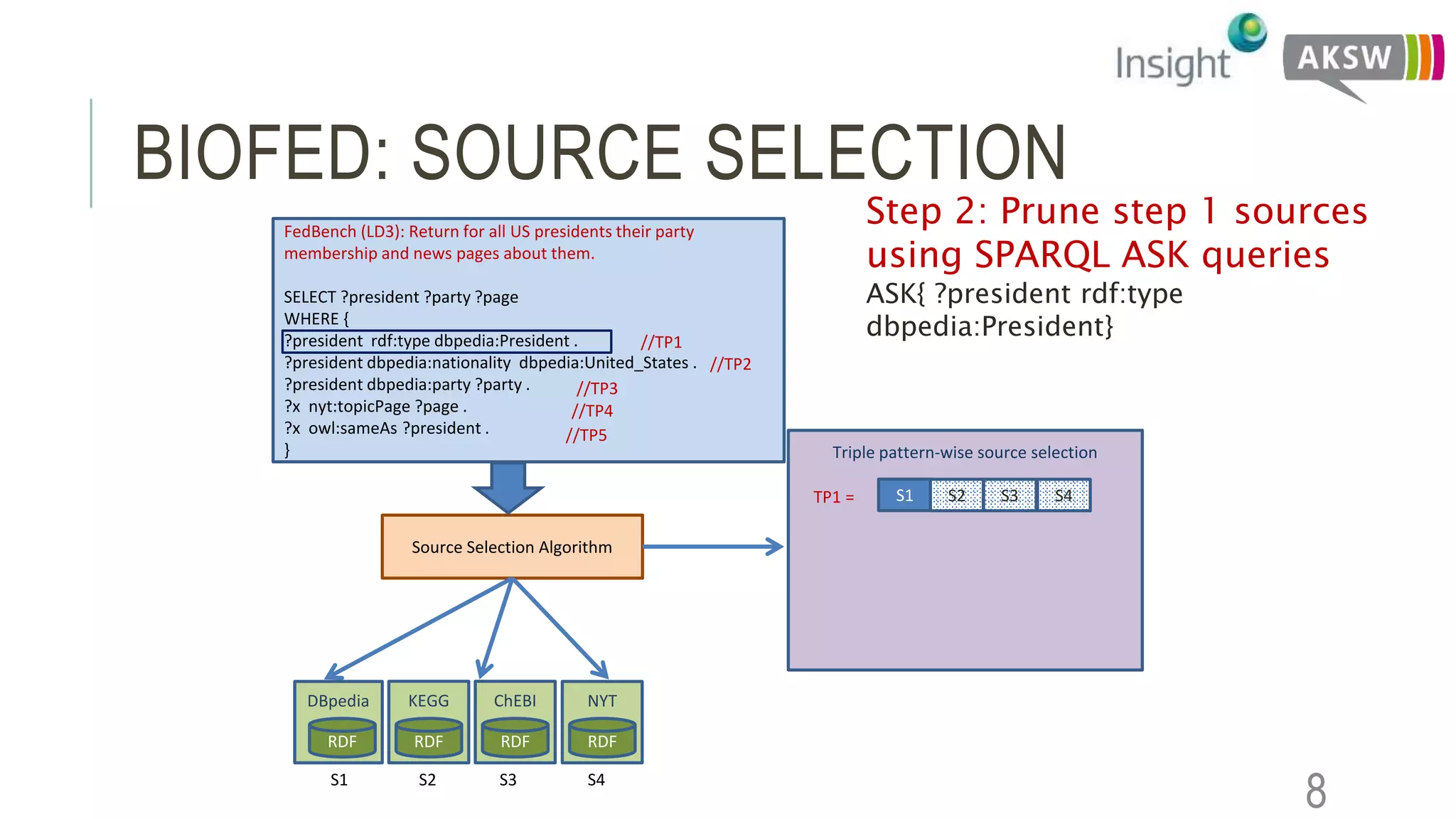
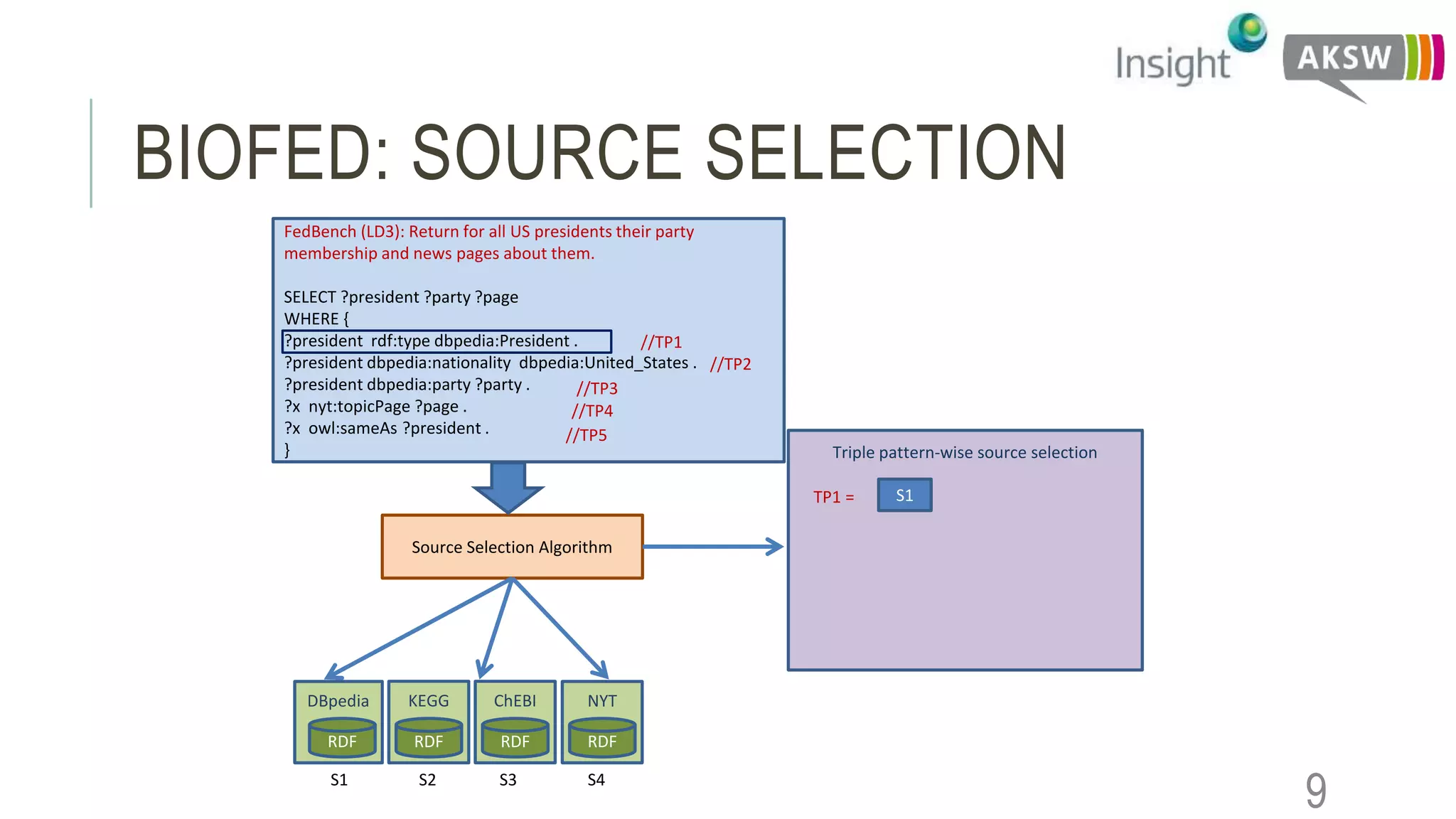
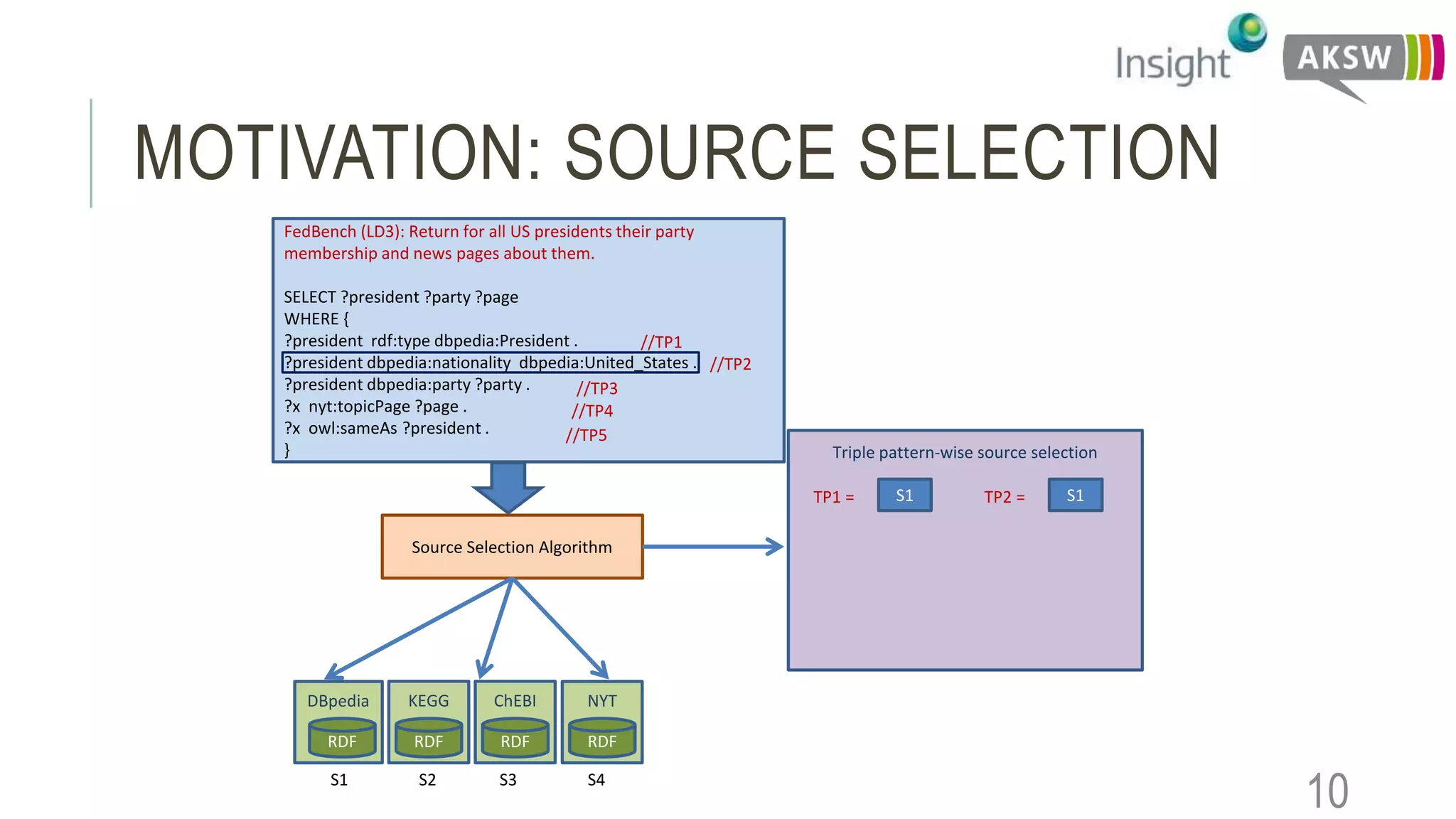
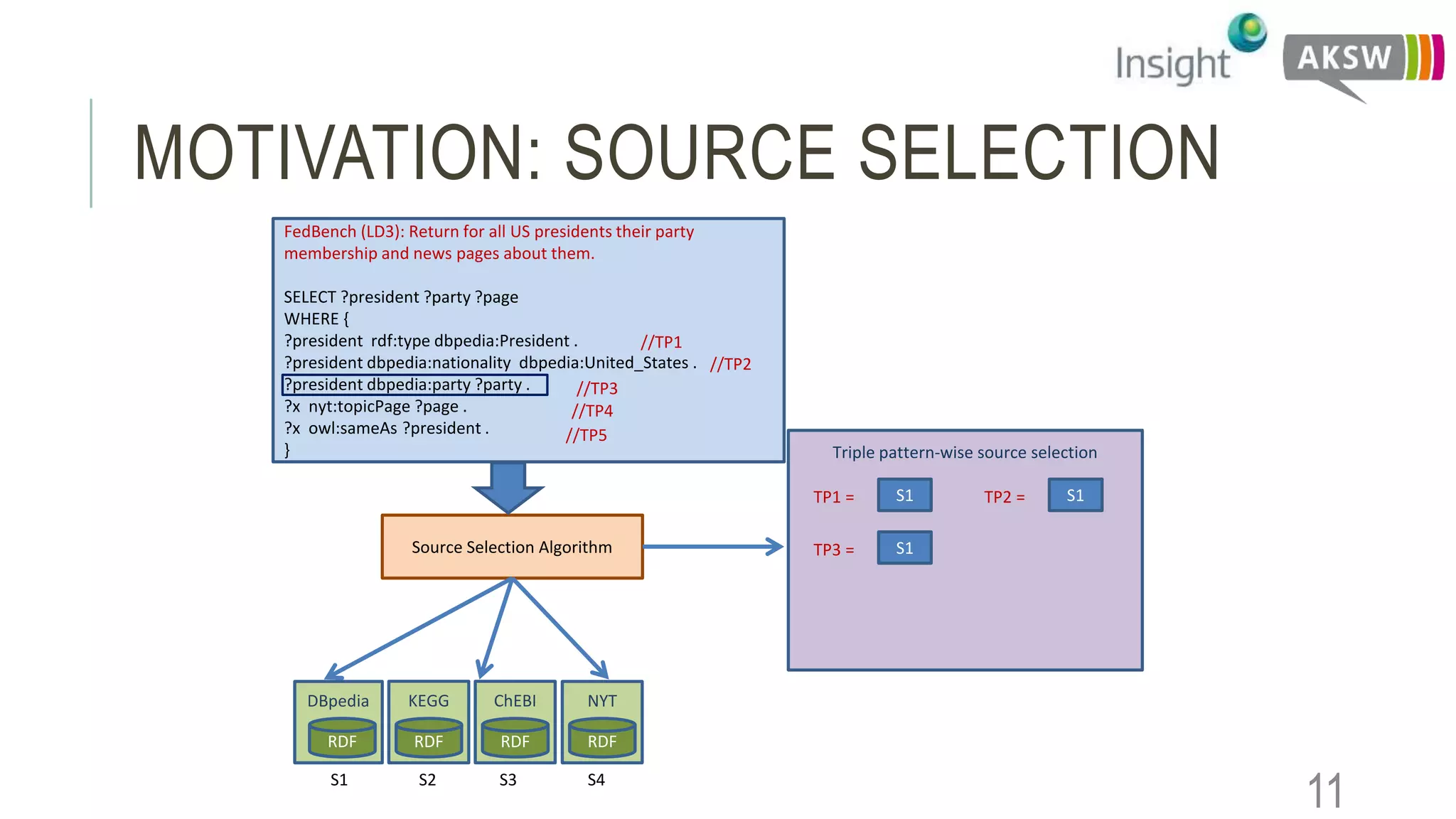
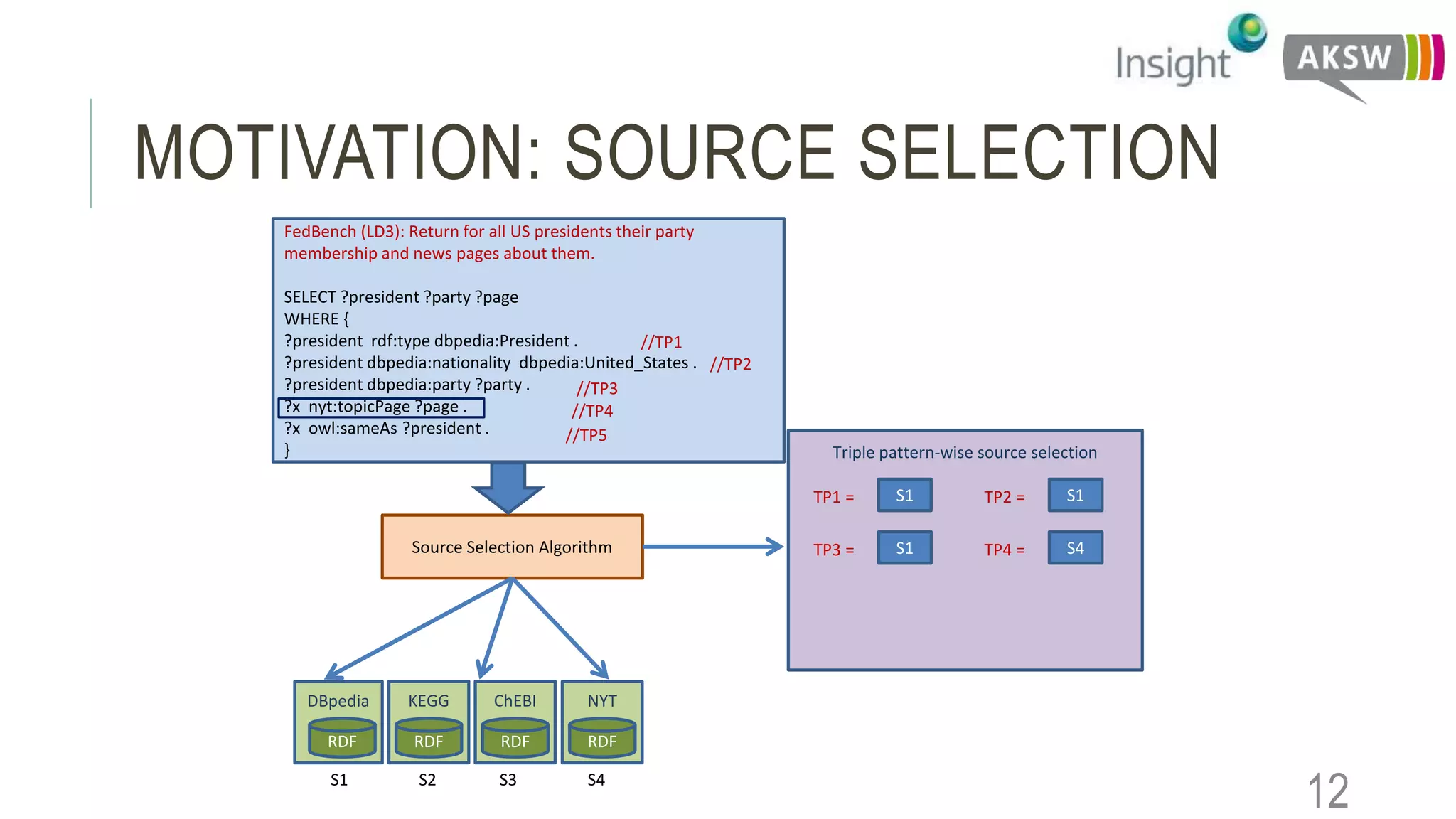
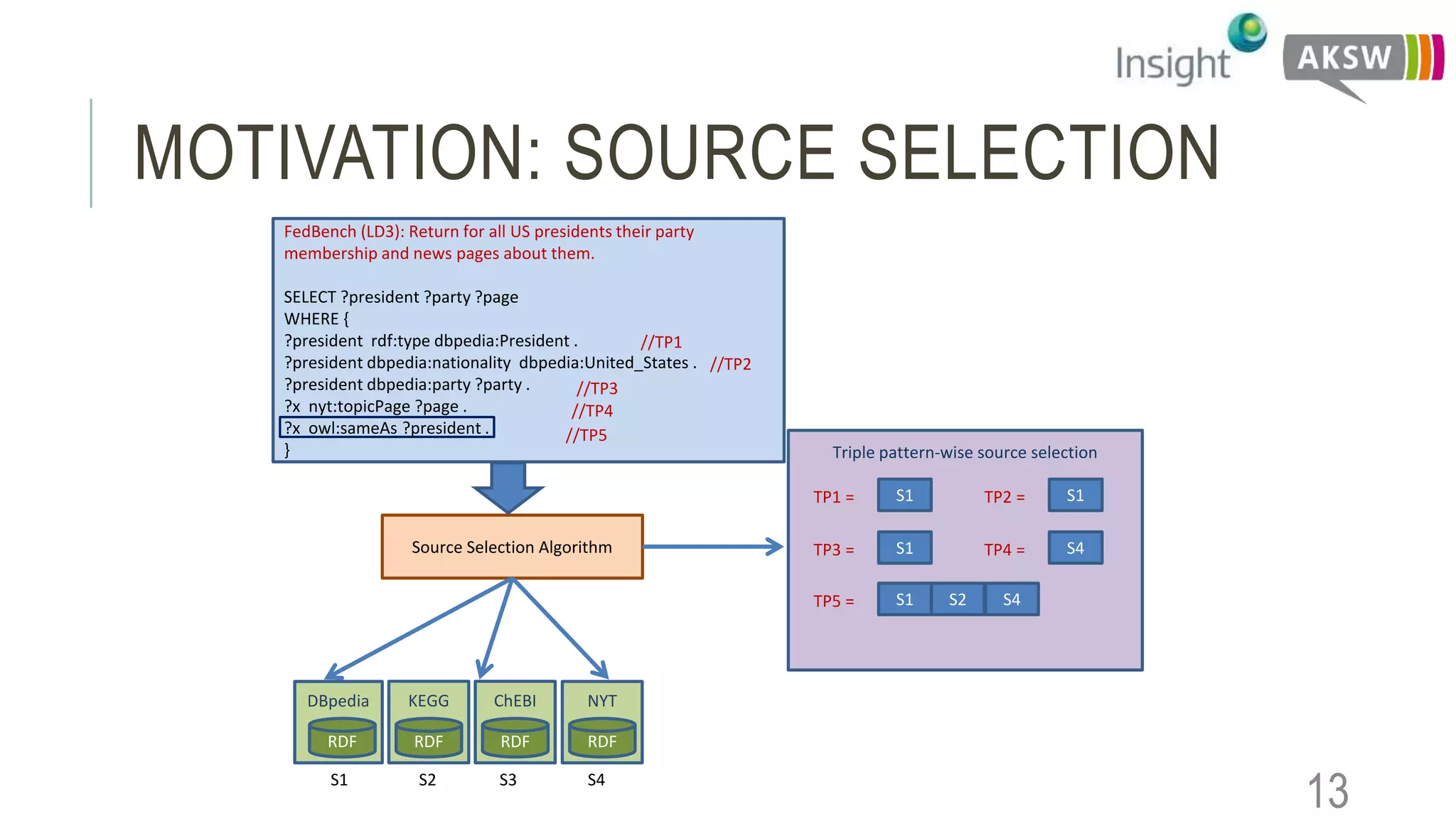
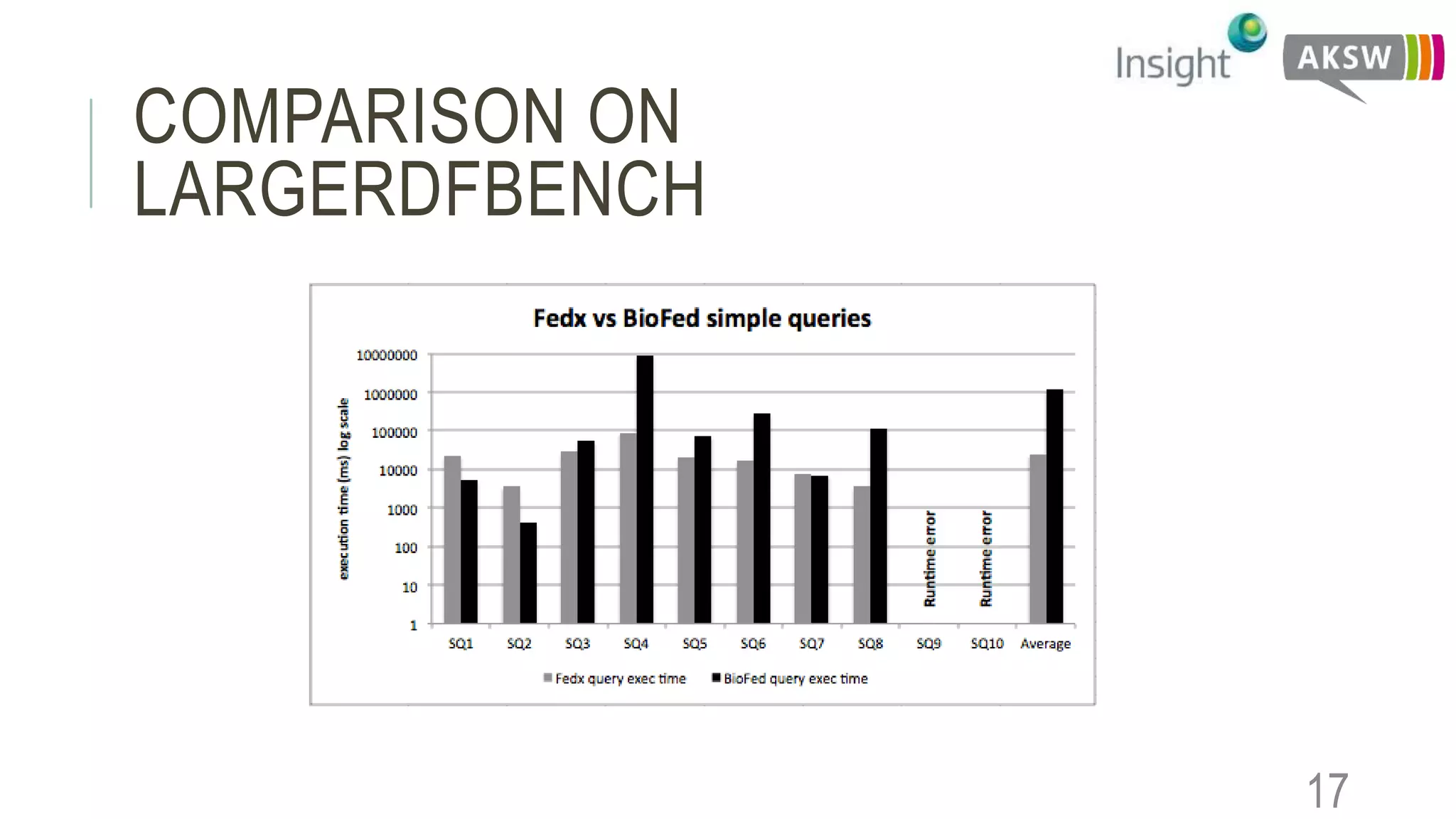
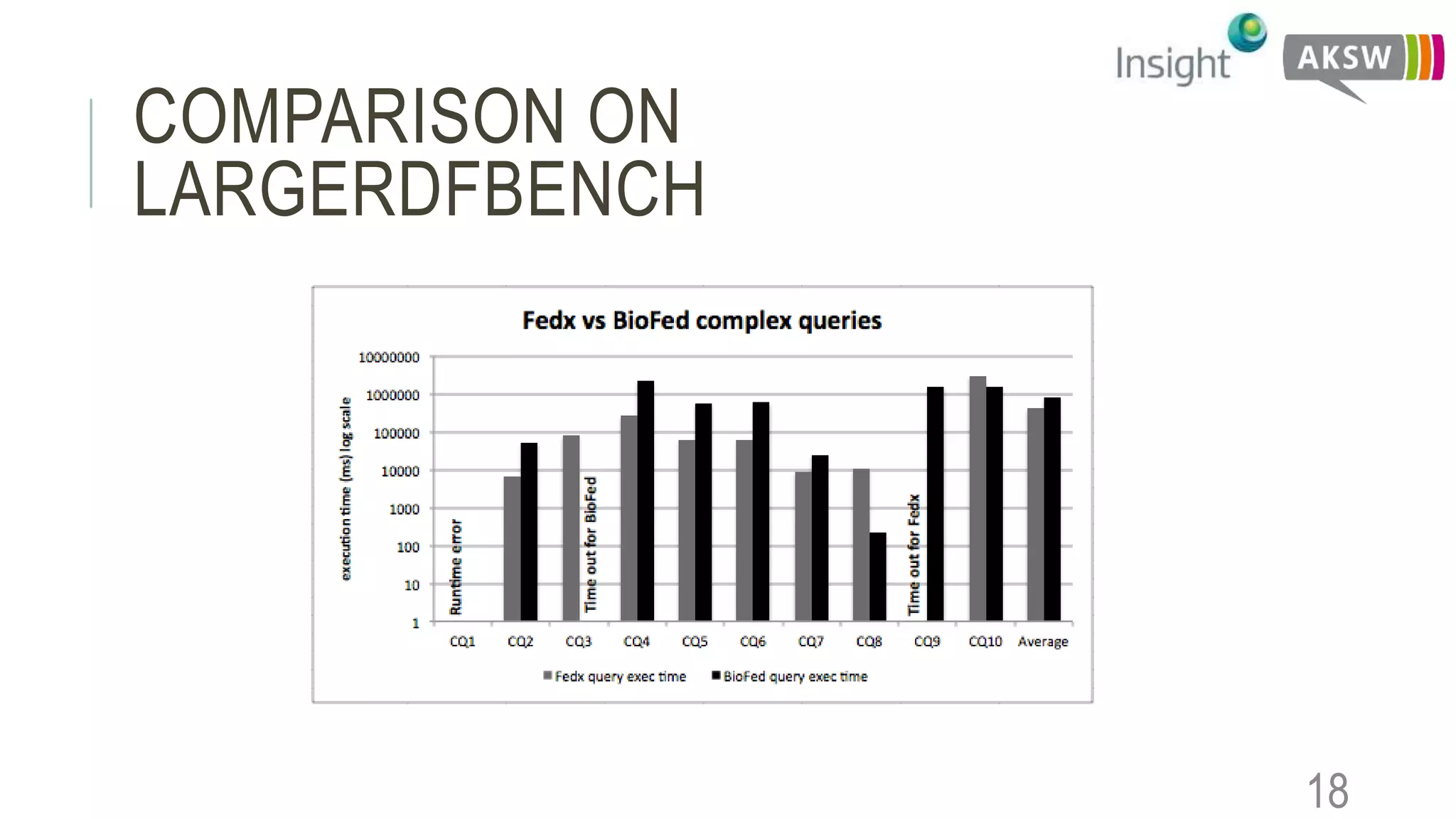
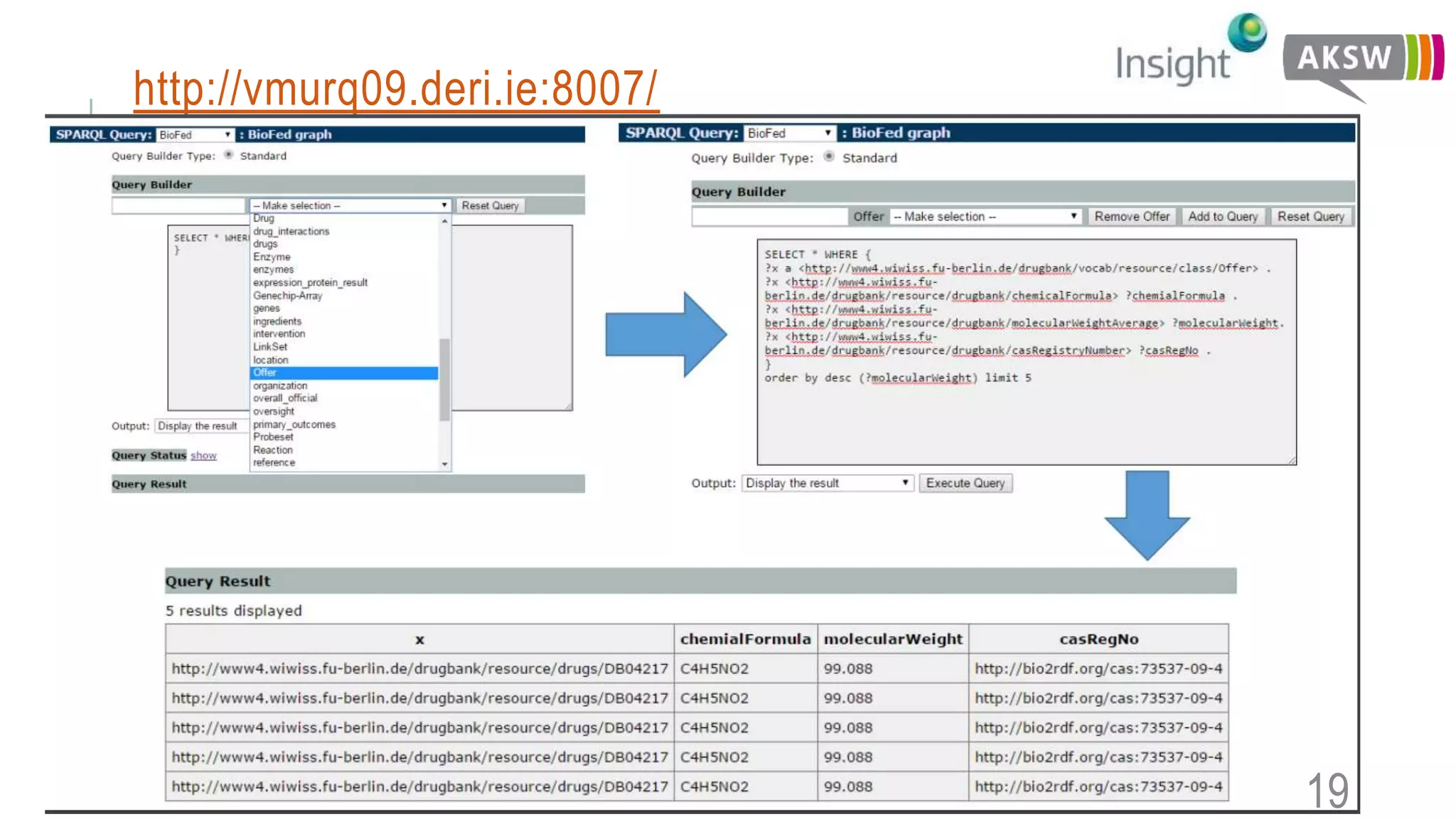
This document discusses the SEWEBMEDA workshop and focuses on federated query formulation and processing using BioFed for large-scale biomedical data analytics. It outlines the architecture, source selection algorithms, and query rewriting methodologies for effective federated queries to access diverse datasets. The examples provided illustrate how to retrieve information about US presidents' party memberships and related news using SPARQL queries.