Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
NS
Uploaded by
NTT DATA OSS Professional Services
6,383 views
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
『Hadoop Conference Japan 2011 Fall』での講演資料。 NTTデータ 基盤システム事業本部 OSSプロフェッショナルサービス 猿田 浩輔
Technology
◦
Read more
25
Save
Share
Embed
Embed presentation
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
Apache Bigtop3.2 (仮)(Open Source Conference 2022 Online/Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
単なるキャッシュじゃないよ!?infinispanの紹介
by
AdvancedTechNight
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PPTX
BigtopでHadoopをビルドする(Open Source Conference 2021 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
PPTX
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
PDF
レプリケーション遅延の監視について(第40回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Apache Bigtop3.2 (仮)(Open Source Conference 2022 Online/Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
単なるキャッシュじゃないよ!?infinispanの紹介
by
AdvancedTechNight
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
BigtopでHadoopをビルドする(Open Source Conference 2021 Online/Spring 発表資料)
by
NTT DATA Technology & Innovation
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
レプリケーション遅延の監視について(第40回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
What's hot
PDF
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
Oracle GoldenGate入門
by
オラクルエンジニア通信
PPTX
Dockerからcontainerdへの移行
by
Akihiro Suda
PDF
より速く より運用しやすく 進化し続けるJVM(Java Developers Summit Online 2023 発表資料)
by
NTT DATA Technology & Innovation
PDF
トランザクション処理可能な分散DB 「YugabyteDB」入門(Open Source Conference 2022 Online/Fukuoka 発...
by
NTT DATA Technology & Innovation
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
Hadoop入門
by
Preferred Networks
PDF
Docker Compose 徹底解説
by
Masahito Zembutsu
PDF
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
by
Yahoo!デベロッパーネットワーク
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PPTX
マルチクラウドDWH(Snowflake)のすすめ
by
Yuuta Hishinuma
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PPTX
PostgreSQLのfull_page_writesについて(第24回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PPTX
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス...
by
NTT DATA Technology & Innovation
PDF
Apache Airflow 概要(Airflowの基礎を学ぶハンズオンワークショップ 発表資料)
by
NTT DATA Technology & Innovation
PDF
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
by
Preferred Networks
PDF
OpenStackで始めるクラウド環境構築入門(Horizon 基礎編)
by
VirtualTech Japan Inc.
PDF
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
Oracle GoldenGate入門
by
オラクルエンジニア通信
Dockerからcontainerdへの移行
by
Akihiro Suda
より速く より運用しやすく 進化し続けるJVM(Java Developers Summit Online 2023 発表資料)
by
NTT DATA Technology & Innovation
トランザクション処理可能な分散DB 「YugabyteDB」入門(Open Source Conference 2022 Online/Fukuoka 発...
by
NTT DATA Technology & Innovation
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Hadoop入門
by
Preferred Networks
Docker Compose 徹底解説
by
Masahito Zembutsu
実運用して分かったRabbit MQの良いところ・気をつけること #jjug
by
Yahoo!デベロッパーネットワーク
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
マルチクラウドDWH(Snowflake)のすすめ
by
Yuuta Hishinuma
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PostgreSQLのfull_page_writesについて(第24回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
オンライン物理バックアップの排他モードと非排他モードについて ~PostgreSQLバージョン15対応版~(第34回PostgreSQLアンカンファレンス...
by
NTT DATA Technology & Innovation
Apache Airflow 概要(Airflowの基礎を学ぶハンズオンワークショップ 発表資料)
by
NTT DATA Technology & Innovation
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
by
Preferred Networks
OpenStackで始めるクラウド環境構築入門(Horizon 基礎編)
by
VirtualTech Japan Inc.
pg_hint_planを知る(第37回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Viewers also liked
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
Hadoopの概念と基本的知識
by
Ken SASAKI
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PDF
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
PPTX
Hadoopトレーニング番外編 〜間違えられやすいHadoopの7つの仕様〜
by
Cloudera Japan
PDF
OpenStack, Hadoop -- OSSクラウドの最新動向
by
Masanori Itoh
PDF
IBM版Hadoop - BigInsights/Big SQL (2013/07/26 CLUB DB2発表資料)
by
Akira Shimosako
PPT
はやわかりHadoop
by
Shinpei Ohtani
PPT
Yahoo! JAPANでのHadoop利用について
by
Yahoo!デベロッパーネットワーク
PDF
Hadoop最新情報 - YARN, Omni, Drill, Impala, Shark, Vertica - MapR CTO Meetup 2014...
by
MapR Technologies Japan
PDF
オラクルのHadoopソリューションご紹介
by
オラクルエンジニア通信
PDF
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
PDF
SQL on Hadoop 比較検証 【2014月11日における検証レポート】
by
NTT DATA OSS Professional Services
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PDF
日々進化するHadoopの 「いま」
by
NTT DATA OSS Professional Services
PDF
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
PDF
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
PPTX
Mobageのhadoop活用環境と適用方法
by
show you
PDF
.NET Micro Framework の基礎
by
Yoshitaka Seo
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
Hadoopの概念と基本的知識
by
Ken SASAKI
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
Hadoopトレーニング番外編 〜間違えられやすいHadoopの7つの仕様〜
by
Cloudera Japan
OpenStack, Hadoop -- OSSクラウドの最新動向
by
Masanori Itoh
IBM版Hadoop - BigInsights/Big SQL (2013/07/26 CLUB DB2発表資料)
by
Akira Shimosako
はやわかりHadoop
by
Shinpei Ohtani
Yahoo! JAPANでのHadoop利用について
by
Yahoo!デベロッパーネットワーク
Hadoop最新情報 - YARN, Omni, Drill, Impala, Shark, Vertica - MapR CTO Meetup 2014...
by
MapR Technologies Japan
オラクルのHadoopソリューションご紹介
by
オラクルエンジニア通信
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
SQL on Hadoop 比較検証 【2014月11日における検証レポート】
by
NTT DATA OSS Professional Services
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
日々進化するHadoopの 「いま」
by
NTT DATA OSS Professional Services
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
Mobageのhadoop活用環境と適用方法
by
show you
.NET Micro Framework の基礎
by
Yoshitaka Seo
Similar to NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PDF
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
PDF
マイニング探検会#10
by
Yoji Kiyota
PPTX
ビッグデータ&データマネジメント展
by
Recruit Technologies
PPT
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
PPTX
WebDB Forum 2012 基調講演資料
by
Recruit Technologies
PDF
OSC2012 OSC.DB Hadoop
by
Shinichi YAMASHITA
PDF
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
PDF
OSC2012 Tokyo/Spring - Hadoop入門
by
Shinichi YAMASHITA
PPTX
ビッグデータ活用支援フォーラム
by
Recruit Technologies
PPT
Hadoop~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
PDF
AI・HPC・ビッグデータで利用される分散ファイルシステムを知る
by
日本ヒューレット・パッカード株式会社
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
PDF
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
by
オラクルエンジニア通信
PDF
Yahoo! JAPAN MeetUp #8 (インフラ技術カンファレンス)セッション②
by
Yahoo!デベロッパーネットワーク
PDF
ストリームデータ分散処理基盤Storm
by
NTT DATA OSS Professional Services
PDF
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
PDF
Hadoop Hack Night Vol. 2
by
Yoji Kiyota
PDF
OSC2011 Tokyo/Spring Hadoop入門
by
Shinichi YAMASHITA
PPTX
Hadoop Compatible File Systems (Azure編) (セミナー「Big Data Developerに贈る第二弾 ‐ Azur...
by
NTT DATA Technology & Innovation
Cloudera大阪セミナー 20130219
by
Cloudera Japan
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
マイニング探検会#10
by
Yoji Kiyota
ビッグデータ&データマネジメント展
by
Recruit Technologies
Hadoop ~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
WebDB Forum 2012 基調講演資料
by
Recruit Technologies
OSC2012 OSC.DB Hadoop
by
Shinichi YAMASHITA
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
OSC2012 Tokyo/Spring - Hadoop入門
by
Shinichi YAMASHITA
ビッグデータ活用支援フォーラム
by
Recruit Technologies
Hadoop~Yahoo! JAPANの活用について~
by
Yahoo!デベロッパーネットワーク
AI・HPC・ビッグデータで利用される分散ファイルシステムを知る
by
日本ヒューレット・パッカード株式会社
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
Hadoop Conference Japan_2016 セッション「顧客事例から学んだ、 エンタープライズでの "マジな"Hadoop導入の勘所」
by
オラクルエンジニア通信
Yahoo! JAPAN MeetUp #8 (インフラ技術カンファレンス)セッション②
by
Yahoo!デベロッパーネットワーク
ストリームデータ分散処理基盤Storm
by
NTT DATA OSS Professional Services
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
Hadoop Hack Night Vol. 2
by
Yoji Kiyota
OSC2011 Tokyo/Spring Hadoop入門
by
Shinichi YAMASHITA
Hadoop Compatible File Systems (Azure編) (セミナー「Big Data Developerに贈る第二弾 ‐ Azur...
by
NTT DATA Technology & Innovation
More from NTT DATA OSS Professional Services
PDF
Global Top 5 を目指す NTT DATA の確かで意外な技術力
by
NTT DATA OSS Professional Services
PDF
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
PDF
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
PDF
HDFS Router-based federation
by
NTT DATA OSS Professional Services
PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
PDF
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
PDF
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
PDF
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
PDF
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
PDF
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
PDF
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~
by
NTT DATA OSS Professional Services
PDF
20170303 java9 hadoop
by
NTT DATA OSS Professional Services
PPTX
ブロックチェーンの仕組みと動向(入門編)
by
NTT DATA OSS Professional Services
PDF
Application of postgre sql to large social infrastructure jp
by
NTT DATA OSS Professional Services
PDF
Application of postgre sql to large social infrastructure
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop 2.8.0 の新機能 (抜粋)
by
NTT DATA OSS Professional Services
PDF
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
PDF
商用ミドルウェアのPuppet化で気を付けたい5つのこと
by
NTT DATA OSS Professional Services
PPTX
今からはじめるPuppet 2016 ~ インフラエンジニアのたしなみ ~
by
NTT DATA OSS Professional Services
Global Top 5 を目指す NTT DATA の確かで意外な技術力
by
NTT DATA OSS Professional Services
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
HDFS Router-based federation
by
NTT DATA OSS Professional Services
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~
by
NTT DATA OSS Professional Services
20170303 java9 hadoop
by
NTT DATA OSS Professional Services
ブロックチェーンの仕組みと動向(入門編)
by
NTT DATA OSS Professional Services
Application of postgre sql to large social infrastructure jp
by
NTT DATA OSS Professional Services
Application of postgre sql to large social infrastructure
by
NTT DATA OSS Professional Services
Apache Hadoop 2.8.0 の新機能 (抜粋)
by
NTT DATA OSS Professional Services
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
商用ミドルウェアのPuppet化で気を付けたい5つのこと
by
NTT DATA OSS Professional Services
今からはじめるPuppet 2016 ~ インフラエンジニアのたしなみ ~
by
NTT DATA OSS Professional Services
Recently uploaded
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
PPTX
ddevについて .
by
iPride Co., Ltd.
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
by
法林浩之
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
PDF
Drupal Recipes 解説 .
by
iPride Co., Ltd.
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector
by
akipii ogaoga
ddevについて .
by
iPride Co., Ltd.
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis
by
akipii ogaoga
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版
by
sorabatake
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望
by
CRI Japan, Inc.
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」
by
嶋 是一 (Yoshikazu SHIMA)
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜
by
法林浩之
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信
by
e-Patent Co., Ltd.
Drupal Recipes 解説 .
by
iPride Co., Ltd.
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
1.
2011年9月26日
Hadoop Conference Japan 2011 Fall 講演資料 NTTデータ流Hadoop活用のすヽめ ~インフラ構築・運用の勘所~ 株式会社NTTデータ 基盤システム事業本部 OSSプロフェッショナルサービス 猿田 浩輔 Copyright © 2011 NTT DATA CORPORATION
2.
自己紹介 氏名
猿田 浩輔 (さるた こうすけ) 所属 NTTデータ 基盤システム事業本部 OSSプロフェッショナルサービス 経歴 2009年度にNTTデータに入社 入社以来、OSSの検証/整備、案件への適用を行う 特に、Hadoopとその周辺技術の検証/整備や案件適用に従事 し、経済産業省からの委託業務の実証実験にも参画 http://www.meti.go.jp/policy/mono_info_service/joho/dow nloadfiles/2010software_research/clou_dist_software.pdf 2011年1月に「Hadoop徹底入門」を執筆 Copyright © 2011 NTT DATA CORPORATION 2
3.
Hadoop徹底入門、おかげさまで第3刷増刷決定です!
ありがとうございます! Copyright © 2011 NTT DATA CORPORATION 3
4.
Hadoopについておさらい Copyright © 2011
NTT DATA CORPORATION 4
5.
Hadoop クラスタの全体像 集中管理型の分散システム
Hadoopマスターノード 分散処理ジョブやデータの管 理はマスタノードで実施 スレーブノードは、分散処理の NameNode JobTracker 実行やデータの実体を保存 Hadoopクライアント スレーブノードのクラスタへの 参加・離脱は自動的 L2/L3スイッチ • 各ノードはマスターノードに定 期的に通知する Hadoopスレーブノード群 スレーブノードを増やすことで、 全体の処理性能を向上させる L2スイッチ スケールアウトアーキテクチャ HDFS マスター: NameNode スレーブ: DataNode DataNode DataNode DataNode DataNode DataNode MapReduce TaskTracker TaskTracker TaskTracker TaskTracker TaskTracker マスター: JobTracker ディスク ディスク ディスク ディスク ディスク スレーブ: TaskTracker Copyright © 2011 NTT DATA CORPORATION 5
6.
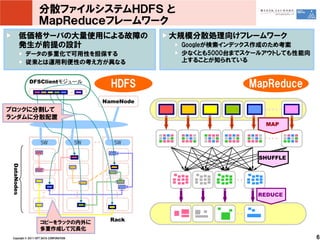
分散ファイルシステムHDFS と
MapReduceフレームワーク 低価格サーバの大量使用による故障の 大規模分散処理向けフレームワーク 発生が前提の設計 Googleが検索インデックス作成のため考案 データの多重化で可用性を担保する 少なくとも5000台までスケールアウトしても性能向 従来とは運用利便性の考え方が異なる 上することが知られている DFSClientモジュール HDFS MapReduce NameNode ブロックに分割して ランダムに分散配置 MAP SW SW SW SHUFFLE DataNodes REDUCE コピーをラックの内外に Rack 多重作成して冗長化 Copyright © 2011 NTT DATA CORPORATION 6
7.
本日お話しする内容 Copyright © 2011
NTT DATA CORPORATION 7
8.
Hadoopクラスタのインフラ構築・運用時に
よく挙がる話題 • Hadoopクラスタの可用性向上 マスターノードのSPOF排除の話題 • 数百台以上のサーバから構成される大規模クラスタの 効率的な運用 初期構築 設定変更 増設 障害復旧 これらの課題に対して、 一定の軸に基づいたアプローチが必要 Copyright © 2011 NTT DATA CORPORATION 8
9.
NTTデータにおけるHadoopへの取り組み
• NTTデータでは、2008年からHadoopに取り組み、数十台~千 台規模のHadoopクラスタを構築してきた実績を有する • 2009年には経済産業省からの委託で実施した実証実験にお いて、Hadoopクラスタの可用性確保の仕組みや、効率的な運 用のための自動構築・環境一元管理の技術を開発 これらの経験から得た知見をもとに Hadoopクラスタのインフラ構築・運用に関する ベストプラクティスをご紹介します Copyright © 2011 NTT DATA CORPORATION 9
10.
アジェンダ マスターノードの可用性向上の検討 大量サーバの運用効率化
クラスタのリソース情報の取得 [ネタ]:トポロジ設計 まとめ Copyright © 2011 NTT DATA CORPORATION 10
11.
マスターノードの
可用性向上の検討 Copyright © 2011 NTT DATA CORPORATION 11
12.
Hadoopには可用性向上の仕組みがいっぱい
MapReduce • スレーブノードに障害が発生しても、当該ノードが処理していたタスク はほかのスレーブノードが処理し、ジョブは継続する スレーブノードの障害が、ジョブ全体の失敗に波及することを回避 HDFS • ブロック(HDFS内のデータの断片)は、複数のスレーブノードに分散 してレプリカが格納される スレーブノードの障害によるデータの消失防止 • ラックアウェアネスという仕組みにより、レプリカはネットワークや電 源などが異なる系統のスレーブノードに格納することができる ネットワークや電源の障害発生時でも、データの消失を回避 Copyright © 2011 NTT DATA CORPORATION 12
13.
マスターノードは改善の余地あり
MapReduce • JobTrackerがMapReduceフレームワークの制御を集中管理 ジョブ投入の受け口 TaskTrackerが処理しているタスクの進捗状況や、タスク割り当ての スケジューリングを集中管理 JobTrackerが停止した場合、実行中のジョブは停止。新規ジョブ投入不可 HDFS • NameNodeがHDFSを集中管理 HDFSのアクセス受け口 HDFSの管理情報(ファイルシステムイメージ、更新ログ、ブロックと DataNodeの対応表)を集中管理 NameNodeが停止した場合、HDFSにアクセスできなくなり、ファイルの参照 や新規作成ができなくなる。管理情報が消失した場合にはHDFS上のデータ 復元が不可能 Copyright © 2011 NTT DATA CORPORATION 13
14.
いろんな取り組みがある。将来に期待!
MapReduce • NextGeneration Apache Hadoop MapReduceでは、 ZooKeeper(分散コーディネーションサービス)でマスターノードの可 用性を向上 (#MAPREDUCE-279) HDFS • いくつかの方式が提案されている AvatarNode (#HDFS-976) BackupNodeのホットスタンバイへの転用 (#HDFS-2124) High Availability Framework for HDSF NN (#HDFS-1623) 再起動無しでNameNodeの再設定 (#HDFS-1477) Etc... 近い将来にはHadoop自体の仕組みで マスターノードの可用性向上が実現できそうだが・・・ Copyright © 2011 NTT DATA CORPORATION 14
15.
Hadoopだけに こだわっても・・・
Hadoopクラスタから、一歩引いて視野を広げる “Hadoopクラスタのみ”で完結するシステムは存在しない Hadoopクラスタだけ頑張って可用性向上する必要はある・・・? データロード 処理結果の受け渡し 外接システム 外接システム 過去のデータは復旧 Hadoopクラスタ した後、さかのぼって 受け渡しの期限まで ロードすればOK に復旧すればOK Copyright © 2011 NTT DATA CORPORATION 15
16.
充分なレベルって?
Hadoopクラスタから、一歩引いて視野を広げる “Hadoopクラスタのみ”で完結するシステムは存在しない Hadoopクラスタは、全体の一部分でしかない データロード 処理結果の受け渡し • 外接要件など、連携箇所との整合性をとる • 一部分だけ過剰な可用性を追求しない。全体と してのダウンタイム短縮や、SLA遵守を目指す フロントの外接システム 外接システム • シンプルな方式を選択する Hadoopクラスタ (ほかの部分と同じコンセプト/運用方法) Copyright © 2011 NTT DATA CORPORATION 16
17.
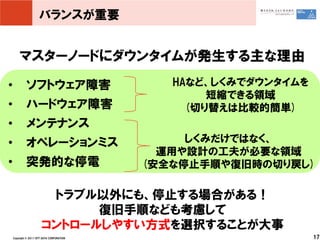
バランスが重要
マスターノードにダウンタイムが発生する主な理由 • ソフトウェア障害 HAなど、しくみでダウンタイムを 短縮できる領域 • ハードウェア障害 (切り替えは比較的簡単) • メンテナンス • オペレーションミス しくみだけではなく、 運用や設計の工夫が必要な領域 • 突発的な停電 (安全な停止手順や復旧時の切り戻し) トラブル以外にも、停止する場合がある! 復旧手順なども考慮して コントロールしやすい方式を選択することが大事 Copyright © 2011 NTT DATA CORPORATION 17
18.
可用性向上の検討指針
実績のある枯れた技術を駆使 • “新しいもの”も魅力的だが、安定性も重視。その時点での”最善 の方法”を、可能な限り選択する • “もっと良い方法”は十分検証し、使い倒して実績を積んでから • 運用のことを考えて、コントロールしやすい方法を選ぶ NTTデータでは、これまでオープンソースを利用したシステム構築を数多く行ってきた。 Pacemaker(Heartbeat)などのHAクラスタリングソフトウェアを用いた可用性向上方式 のノウハウを有している Copyright © 2011 NTT DATA CORPORATION 18
19.
枯れた技術の組み合わせでも充分いける
数百~千台規模のクラスタで実際に採用した方式 • Pacemaker(Heartbeat)などのHAクラスタリングソフトウェアと、DRBDなどのディス クミラーリングソフトウェアを組み合わせる • PostgreSQLなどとHeartbeatを組み合わせた運用実績に裏打ちされた、 確かな選択 • 切り替わりの契機となる監視項目とし て、Hadoop特有の項目も考慮 相互監視 • 切り替えからサービス再開までにかか OSS OSS る時間も考慮(ブロックとDataNodeの Pacemaker Pacemaker 対応表を作るために必要なブロックレ ポートの収集に時間がかかる) OSS OSS データ同期 • “切り替え”だけではなく、”切戻し”の DRBD DRBD 手順も検証し、オペレーションミスの要 因を排除 Copyright © 2011 NTT DATA CORPORATION 19
20.
大量サーバの
運用効率化 Copyright © 2011 NTT DATA CORPORATION 20
21.
大規模なHadoopクラスタの運用上の課題
数百台以上の規模のHadoopクラスタの運用上の課題 初期構築時/設定変更時/ 機器の台数が増えると、いずれか 増設時に1台1台対応して の機器/いずれかの部位に障害 いては、時間がかかる が発生する確率が高い • 複数台同時かつ短時間で効率 • 予期しないときの、予期しないトラブ 的に初期構築/設定変更/増設 ルに備えた対策 を行う • 確実に復旧できる方法を用意し、最 悪の復旧時間を制御する Copyright © 2011 NTT DATA CORPORATION 21
22.
運用設計の検討指針
オペレーションのパターンを最小限に抑える • 統一された運用設計で、オペレーションミスを排除 • 障害発生時の”例外”対応を最小化 • 所要時間の最悪値を制御 クラスタのライフサイクル イベントの共通性に着目し、 で発生するイベント 集約したオペレーションパターン • 初期構築 • OSの自動インストール • 設定変更 複数台のサーバに同時にOSをインス • 増設 トール • 障害回復 • 構成管理 複数のサーバに、一貫した設定を適用 多様な方法がある中で、統一された方法で簡素化する Copyright © 2011 NTT DATA CORPORATION 22
23.
OSの自動インストール/構成管理方式例
OSS • PXEブート + Kickstartで、電源ボタン一つ ポチっとな! でOSインストールが完了 • Puppetにより、複数のサーバで一貫した OSS 設定を適用可能 • 機器交換に伴うヘテロな構成も考慮 • 数ラックずつ同時にOSインストール/設定 • 100台規模のサーバ群をおよそ90分で構築。設 定変更は3分で完了 Copyright © 2011 NTT DATA CORPORATION 23
24.
運用の簡素化のための割り切り
障害復旧において、細かい切り分けは実施しない • OSからのリカバリに失敗する場合は、代替機をセットアップし、 交換する • あらかじめ許容できる縮退率(レプリカの数/処理能力)を把 握し、機器交換のタイミングを計画する(1日の終わり、週末 にまとめて実施するなど) オペレーションの簡素化のためには、割り切りも必要 Copyright © 2011 NTT DATA CORPORATION 24
25.
クラスタの
リソース情報の取得 Copyright © 2011 NTT DATA CORPORATION 25
26.
リソース情報の取得方式例
OSS Gangliaによるリソース情報の可視化 スケールする方式を設計する グループの代表とのみ通信する ので、ボトルネックになりにくい 全体 マスタープロセスが 情報集約 Web上でグラフ表示 ラック単位 サーバ単位 マルチキャストグループを作り、エージェント プロセス同士で情報を共有 Copyright © 2011 NTT DATA CORPORATION 26
27.
[ネタ]
トポロジ設計 Copyright © 2011 NTT DATA CORPORATION 27
28.
電源系統を考慮したトポロジ設計
エッジスイッチごとにラックアウェアネスを構成すると、異なる電 源系統のスレーブサーバにレプリカが作られるとは限らない 電源系統に障害が発生した 場合、データにアクセスできな くなる。データをロストする Copyright © 2011 NTT DATA CORPORATION 28
29.
まとめ Copyright © 2011
NTT DATA CORPORATION 29
30.
まとめ
方式・運用設計の軸となる考え方 ① 部分最適ではなく、全体最適を目指す 割り切るところは割り切る ② 熟知し、実績のある枯れた方法を選択する 安定性も重視した選択 いざという時のために、使い慣れた、コントロールできる方式 ③ 可能な限りシンプルに システムの他の箇所と同じ規約/運用方針。運用のシンプル さを追求し、オペレーションミスの排除 ④ 万が一に備え、最悪のケースを制御する 確実な復旧手順により、障害発生時の最悪復旧時間を制御 実際の運用シーンを想定した手順の整備で確実を期す Copyright © 2011 NTT DATA CORPORATION 30
31.
ご清聴ありがとうございました。 Copyright © 2011
NTT DATA CORPORATION 31








![アジェンダ
マスターノードの可用性向上の検討
大量サーバの運用効率化
クラスタのリソース情報の取得
[ネタ]:トポロジ設計
まとめ
Copyright © 2011 NTT DATA CORPORATION 10](https://image.slidesharecdn.com/hcj11fnttdata20110926-111004022628-phpapp02/85/NTT-Hadoop-10-320.jpg)















![[ネタ]
トポロジ設計
Copyright © 2011 NTT DATA CORPORATION 27](https://image.slidesharecdn.com/hcj11fnttdata20110926-111004022628-phpapp02/85/NTT-Hadoop-27-320.jpg)




































































































