Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
datastaxjp
8,947 views
SparkとCassandraの美味しい関係
Apache CassandraのApache Sparkのお話し
Technology
◦
Read more
28
Save
Share
Embed
Embed presentation
1
/ 43
2
/ 43
3
/ 43
4
/ 43
5
/ 43
6
/ 43
7
/ 43
8
/ 43
9
/ 43
10
/ 43
11
/ 43
12
/ 43
13
/ 43
14
/ 43
15
/ 43
16
/ 43
17
/ 43
18
/ 43
19
/ 43
20
/ 43
21
/ 43
22
/ 43
23
/ 43
24
/ 43
25
/ 43
26
/ 43
27
/ 43
28
/ 43
29
/ 43
30
/ 43
31
/ 43
32
/ 43
33
/ 43
34
/ 43
35
/ 43
36
/ 43
37
/ 43
38
/ 43
39
/ 43
40
/ 43
41
/ 43
42
/ 43
43
/ 43
More Related Content
PPT
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
PPTX
RDB開発者のためのApache Cassandra データモデリング入門
by
Yuki Morishita
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PPTX
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PDF
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Cassandraのしくみ データの読み書き編
by
Yuki Morishita
RDB開発者のためのApache Cassandra データモデリング入門
by
Yuki Morishita
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05)
by
NTT DATA Technology & Innovation
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
What's hot
PDF
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
PPTX
Dockerからcontainerdへの移行
by
Akihiro Suda
PPTX
Oracleからamazon auroraへの移行にむけて
by
Yoichi Sai
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PDF
コンテナ未経験新人が学ぶコンテナ技術入門
by
Kohei Tokunaga
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PPTX
AWSで作る分析基盤
by
Yu Otsubo
PDF
20210127 今日から始めるイベントドリブンアーキテクチャ AWS Expert Online #13
by
Amazon Web Services Japan
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
PDF
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
PDF
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
PDF
マイクロにしすぎた結果がこれだよ!
by
mosa siru
PDF
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
PDF
Snowflakeって実際どうなの?数多のDBを使い倒した猛者が語る
by
Ryota Shibuya
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
PDF
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
PPT
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
PDF
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
PDF
2025年現在のNewSQL (最強DB講義 #36 発表資料)
by
NTT DATA Technology & Innovation
PDF
AWS Database Migration Service ご紹介
by
Amazon Web Services Japan
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
Dockerからcontainerdへの移行
by
Akihiro Suda
Oracleからamazon auroraへの移行にむけて
by
Yoichi Sai
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
コンテナ未経験新人が学ぶコンテナ技術入門
by
Kohei Tokunaga
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
AWSで作る分析基盤
by
Yu Otsubo
20210127 今日から始めるイベントドリブンアーキテクチャ AWS Expert Online #13
by
Amazon Web Services Japan
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
マイクロにしすぎた結果がこれだよ!
by
mosa siru
Apache Kafka 0.11 の Exactly Once Semantics
by
Yoshiyasu SAEKI
Snowflakeって実際どうなの?数多のDBを使い倒した猛者が語る
by
Ryota Shibuya
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
YugabyteDBを使ってみよう(NewSQL/分散SQLデータベースよろず勉強会 #1 発表資料)
by
NTT DATA Technology & Innovation
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
2025年現在のNewSQL (最強DB講義 #36 発表資料)
by
NTT DATA Technology & Innovation
AWS Database Migration Service ご紹介
by
Amazon Web Services Japan
Similar to SparkとCassandraの美味しい関係
PDF
(LT)Spark and Cassandra
by
datastaxjp
PPTX
Cassandra Meetup Tokyo, 2016 Spring
by
datastaxjp
PDF
Cassandra Meetup Tokyo, 2016 Spring
by
Shigeru Harasawa
PDF
[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...
by
Insight Technology, Inc.
PDF
Datastax Enterpriseをはじめよう
by
Yuki Morishita
PDF
Db tech showcase 2016
by
datastaxjp
PDF
Guide to Cassandra for Production Deployments
by
smdkk
PPT
Cassandra v0.6-siryou
by
あしたのオープンソース研究所
PDF
[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう
by
datastaxjp
PPTX
事例で学ぶApache Cassandra
by
Yuki Morishita
PDF
NoSQLとビックデータ入門編Update版
by
Koichiro Nishijima
PDF
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
DOC
cassandra調査レポート
by
Akihiro Kuwano
PDF
高速処理と高信頼性を両立し、ペタバイト級の多種大量データを蓄積する、ビッグデータ/ IoT時代のデータベースとは??
by
griddb
PDF
オープンソースのIoT向けスケールアウト型データベース GridDB 〜性能ベンチマーク結果とOSSを利用したビッグデータ分析環境〜
by
griddb
PPTX
Apache Sparkを使った感情極性分析
by
Tanaka Yuichi
PPTX
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
PPT
Cassandra0.7
by
Kazutaka Tomita
(LT)Spark and Cassandra
by
datastaxjp
Cassandra Meetup Tokyo, 2016 Spring
by
datastaxjp
Cassandra Meetup Tokyo, 2016 Spring
by
Shigeru Harasawa
[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...
by
Insight Technology, Inc.
Datastax Enterpriseをはじめよう
by
Yuki Morishita
Db tech showcase 2016
by
datastaxjp
Guide to Cassandra for Production Deployments
by
smdkk
Cassandra v0.6-siryou
by
あしたのオープンソース研究所
[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう
by
datastaxjp
事例で学ぶApache Cassandra
by
Yuki Morishita
NoSQLとビックデータ入門編Update版
by
Koichiro Nishijima
Cassandraとh baseの比較して入門するno sql
by
Yutuki r
cassandra調査レポート
by
Akihiro Kuwano
高速処理と高信頼性を両立し、ペタバイト級の多種大量データを蓄積する、ビッグデータ/ IoT時代のデータベースとは??
by
griddb
オープンソースのIoT向けスケールアウト型データベース GridDB 〜性能ベンチマーク結果とOSSを利用したビッグデータ分析環境〜
by
griddb
Apache Sparkを使った感情極性分析
by
Tanaka Yuichi
SQL Server 使いのための Azure Synapse Analytics - Spark 入門
by
Daiyu Hatakeyama
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
Cassandra0.7
by
Kazutaka Tomita
More from datastaxjp
PPTX
Cassandra Meetup Tokyo, 2016 Spring 2
by
datastaxjp
PDF
検索エンジンPatheeがAzureとCassandraをどう利用しているのか
by
datastaxjp
PDF
Cassandra v3.0 at Rakuten meet-up on 12/2/2015
by
datastaxjp
PDF
Investigation of Transactions in Cassandra
by
datastaxjp
PDF
Cassandra summit 2015 レポート
by
datastaxjp
PDF
Cassandra Meetup Tokyo, 2015 Summer
by
datastaxjp
PDF
Cassandra and Spark
by
datastaxjp
PDF
[Cassandra summit Tokyo, 2015] Apache Cassandra日本人コミッターが伝える、"Apache Cassandra...
by
datastaxjp
PDF
[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)
by
datastaxjp
PDF
[db tech showcase Tokyo 2015] A27: RDBエンジニアの為のNOSQL, 今どうしてNOSQLなのか?
by
datastaxjp
Cassandra Meetup Tokyo, 2016 Spring 2
by
datastaxjp
検索エンジンPatheeがAzureとCassandraをどう利用しているのか
by
datastaxjp
Cassandra v3.0 at Rakuten meet-up on 12/2/2015
by
datastaxjp
Investigation of Transactions in Cassandra
by
datastaxjp
Cassandra summit 2015 レポート
by
datastaxjp
Cassandra Meetup Tokyo, 2015 Summer
by
datastaxjp
Cassandra and Spark
by
datastaxjp
[Cassandra summit Tokyo, 2015] Apache Cassandra日本人コミッターが伝える、"Apache Cassandra...
by
datastaxjp
[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)
by
datastaxjp
[db tech showcase Tokyo 2015] A27: RDBエンジニアの為のNOSQL, 今どうしてNOSQLなのか?
by
datastaxjp
SparkとCassandraの美味しい関係
1.
©2015 DataStax Confidential.
Do not distribute without consent. Apache Cassandra と Sparkの美味しい関係 1 DataStax 原沢滋 @Cassandrajapan
2.
©2015 DataStax Confidential.
Do not distribute without consent. 最初にApache Cassandraとは
3.
©2015 DataStax Confidential.
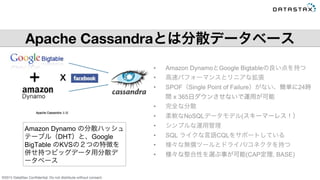
Do not distribute without consent. x Apache Cassandraとは分散データベース Apache Cassandra とは Amazon Dynamo の分散ハッシュ テーブル(DHT)と、Google BigTable のKVSの2つの特徴を 併せ持つビッグデータ用分散 データベース • Amazon DynamoとGoogle Bigtableの良い点を持つ • 高速パフォーマンスとリニアな拡張 • SPOF(Single Point of Failure)がない、簡単に24時 間 x 365日ダウンさせないで運用が可能 • 完全な分散 • 柔軟なNoSQLデータモデル(スキーマーレス!) • シンプルな運用管理 • SQL ライクな言語CQLをサポートしている • 様々な無償ツールとドライバ/コネクタを持つ • 様々な整合性を選ぶ事が可能(CAP定理, BASE) +
4.
©2015 DataStax Confidential.
Do not distribute without consent. 100,000+ ノード 数十ペタバイト 数百万件/秒以上オペレーション 最大クラスタのノード数1,000+ バージョンはv1.2 とv2.0を利用 (写真は昨年のもの)
5.
©2015 DataStax Confidential.
Do not distribute without consent. ソニーにおけるApache Cassandra • Cassandraを6ヶ月でプロダクション • リニアスケーラビリティ • パフォーマンス • ダウンタイムがない • 運用が楽 • コスト データスループット: Gigabytes/sec トランザクション: >200,000/sec データサイズ: Tens of terabytes
6.
©2015 DataStax Confidential.
Do not distribute without consent. NetflixにおけるDataStax Enterprise(DSE) (Apache Cassandra) Netflix は映像ストリーミング配信会社 • Netflix の全データベースのち95%を DSE を 利用 • スループットは1千万トランザクション/秒 • 1日1兆トランザクションをDSE で処理 • 世界各地にある6つのデータセンターの Oracle を置き換え、100%クラウドで実現 • AWSの大規模の再起動の際も全く問題なく24 時間x365日のサービスをCassandraで提供
7.
©2015 DataStax Confidential.
Do not distribute without consent. 7
8.
©2015 DataStax Confidential.
Do not distribute without consent. 8
9.
©2015 DataStax Confidential.
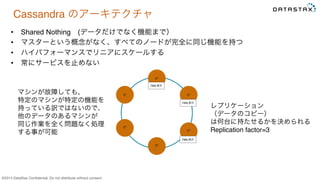
Do not distribute without consent. C* C* C* C*C* C* Cassandra のアーキテクチャ • Shared Nothing (データだけでなく機能まで) • マスターという概念がなく、すべてのノードが完全に同じ機能を持つ • ハイパフォーマンスでリニアにスケールする • 常にサービスを止めない レプリケーション (データのコピー) は何台に持たせるかを決められる Replication factor=3 7369,原沢 7369,原沢 7369,原沢 マシンが故障しても、 特定のマシンが特定の機能を 持っている訳ではないので、 他のデータのあるマシンが 同じ作業を全く問題なく処理 する事が可能
10.
©2015 DataStax Confidential.
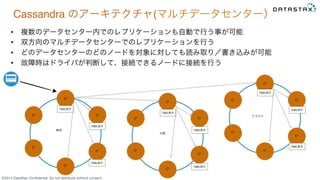
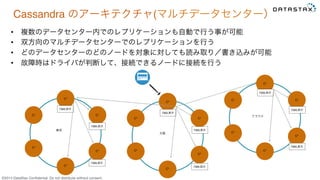
Do not distribute without consent. Cassandra のアーキテクチャ(マルチデータセンター) • 複数のデータセンター内でのレプリケーションも自動で行う事が可能 • 双方向のマルチデータセンターでのレプリケーションを行う • どのデータセンターのどのノードを対象に対しても読み取り/書き込みが可能 • 故障時はドライバが判断して、接続できるノードに接続を行う C* C* C* C* C* C* C* C* C* C* C* C* C* C* C* C* C* C* 東京 大阪 クラウド 7369,原沢 7369,原沢 7369,原沢 7369,原沢 7369,原沢 7369,原沢 7369,原沢 7369,原沢 7369,原沢
11.
©2015 DataStax Confidential.
Do not distribute without consent. Cassandra のアーキテクチャ(マルチデータセンター) • 複数のデータセンター内でのレプリケーションも自動で行う事が可能 • 双方向のマルチデータセンターでのレプリケーションを行う • どのデータセンターのどのノードを対象に対しても読み取り/書き込みが可能 • 故障時はドライバが判断して、接続できるノードに接続を行う C* C* C* C* C* C* C* C* C* C* C* C* C* C* C* C* C* C* 東京 大阪 クラウド 7369,原沢 7369,原沢 7369,原沢 7369,原沢 7369,原沢 7369,原沢 7369,原沢 7369,原沢 7369,原沢
12.
©2015 DataStax Confidential.
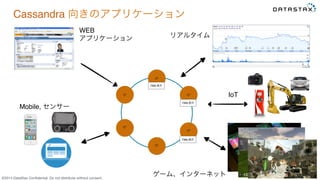
Do not distribute without consent. C* C* C* C*C* C* Cassandra 向きのアプリケーション 7369,原沢 7369,原沢 7369,原沢 WEB アプリケーション Mobile, センサー ゲーム、インターネット IoT リアルタイム
13.
©2015 DataStax Confidential.
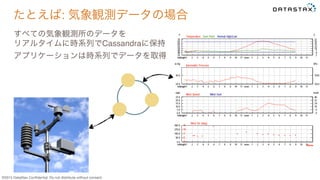
Do not distribute without consent. たとえば: 気象観測データの場合 すべての気象観測所のデータを リアルタイムに時系列でCassandraに保持 アプリケーションは時系列でデータを取得
14.
©2015 DataStax Confidential.
Do not distribute without consent. CREATE TABLE raw_weather_data (! wsid text,! year int,! month int,! day int,! hour int,! temperature double,! dewpoint double,! pressure double,! wind_direction int,! wind_speed double,! sky_condition int,! sky_condition_text text,! one_hour_precip double,! six_hour_precip double,! PRIMARY KEY ((wsid), year, month, day, hour)! ) WITH CLUSTERING ORDER BY (year DESC, month DESC, day DESC, hour DESC);! 気象データを • 気象観測所のIDで検索 • 気象観測所のIDと時間で検索 • 気象観測所のIDと時間の範囲で検索 たとえば: 気象観測データの場合
15.
©2015 DataStax Confidential.
Do not distribute without consent. 渋谷、東京 2015年12月9日 最高気温:17℃ 最低気温:7℃ 平均気温:10℃ でもちょっと統計を取ろうとすると大変 気象観測所のIDで集約統計したテーブルを用意 • 気象観測所のIDで検索 • 気象観測所のIDと時間で検索 • 気象観測所のIDと時間の範囲で検索 CREATE TABLE daily_aggregate_temperature (! wsid text,! year int,! month int,! day int,! high double,! low double,! mean double,! variance double,! stdev double,! PRIMARY KEY ((wsid), year, month, day)! ) WITH CLUSTERING ORDER BY (year DESC, month DESC, day DESC);!
16.
©2015 DataStax Confidential.
Do not distribute without consent. Max, Min, Avgとか使えないの? 使えません 基本すべてのデータに対しての集約関数はCassandraではありません 但し、最新版(CQL 3.3, Cassandra 2.2以降)では、今回のような 場合だと、気象観測所ID(WSID)がPartition Keyなので使えます。 が・・・例えば、東京23区のMax, Min, Avgはダメです でもちょっと統計を取ろうとすると大変
17.
©2015 DataStax Confidential.
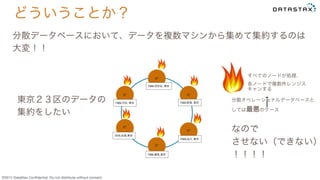
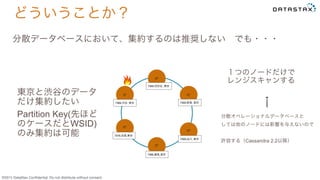
Do not distribute without consent. どういうことか? C* C* C* C*C* C* 7369,渋谷, 東京 7379,目黒,東京 7389,練馬,東京 分散データベースにおいて、データを複数マシンから集めて集約するのは 大変!! 東京23区のデータの 集約をしたい 7369,品川, 東京 7369,新宿, 東京 7369,世田谷, 東京 すべてのノードが処理、 各ノードで複数件レンジス キャンする 分散オペレーショナルデータベースと しては最悪のケース なので させない(できない) !!!!
18.
©2015 DataStax Confidential.
Do not distribute without consent. どういうことか? C* C* C* C*C* C* 7369,渋谷, 東京 7379,目黒,東京 7389,練馬,東京 分散データベースにおいて、集約するのは推奨しない でも・・・ 東京と渋谷のデータ だけ集約したい Partition Key(先ほど のケースだとWSID) のみ集約は可能 7369,品川, 東京 7369,新宿, 東京 7369,世田谷, 東京 1つのノードだけで レンジスキャンする 分散オペレーショナルデータベースと しては他のノードには影響を与えないので 許容する(Cassandra 2.2以降)
19.
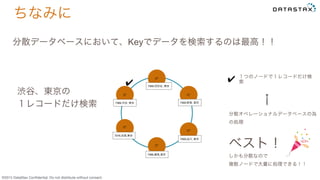
©2015 DataStax Confidential.
Do not distribute without consent. ちなみに C* C* C* C*C* C* 7369,渋谷, 東京 7379,目黒,東京 7389,練馬,東京 分散データベースにおいて、Keyでデータを検索するのは最高!! 渋谷、東京の 1レコードだけ検索 7369,品川, 東京 7369,新宿, 東京 7369,世田谷, 東京 1つのノードで1レコードだけ検 索 分散オペレーショナルデータベースの為 の処理 ベスト! しかも分散なので 複数ノードで大量に処理できる!! ✔ ✔
20.
©2015 DataStax Confidential.
Do not distribute without consent. では、Apache Sparkとは?
21.
©2015 DataStax Confidential.
Do not distribute without consent. Data Science at Scale 2009
22.
©2015 DataStax Confidential.
Do not distribute without consent. Apache Sparkとは Apache Spark is an open source cluster computing framework originally developed in the AMPLab at University of California, Berkeley but was later donated to the Apache Software Foundation where it remains today. In contrast to Hadoop's two-stage disk-based MapReduce paradigm, Spark's multi-stage in-memory primitives provides performance up to 100 times faster for certain applications.[1] By allowing user programs to load data into a cluster's memory and query it repeatedly, Spark is well-suited to machine learning algorithms.[2] Spark requires a cluster manager and a distributed storage system. For cluster management, Spark supports standalone (native Spark cluster), Hadoop YARN, or Apache Mesos.[3] For distributed storage, Spark can interface with a wide variety, including Hadoop Distributed File System (HDFS),[4] Cassandra,[5] OpenStack Swift, Amazon S3, Kudu, or a custom solution can be implemented. Spark also supports a pseudo-distributed local mode, usually used only for development or testing purposes, where distributed storage is not required and the local file system can be used instead; in such a scenario, Spark is run on a single machine with one executor per CPU core. Spark had in excess of 465 contributors in 2014,[6] making it not only the most active project in the Apache Software Foundation[citation needed] but one of the most active open source big data projects.[citation needed 出典:Wikipedia https://en.wikipedia.org/wiki/Apache_Spark • Apache Sparkはopen Source のクラスターコンピューティングフレームワーク • AMPLab (UCB)が開発し、Apacheプロジェクトとなる • HadoopのMapReduceのMapとReduceの二回層の作りではなく、In-Memoryでのマルチ層での処理が可能 • パフォーマンスはMapReduceの100倍?(特定のものでは・・・) • マシーン・ラーナニング向きであるとされる、なぜなら・・・ • SparkはHadoopのように分散の複数のストレージを利用する(大量データ) • クラスターマネージメントとしては、Standalone, YARN, Mesosをサポート • いろいろの分散システムとのインターフェースを持つ(HDFS, Swift, S3, Kudu, CASSANDRA, etc…)
23.
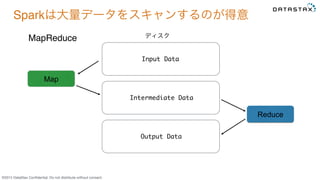
©2015 DataStax Confidential.
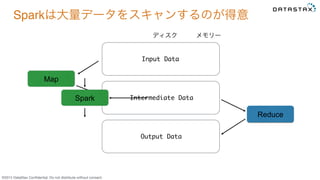
Do not distribute without consent. Sparkは大量データをスキャンするのが得意 Input Data Map Reduce Intermediate Data Output Data ディスクMapReduce
24.
©2015 DataStax Confidential.
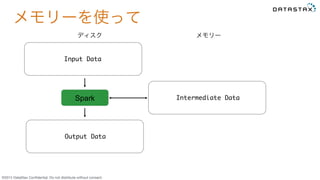
Do not distribute without consent. メモリーを使って Input Data Spark Intermediate Data Output Data ディスク メモリー
25.
©2015 DataStax Confidential.
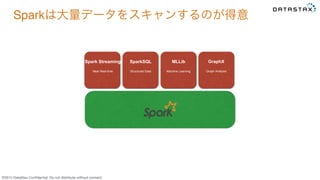
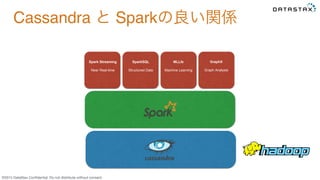
Do not distribute without consent. Spark Streaming Near Real-time SparkSQL Structured Data MLLib Machine Learning GraphX Graph Analysis Sparkは大量データをスキャンするのが得意
26.
©2015 DataStax Confidential.
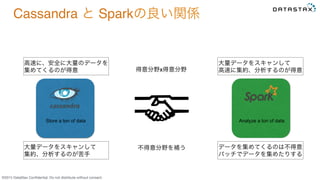
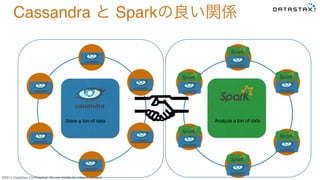
Do not distribute without consent. Store a ton of data Analyze a ton of data Cassandra と Sparkの良い関係 大量データをスキャンして 高速に集約、分析するのが得意 大量データをスキャンして 集約、分析するのが苦手 高速に、安全に大量のデータを 集めてくるのが得意 データを集めてくるのは不得意 バッチでデータを集めたりする 得意分野x得意分野 不得意分野を補う
27.
©2015 DataStax Confidential.
Do not distribute without consent. Spark Streaming Near Real-time SparkSQL Structured Data MLLib Machine Learning GraphX Graph Analysis Cassandra と Sparkの良い関係
28.
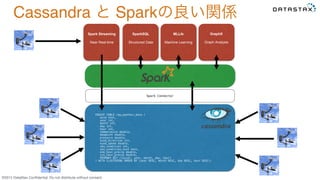
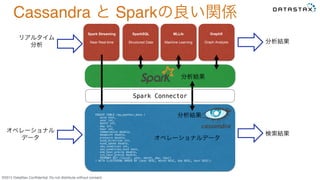
©2015 DataStax Confidential.
Do not distribute without consent. Spark Streaming Near Real-time SparkSQL Structured Data MLLib Machine Learning GraphX Graph Analysis CREATE TABLE raw_weather_data (! wsid text, ! year int, ! month int, ! day int, ! hour int, ! temperature double, ! dewpoint double, ! pressure double, ! wind_direction int, ! wind_speed double, ! sky_condition int, ! sky_condition_text text, ! one_hour_precip double, ! six_hour_precip double, ! PRIMARY KEY ((wsid), year, month, day, hour)! ) WITH CLUSTERING ORDER BY (year DESC, month DESC, day DESC, hour DESC);! Spark Connector! Cassandra と Sparkの良い関係
29.
©2015 DataStax Confidential.
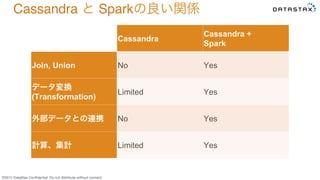
Do not distribute without consent. Cassandra Cassandra + Spark Join, Union No Yes データ変換 (Transformation) Limited Yes 外部データとの連携 No Yes 計算、集計 Limited Yes Cassandra と Sparkの良い関係
30.
©2015 DataStax Confidential.
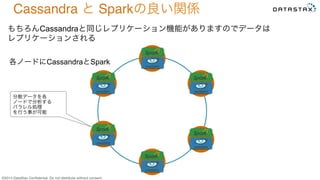
Do not distribute without consent. もちろんCassandraと同じレプリケーション機能がありますのでデータは レプリケーションされる 分散データを各 ノードで分析する パラレル処理 を行う事が可能 各ノードにCassandraとSpark Cassandra と Sparkの良い関係
31.
©2015 DataStax Confidential.
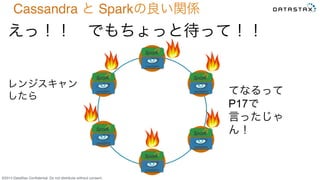
Do not distribute without consent. えっ!! でもちょっと待って!! Cassandra と Sparkの良い関係 てなるって P17で 言ったじゃ ん! レンジスキャン したら
32.
©2015 DataStax Confidential.
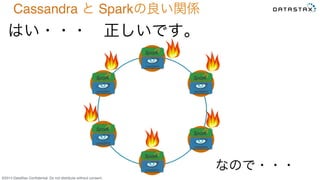
Do not distribute without consent. はい・・・ 正しいです。 Cassandra と Sparkの良い関係 なので・・・
33.
©2015 DataStax Confidential.
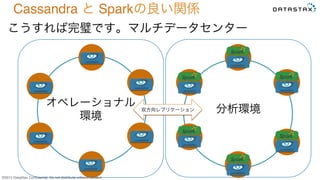
Do not distribute without consent. Cassandra と Sparkの良い関係 こうすれば完璧です。マルチデータセンター オペレーショナル 環境 分析環境双方向レプリケーション
34.
©2015 DataStax Confidential.
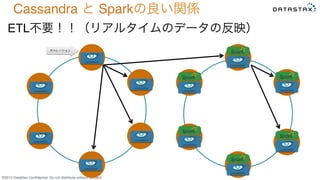
Do not distribute without consent. ETL不要!!(リアルタイムのデータの反映) Cassandra と Sparkの良い関係 オペレーション
35.
©2015 DataStax Confidential.
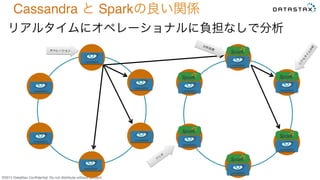
Do not distribute without consent. リアルタイムにオペレーショナルに負担なしで分析 Cassandra と Sparkの良い関係 オペレーション
36.
©2015 DataStax Confidential.
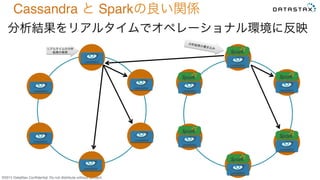
Do not distribute without consent. 分析結果をリアルタイムでオペレーショナル環境に反映 Cassandra と Sparkの良い関係 分析結果の書き込みリアルタイムの分析 結果の検索
37.
©2015 DataStax Confidential.
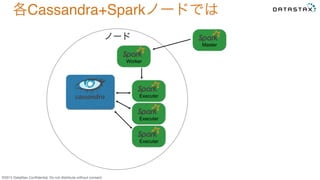
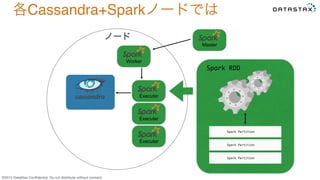
Do not distribute without consent. Executer Master Worker Executer Executer ノード 各Cassandra+Sparkノードでは
38.
©2015 DataStax Confidential.
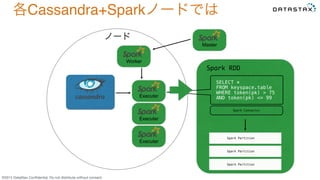
Do not distribute without consent. Executer Master Worker Executer Executer SELECT *! FROM keyspace.table! WHERE token(pk) > 75! AND token(pk) <= 99! Spark RDD Spark Partition! Spark Partition! Spark Partition! Spark Connector! 各Cassandra+Sparkノードでは ノード
39.
©2015 DataStax Confidential.
Do not distribute without consent. Executer Master Worker Executer Executer Spark RDD Spark Partition! Spark Partition! Spark Partition! 各Cassandra+Sparkノードでは ノード
40.
©2015 DataStax Confidential.
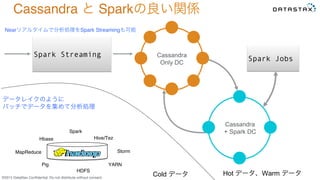
Do not distribute without consent. Cassandra Only DC Cassandra + Spark DC Spark Jobs Spark Streaming Hot データ、Warm データCold データ MapReduce Pig Hive/Tez Spark Storm Hbase HDFS YARN データレイクのように バッチでデータを集めて分析処理 Nearリアルタイムで分析処理をSpark Streamingも可能 Cassandra と Sparkの良い関係
41.
©2015 DataStax Confidential.
Do not distribute without consent. Spark Streaming Near Real-time SparkSQL Structured Data MLLib Machine Learning GraphX Graph Analysis CREATE TABLE raw_weather_data (! wsid text, ! year int, ! month int, ! day int, ! hour int, ! temperature double, ! dewpoint double, ! pressure double, ! wind_direction int, ! wind_speed double, ! sky_condition int, ! sky_condition_text text, ! one_hour_precip double, ! six_hour_precip double, ! PRIMARY KEY ((wsid), year, month, day, hour)! ) WITH CLUSTERING ORDER BY (year DESC, month DESC, day DESC, hour DESC);! Spark Connector! Cassandra と Sparkの良い関係 リアルタイム 分析 オペレーショナル データ 分析結果 検索結果 分析結果 分析結果 オペレーショナルデータ
42.
©2015 DataStax Confidential.
Do not distribute without consent. Store a ton of data Analyze a ton of data Cassandra と Sparkの良い関係
43.
©2015 DataStax Confidential.
Do not distribute without consent. ありがとうございました Twitter account: @cassandrajapanで情報発信しています











![©2015 DataStax Confidential. Do not distribute without consent.
Apache Sparkとは
Apache Spark is an open source cluster computing framework originally developed in the AMPLab at University of California, Berkeley but was later donated to the Apache Software Foundation where it remains today. In
contrast to Hadoop's two-stage disk-based MapReduce paradigm, Spark's multi-stage in-memory primitives provides performance up to 100 times faster for certain applications.[1] By allowing user programs to load data
into a cluster's memory and query it repeatedly, Spark is well-suited to machine learning algorithms.[2]
Spark requires a cluster manager and a distributed storage system. For cluster management, Spark supports standalone (native Spark cluster), Hadoop YARN, or Apache Mesos.[3] For distributed storage, Spark can
interface with a wide variety, including Hadoop Distributed File System (HDFS),[4] Cassandra,[5] OpenStack Swift, Amazon S3, Kudu, or a custom solution can be implemented. Spark also supports a pseudo-distributed
local mode, usually used only for development or testing purposes, where distributed storage is not required and the local file system can be used instead; in such a scenario, Spark is run on a single machine with one
executor per CPU core.
Spark had in excess of 465 contributors in 2014,[6] making it not only the most active project in the Apache Software Foundation[citation needed] but one of the most active open source big data projects.[citation needed
出典:Wikipedia https://en.wikipedia.org/wiki/Apache_Spark
• Apache Sparkはopen Source のクラスターコンピューティングフレームワーク
• AMPLab (UCB)が開発し、Apacheプロジェクトとなる
• HadoopのMapReduceのMapとReduceの二回層の作りではなく、In-Memoryでのマルチ層での処理が可能
• パフォーマンスはMapReduceの100倍?(特定のものでは・・・)
• マシーン・ラーナニング向きであるとされる、なぜなら・・・
• SparkはHadoopのように分散の複数のストレージを利用する(大量データ)
• クラスターマネージメントとしては、Standalone, YARN, Mesosをサポート
• いろいろの分散システムとのインターフェースを持つ(HDFS, Swift, S3, Kudu, CASSANDRA, etc…)](https://image.slidesharecdn.com/apachesparkandcassandra-151210054032/85/Spark-Cassandra-22-320.jpg)































![[db tech showcase Tokyo 2014] L32: Apache Cassandraに注目!!(IoT, Bigdata、NoSQLのバ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014l32datastaxapachecassandraiotbigdatanosql-141120022255-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう](https://cdn.slidesharecdn.com/ss_thumbnails/e35cassandra-150624022814-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[Cassandra summit Tokyo, 2015] Apache Cassandra日本人コミッターが伝える、"Apache Cassandra...](https://cdn.slidesharecdn.com/ss_thumbnails/cassandra-summit-tokyo-2015-yuki-150624053034-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A27: RDBエンジニアの為のNOSQL, 今どうしてNOSQLなのか?](https://cdn.slidesharecdn.com/ss_thumbnails/a27nosqlforrdbengineer-150624020431-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)