Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Cloudera Japan
6,118 views
基礎から学ぶ超並列SQLエンジンImpala #cwt2015
Cloudera World Tokyo 2015 での発表資料です https://clouderaworld.tokyo/
Engineering
◦
Read more
7
Save
Share
Embed
Embed presentation
Download
Downloaded 63 times
1
/ 53
2
/ 53
3
/ 53
4
/ 53
5
/ 53
6
/ 53
7
/ 53
8
/ 53
9
/ 53
10
/ 53
11
/ 53
12
/ 53
13
/ 53
14
/ 53
15
/ 53
16
/ 53
17
/ 53
18
/ 53
19
/ 53
20
/ 53
21
/ 53
22
/ 53
23
/ 53
24
/ 53
25
/ 53
26
/ 53
27
/ 53
28
/ 53
29
/ 53
30
/ 53
31
/ 53
32
/ 53
33
/ 53
34
/ 53
35
/ 53
36
/ 53
37
/ 53
38
/ 53
39
/ 53
40
/ 53
41
/ 53
42
/ 53
43
/ 53
44
/ 53
45
/ 53
46
/ 53
47
/ 53
48
/ 53
49
/ 53
50
/ 53
51
/ 53
52
/ 53
53
/ 53
More Related Content
PDF
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
PDF
Hadoop and Kerberos
by
Yuta Imai
PPT
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
PDF
Db2 & Db2 Warehouse v11.5.4 最新情報アップデート2020年8月25日
by
IBM Analytics Japan
PPTX
Apache Kudu: Technical Deep Dive
by
Cloudera, Inc.
PDF
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PDF
Hive on Tezのベストプラクティス
by
Yahoo!デベロッパーネットワーク
PDF
Deep Dive: Memory Management in Apache Spark
by
Databricks
Apache Impalaパフォーマンスチューニング #dbts2018
by
Cloudera Japan
Hadoop and Kerberos
by
Yuta Imai
インフラエンジニアのためのcassandra入門
by
Akihiro Kuwano
Db2 & Db2 Warehouse v11.5.4 最新情報アップデート2020年8月25日
by
IBM Analytics Japan
Apache Kudu: Technical Deep Dive
by
Cloudera, Inc.
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
Hive on Tezのベストプラクティス
by
Yahoo!デベロッパーネットワーク
Deep Dive: Memory Management in Apache Spark
by
Databricks
What's hot
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
PDF
ログ解析基盤におけるストリーム処理パイプラインについて
by
cyberagent
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
Cephのベンチマークをしました
by
OSSラボ株式会社
PPTX
S3 整合性モデルと Hadoop/Spark の話
by
Noritaka Sekiyama
PDF
Upgrading HDFS to 3.3.0 and deploying RBF in production #LINE_DM
by
Yahoo!デベロッパーネットワーク
PPTX
HDFSネームノードのHAについて #hcj13w
by
Cloudera Japan
PDF
What are latest new features that DPDK brings into 2018?
by
Michelle Holley
PPTX
Practical learnings from running thousands of Flink jobs
by
Flink Forward
PPTX
Apache Tez – Present and Future
by
DataWorks Summit
PDF
IntelON 2021 Processor Benchmarking
by
Brendan Gregg
PPTX
Hive + Tez: A Performance Deep Dive
by
DataWorks Summit
PDF
Performance Analysis of Apache Spark and Presto in Cloud Environments
by
Databricks
PPTX
Kafka Tutorial: Kafka Security
by
Jean-Paul Azar
PDF
Streaming SQL with Apache Calcite
by
Julian Hyde
PDF
Dynamic Partition Pruning in Apache Spark
by
Databricks
PPTX
Revisit DCA, PCIe TPH and DDIO
by
Hisaki Ohara
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
Hadoop -NameNode HAの仕組み-
by
Yuki Gonda
ログ解析基盤におけるストリーム処理パイプラインについて
by
cyberagent
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
Cephのベンチマークをしました
by
OSSラボ株式会社
S3 整合性モデルと Hadoop/Spark の話
by
Noritaka Sekiyama
Upgrading HDFS to 3.3.0 and deploying RBF in production #LINE_DM
by
Yahoo!デベロッパーネットワーク
HDFSネームノードのHAについて #hcj13w
by
Cloudera Japan
What are latest new features that DPDK brings into 2018?
by
Michelle Holley
Practical learnings from running thousands of Flink jobs
by
Flink Forward
Apache Tez – Present and Future
by
DataWorks Summit
IntelON 2021 Processor Benchmarking
by
Brendan Gregg
Hive + Tez: A Performance Deep Dive
by
DataWorks Summit
Performance Analysis of Apache Spark and Presto in Cloud Environments
by
Databricks
Kafka Tutorial: Kafka Security
by
Jean-Paul Azar
Streaming SQL with Apache Calcite
by
Julian Hyde
Dynamic Partition Pruning in Apache Spark
by
Databricks
Revisit DCA, PCIe TPH and DDIO
by
Hisaki Ohara
Similar to 基礎から学ぶ超並列SQLエンジンImpala #cwt2015
PDF
CDHの歴史とCDH5新機能概要 #at_tokuben
by
Cloudera Japan
PDF
Hadoopビッグデータ基盤の歴史を振り返る #cwt2015
by
Cloudera Japan
PPTX
Introduction to Impala ~Hadoop用のSQLエンジン~ #hcj13w
by
Cloudera Japan
PDF
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
PPTX
Impala 2.0 Update 日本語版 #impalajp
by
Cloudera Japan
PDF
Cloudera Impalaをサービスに組み込むときに苦労した話
by
Yukinori Suda
PDF
株式会社インタースペース 守安様 登壇資料
by
leverages_event
PDF
HiveとImpalaのおいしいとこ取り
by
Yukinori Suda
PDF
Evolution of Impala #hcj2014
by
Cloudera Japan
PDF
Impala概要 道玄坂LT祭り 20150312 #dogenzakalt
by
Cloudera Japan
PDF
C5.2 (Cloudera Manager + CDH) アップデート #cwt2014
by
Cloudera Japan
PPTX
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006
by
Cloudera Japan
PPTX
Cloudera Impala Seminar Jan. 8 2013
by
Cloudera Japan
PPTX
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
PDF
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
PDF
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
by
Sho Shimauchi
PDF
Developers.IO 2019 Effective Datalake
by
Satoru Ishikawa
PDF
Cloudera Manager 5 (hadoop運用) #cwt2013
by
Cloudera Japan
PDF
Hive-sub-second-sql-on-hadoop-public
by
Yifeng Jiang
PDF
Cloudera impala
by
外道 父
CDHの歴史とCDH5新機能概要 #at_tokuben
by
Cloudera Japan
Hadoopビッグデータ基盤の歴史を振り返る #cwt2015
by
Cloudera Japan
Introduction to Impala ~Hadoop用のSQLエンジン~ #hcj13w
by
Cloudera Japan
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
Impala 2.0 Update 日本語版 #impalajp
by
Cloudera Japan
Cloudera Impalaをサービスに組み込むときに苦労した話
by
Yukinori Suda
株式会社インタースペース 守安様 登壇資料
by
leverages_event
HiveとImpalaのおいしいとこ取り
by
Yukinori Suda
Evolution of Impala #hcj2014
by
Cloudera Japan
Impala概要 道玄坂LT祭り 20150312 #dogenzakalt
by
Cloudera Japan
C5.2 (Cloudera Manager + CDH) アップデート #cwt2014
by
Cloudera Japan
G-Tech2015 Hadoop/Sparkを中核としたビッグデータ基盤_20151006
by
Cloudera Japan
Cloudera Impala Seminar Jan. 8 2013
by
Cloudera Japan
機械学習の定番プラットフォームSparkの紹介
by
Cloudera Japan
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
Impala データサイエンティストのための 高速大規模分散基盤 #tokyowebmining
by
Sho Shimauchi
Developers.IO 2019 Effective Datalake
by
Satoru Ishikawa
Cloudera Manager 5 (hadoop運用) #cwt2013
by
Cloudera Japan
Hive-sub-second-sql-on-hadoop-public
by
Yifeng Jiang
Cloudera impala
by
外道 父
More from Cloudera Japan
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
PDF
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
PPTX
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
PDF
#cwt2016 Cloudera Managerを用いた Hadoop のトラブルシューティング
by
Cloudera Japan
PDF
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
PDF
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
PPTX
HDFS Supportaiblity Improvements
by
Cloudera Japan
PDF
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
PDF
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
PPTX
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
PDF
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
PDF
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
PDF
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
PDF
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
PDF
HBase Across the World #LINE_DM
by
Cloudera Japan
PDF
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
PDF
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
PDF
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
PDF
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
PPTX
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
Apache Kuduを使った分析システムの裏側
by
Cloudera Japan
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
#cwt2016 Cloudera Managerを用いた Hadoop のトラブルシューティング
by
Cloudera Japan
分散DB Apache Kuduのアーキテクチャ DBの性能と一貫性を両立させる仕組み 「HybridTime」とは
by
Cloudera Japan
#cwt2016 Apache Kudu 構成とテーブル設計
by
Cloudera Japan
HDFS Supportaiblity Improvements
by
Cloudera Japan
Cloudera in the Cloud #CWT2017
by
Cloudera Japan
Cloudera Data Science WorkbenchとPySparkで 好きなPythonライブラリを 分散で使う #cadeda
by
Cloudera Japan
Clouderaが提供するエンタープライズ向け運用、データ管理ツールの使い方 #CW2017
by
Cloudera Japan
大規模データに対するデータサイエンスの進め方 #CWT2016
by
Cloudera Japan
Train, predict, serve: How to go into production your machine learning model
by
Cloudera Japan
先行事例から学ぶ IoT / ビッグデータの始め方
by
Cloudera Japan
Cloud Native Hadoop #cwt2016
by
Cloudera Japan
HBase Across the World #LINE_DM
by
Cloudera Japan
Cloudera のサポートエンジニアリング #supennight
by
Cloudera Japan
How to go into production your machine learning models? #CWT2017
by
Cloudera Japan
Cloudera + MicrosoftでHadoopするのがイイらしい。 #CWT2016
by
Cloudera Japan
Apache Kudu - Updatable Analytical Storage #rakutentech
by
Cloudera Japan
Hue 4.0 / Hue Meetup Tokyo #huejp
by
Cloudera Japan
基礎から学ぶ超並列SQLエンジンImpala #cwt2015
1.
基礎から学ぶ 超並列列SQLエンジンImpala ⽮矢野 智聡 |
Cloudera 株式会社
2.
2© 2015 Cloudera,
Inc. All rights reserved. ⾃自⼰己紹介 • ⽮矢野 智聡(やの ともあき) • Customer Operations Engineer(テクニカルサポート) • お客様がクラスタを運⽤用する上での懸念念や問題の解消を⽀支援
3.
3© 2015 Cloudera,
Inc. All rights reserved. アジェンダ • Impala概要 • 動作概要 • 特徴的な機能と応⽤用 • 2.0 以降降の新機能 • Roadmap
4.
4 © Cloudera,
Inc. All rights reserved. Impala概要
5.
5 © Cloudera,
Inc. All rights reserved. Cloudera Impalaとは • Hadoopクラスタのためのオープンソースの超並列SQLクエリエンジン h>p://impala.io/ • アドホッククエリに焦点を当てたプロダクト
6.
6 © Cloudera,
Inc. All rights reserved. Impalaの特徴 • HDFS や HBase 上のデータに対し、仮想的なビューとしてテーブルを作成し、ク エリを発行できる • メタデータは Hive メタストアを共有 • ODBC / JDBC で接続可能 • Kerberos / LDAP で認証可能 • CDHに含まれており、無料で使用できる(サポートは有償) • Cloudera / Oracle / MapR / Amazon がサポートを提供
7.
7 © Cloudera,
Inc. All rights reserved. Impala開発の背景 • バッチのために開発されたHiveに対してビッグデータ解析の期待とともに分析 ツールの接続が向けられるようになった • アドホッククエリに期待される低レイテンシ、高スループットの処理をHadoop上 で実行することに対する要望 • ImpalaはHiveの数倍-‐数十倍の速度で処理を遂行
8.
8 © Cloudera,
Inc. All rights reserved. Impalaは何でないか • 汎用の処理エンジンではない -‐> SQL処理の高速化に特化するため、専用に書き起されている • 分散環境でバッチ処理を遂行するための耐障害性のあるエンジンではない -‐> 問題発生時に内部リトライを行うのではなく速やかにエラーを返す • Hiveの実施できる処理を全て実行できるわけではない -‐> 大部分の処理を置き換えられ、また随時実装も進んでいるが、全てではな いため注意が必要(例: nested type)
9.
9 © Cloudera,
Inc. All rights reserved. SQL on Hadoopのユースケース • Impala • JDBC/ODBCで接続してインタラクティブな処理を行うツールとの連携 • BI/分析 (例: Tableau, Zoomdata, MicroStrategy, QlikView, SAS等) • アドホックなSQLを直接実行してのデータ探索や分析 • Hive(MapReduce/Spark) • ETLなど耐障害性を重視するバッチ処理 • SparkSQL • Spark処理内でのクエリ • SQLでの処理が主体とならない比較的単純なクエリ ※ CDH5.4系ではHive on Spark/SparkSQL は未サポート
10.
10 © Cloudera,
Inc. All rights reserved. 動作概要
11.
11 © Cloudera,
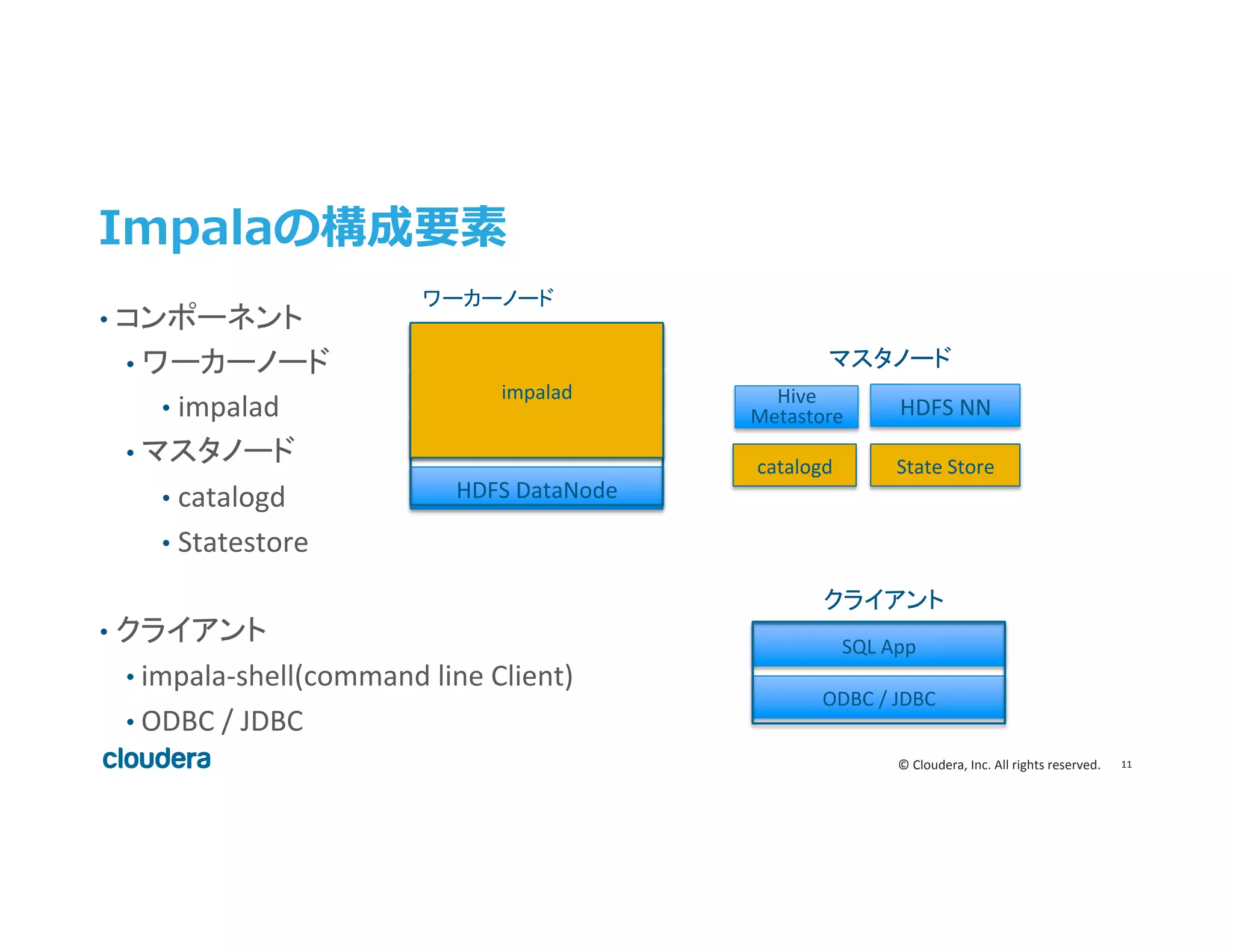
Inc. All rights reserved. Impalaの構成要素 • コンポーネント • ワーカーノード • impalad • マスタノード • catalogd • Statestore • クライアント • impala-‐shell(command line Client) • ODBC / JDBC ODBC / JDBC SQL App クライアント マスタノード Hive Metastore HDFS NN State Store catalogd HDFS DataNode Query Exec Engine Query Coordinator Query Planner impalad ワーカーノード
12.
12 © Cloudera,
Inc. All rights reserved. Impala Daemon (impalad) • HDFSのDataNodeの稼動している全てのノードで動作する • クエリを受けつけ、他のimpaladと連携して実行する中心的なデーモン • どの impalad でもユーザからのクエリを受け付けることが可能 • クエリを受け付ける impalad は、通常「コーディネータノード」と呼ばれる HDFS DataNode Query Exec Engine Query Coordinator Query Planner impalad HDFS DataNode Query Exec Engine Query Coordinator Query Planner impalad HDFS DataNode Query Exec Engine Query Coordinator Query Planner impalad
13.
13 © Cloudera,
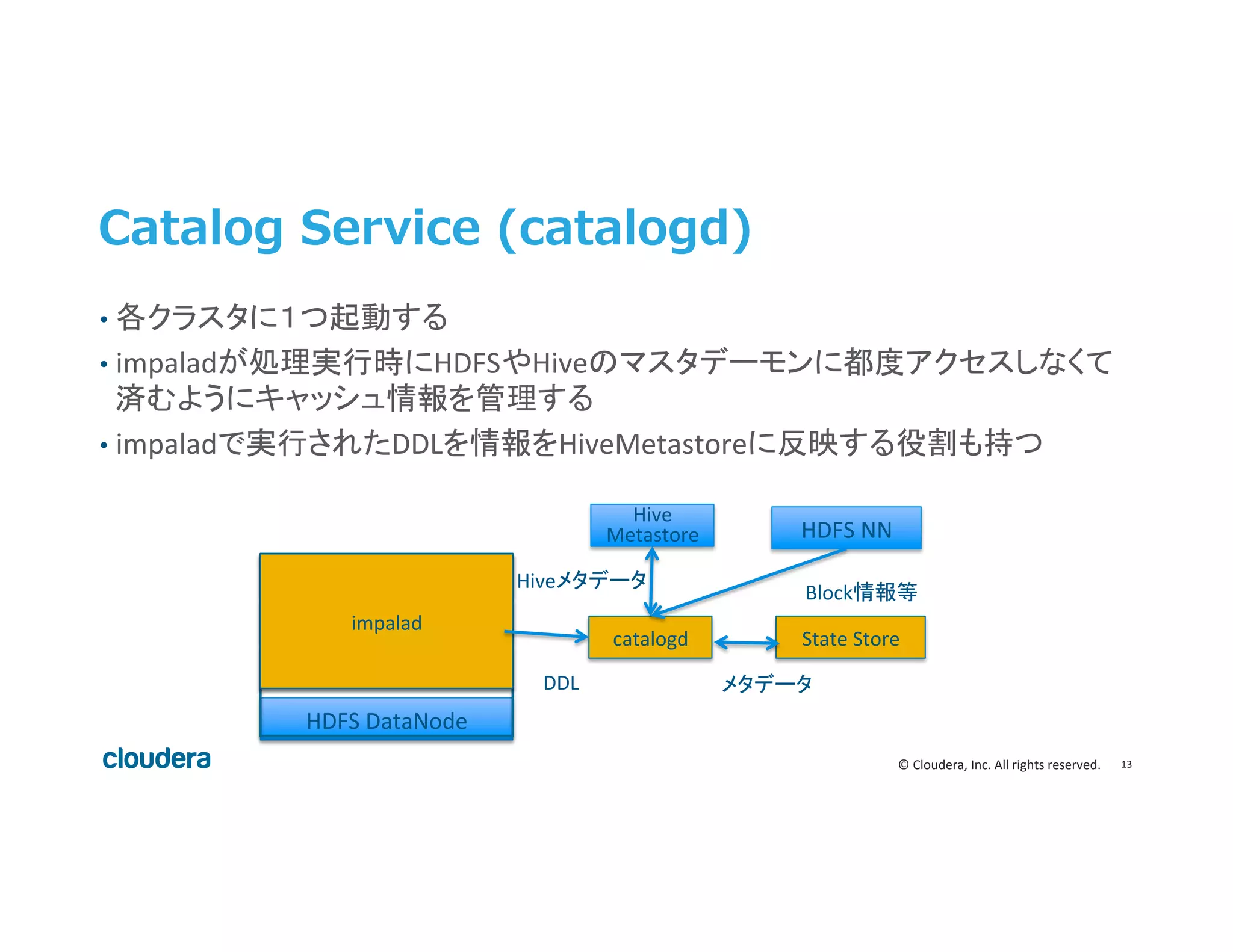
Inc. All rights reserved. Catalog Service (catalogd) • 各クラスタに1つ起動する • impaladが処理実行時にHDFSやHiveのマスタデーモンに都度アクセスしなくて 済むようにキャッシュ情報を管理する • impaladで実行されたDDLを情報をHiveMetastoreに反映する役割も持つ Hive Metastore HDFS NN State Store catalogd HDFS DataNode Query Exec Engine Query Coordinator Query Planner impalad DDL Block情報等 Hiveメタデータ メタデータ
14.
14 © Cloudera,
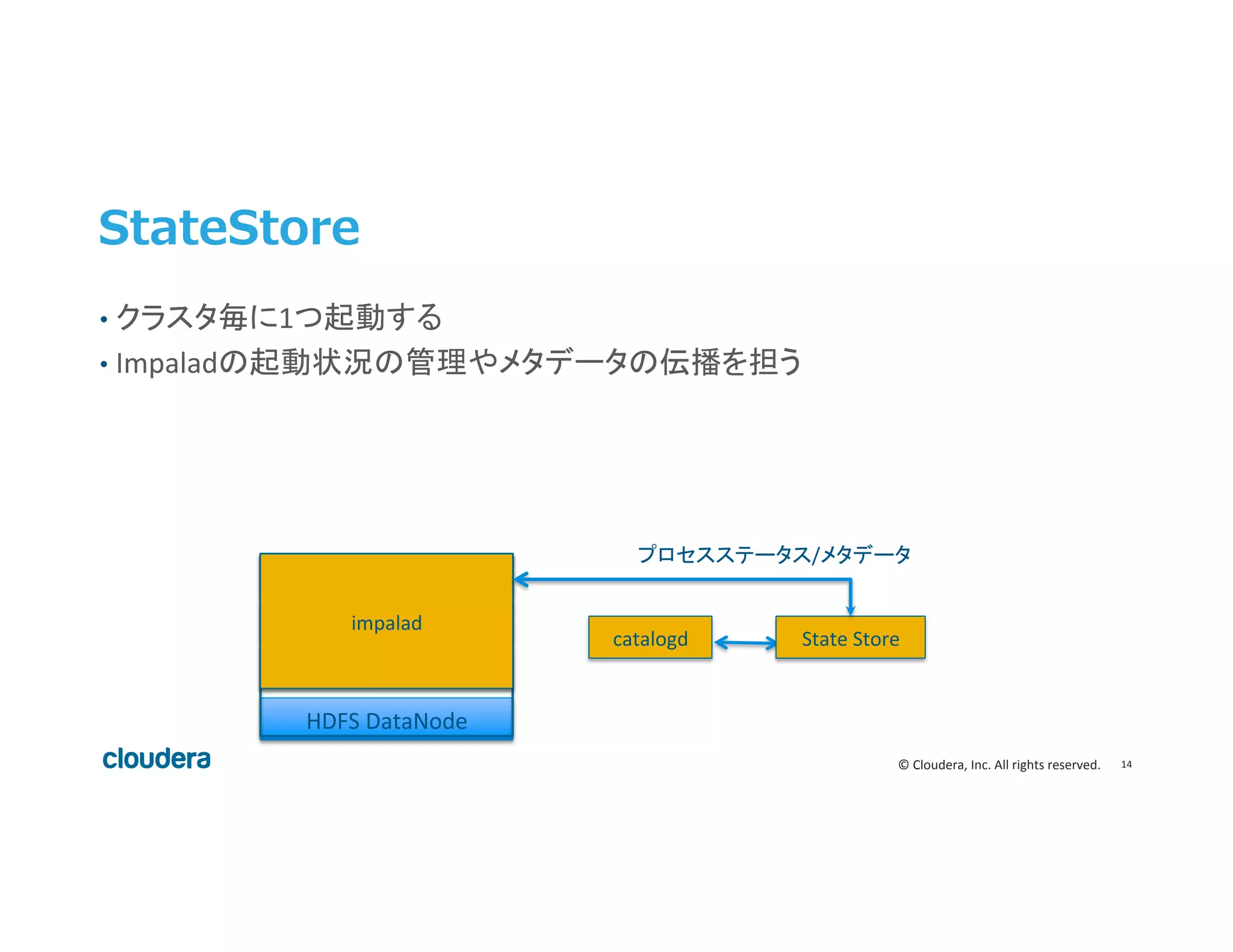
Inc. All rights reserved. StateStore • クラスタ毎に1つ起動する • Impaladの起動状況の管理やメタデータの伝播を担う catalogd HDFS DataNode Query Exec Engine Query Coordinator Query Planner impalad State Store プロセスステータス/メタデータ
15.
15 © Cloudera,
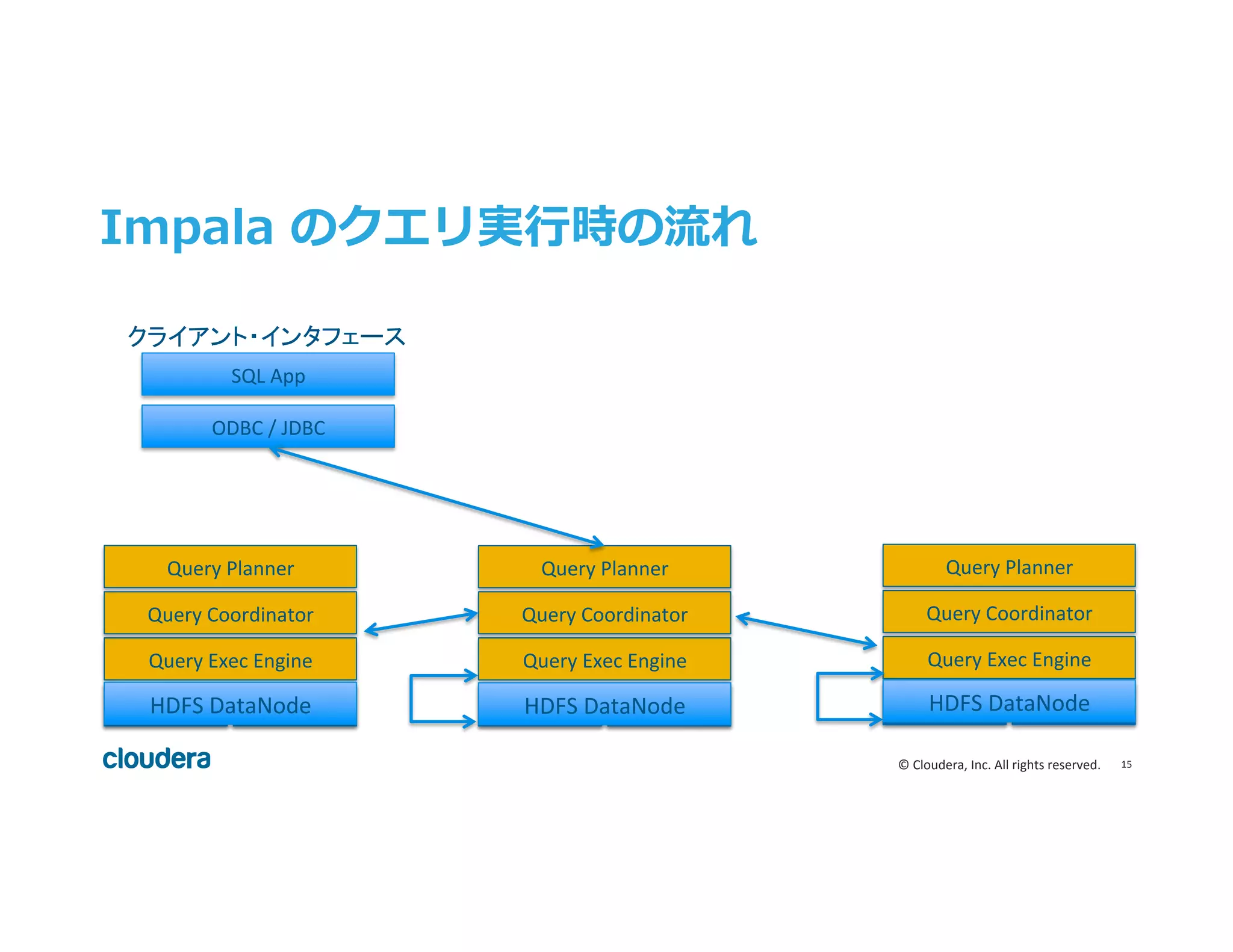
Inc. All rights reserved. Impala のクエリ実⾏行行時の流流れ HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App クライアント・インタフェース HDFS DataNode HDFS DataNode HDFS DataNode
16.
16 © Cloudera,
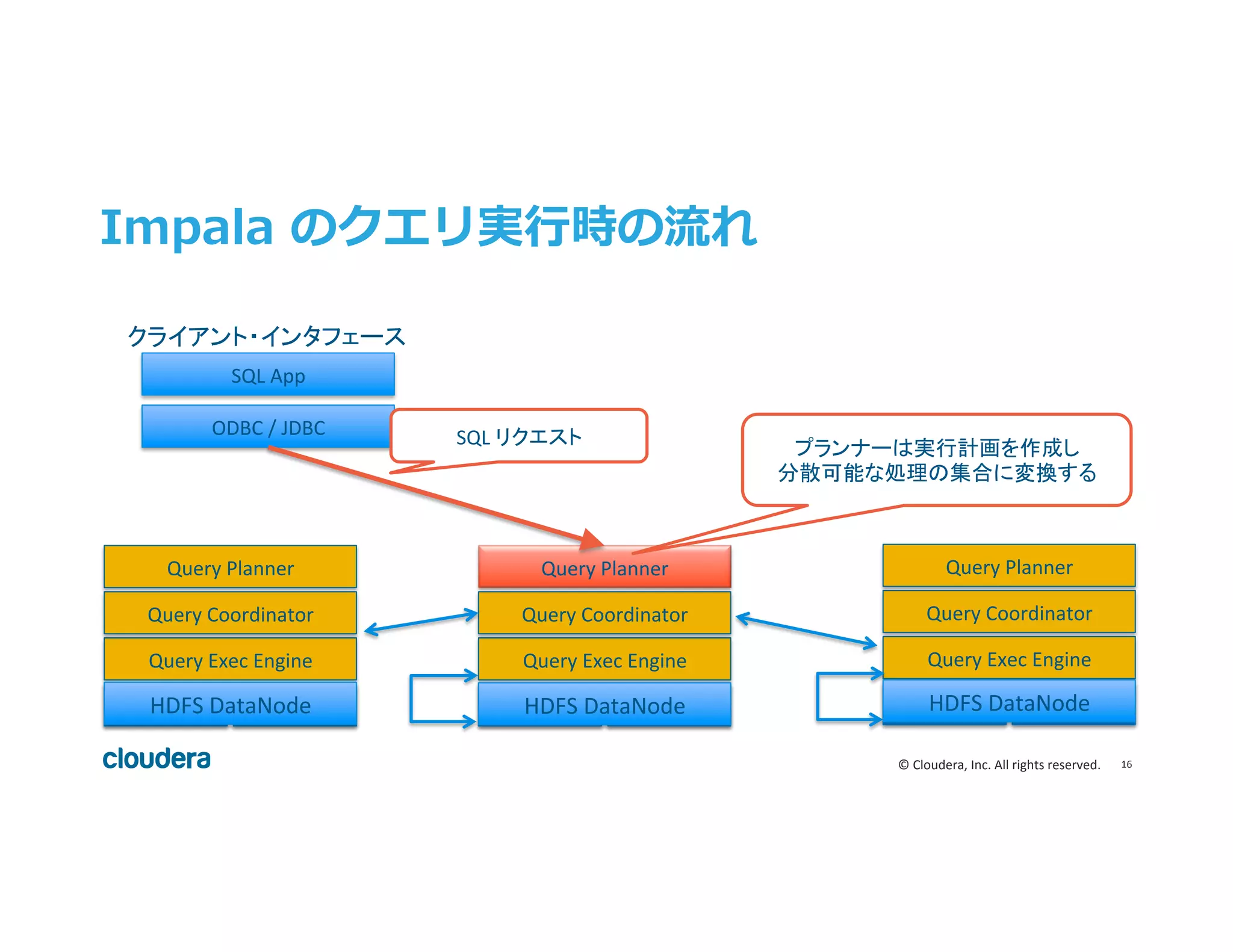
Inc. All rights reserved. Impala のクエリ実⾏行行時の流流れ HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App SQL リクエスト プランナーは実行計画を作成し 分散可能な処理の集合に変換する クライアント・インタフェース HDFS DataNode HDFS DataNode HDFS DataNode
17.
17 © Cloudera,
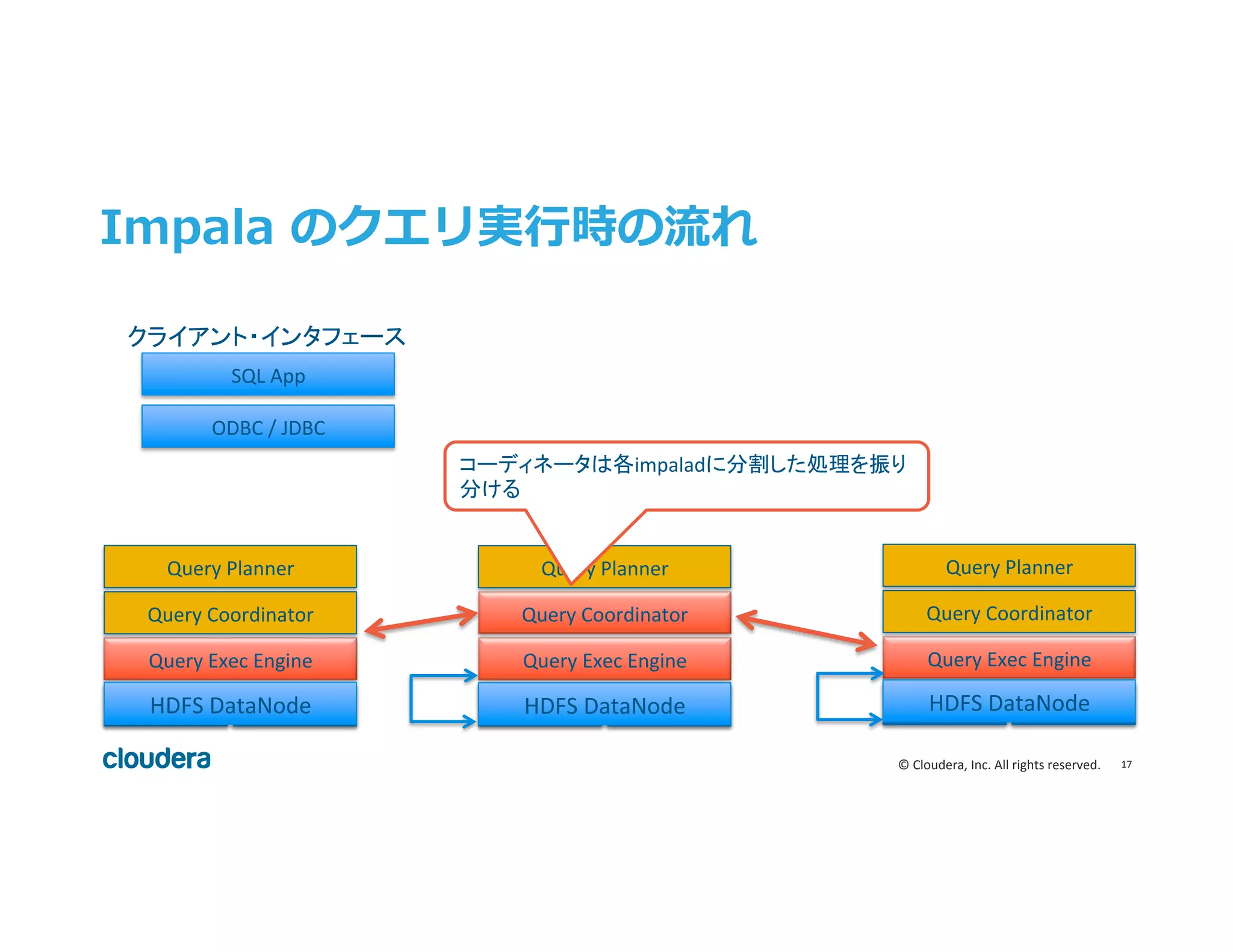
Inc. All rights reserved. Impala のクエリ実⾏行行時の流流れ HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App コーディネータは各impaladに分割した処理を振り 分ける クライアント・インタフェース HDFS DataNode HDFS DataNode HDFS DataNode
18.
18 © Cloudera,
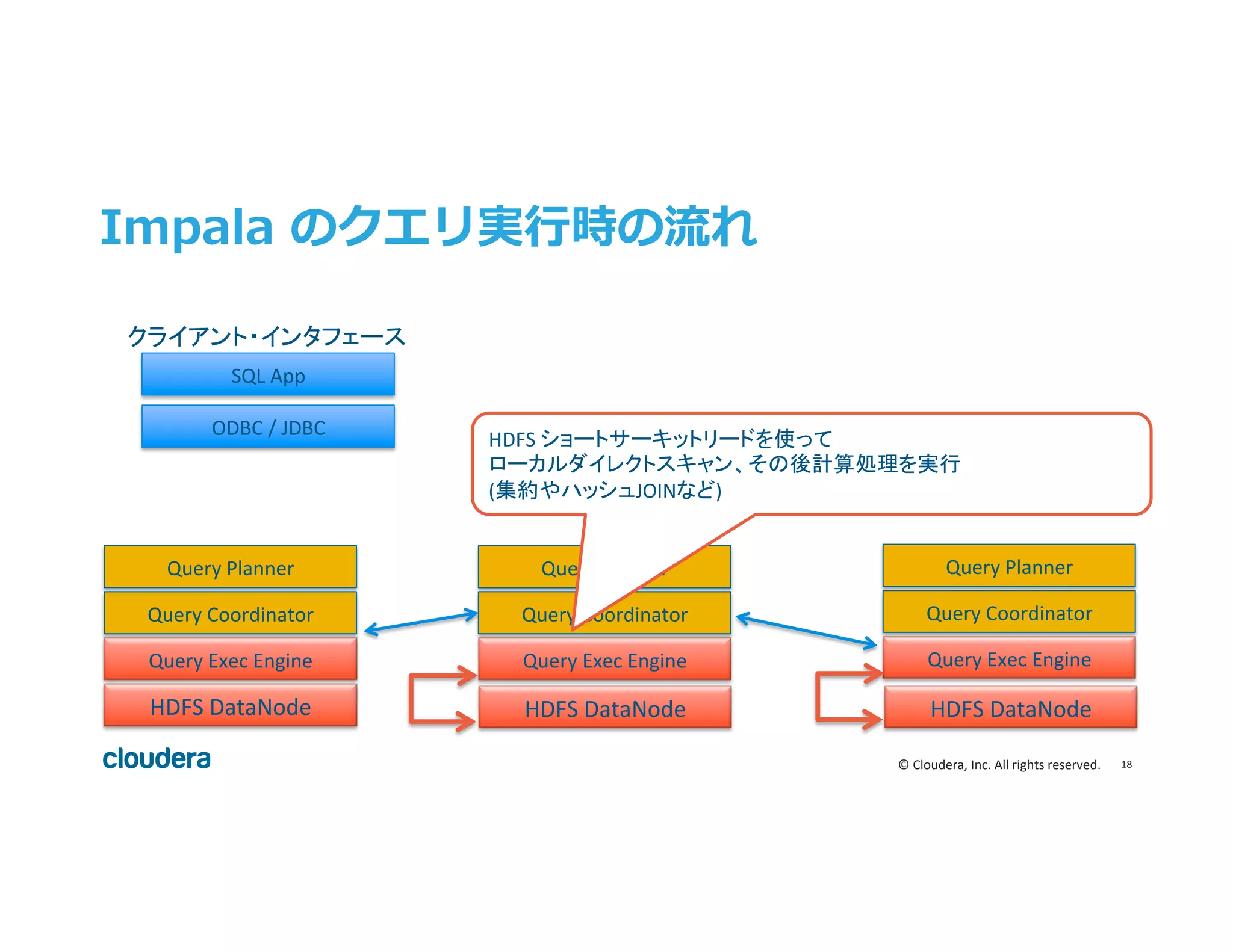
Inc. All rights reserved. Impala のクエリ実⾏行行時の流流れ Query Exec Engine Query Coordinator Query Planner Query Exec Engine Query Coordinator Query Planner HDFS DataNode Query Exec Engine Query Coordinator Query Planner ODBC / JDBC SQL App HDFS ショートサーキットリードを使って ローカルダイレクトスキャン、その後計算処理を実行 (集約やハッシュJOINなど) クライアント・インタフェース HDFS DataNode HDFS DataNode
19.
19 © Cloudera,
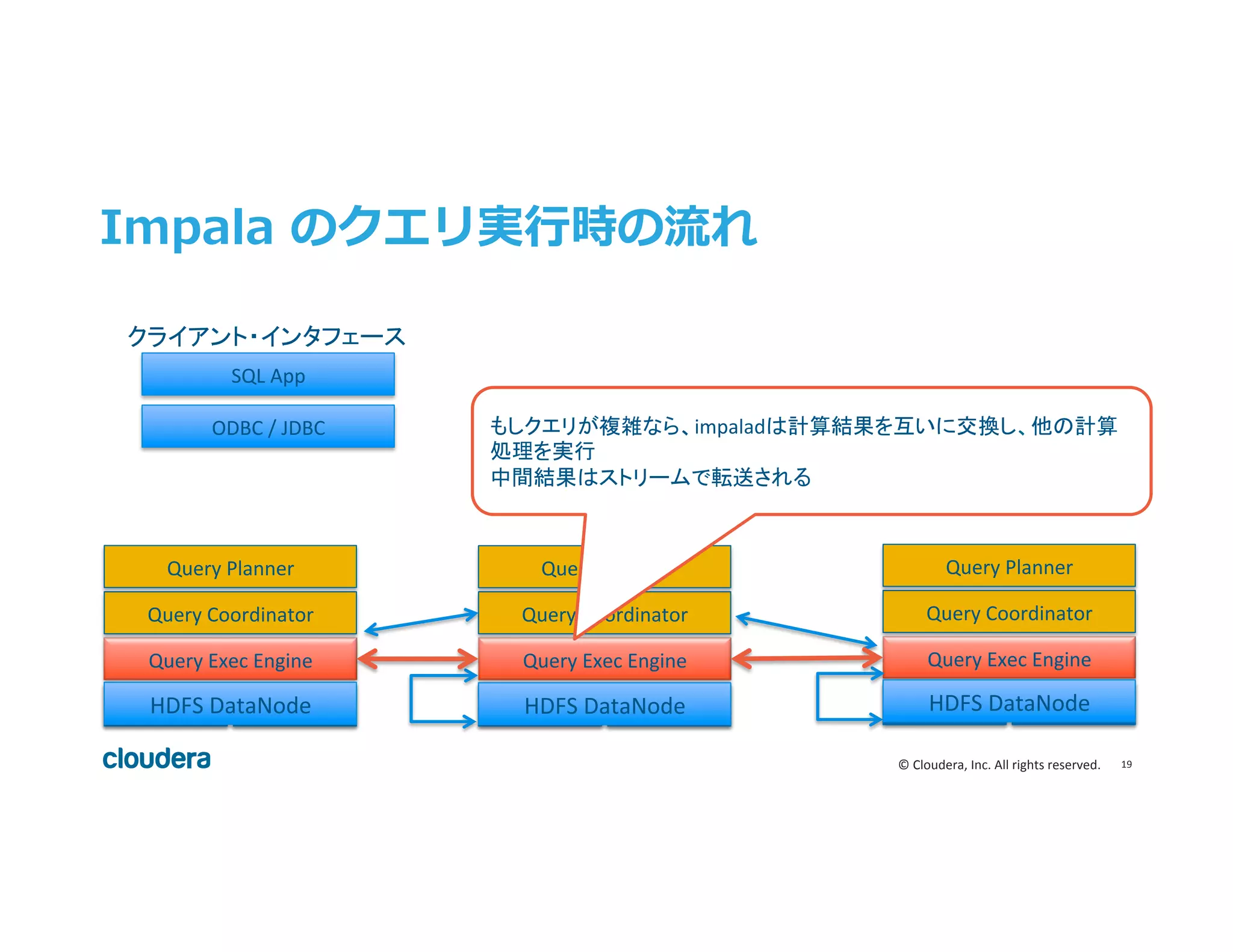
Inc. All rights reserved. Impala のクエリ実⾏行行時の流流れ HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App もしクエリが複雑なら、impaladは計算結果を互いに交換し、他の計算 処理を実行 中間結果はストリームで転送される クライアント・インタフェース HDFS DataNode HDFS DataNode HDFS DataNode
20.
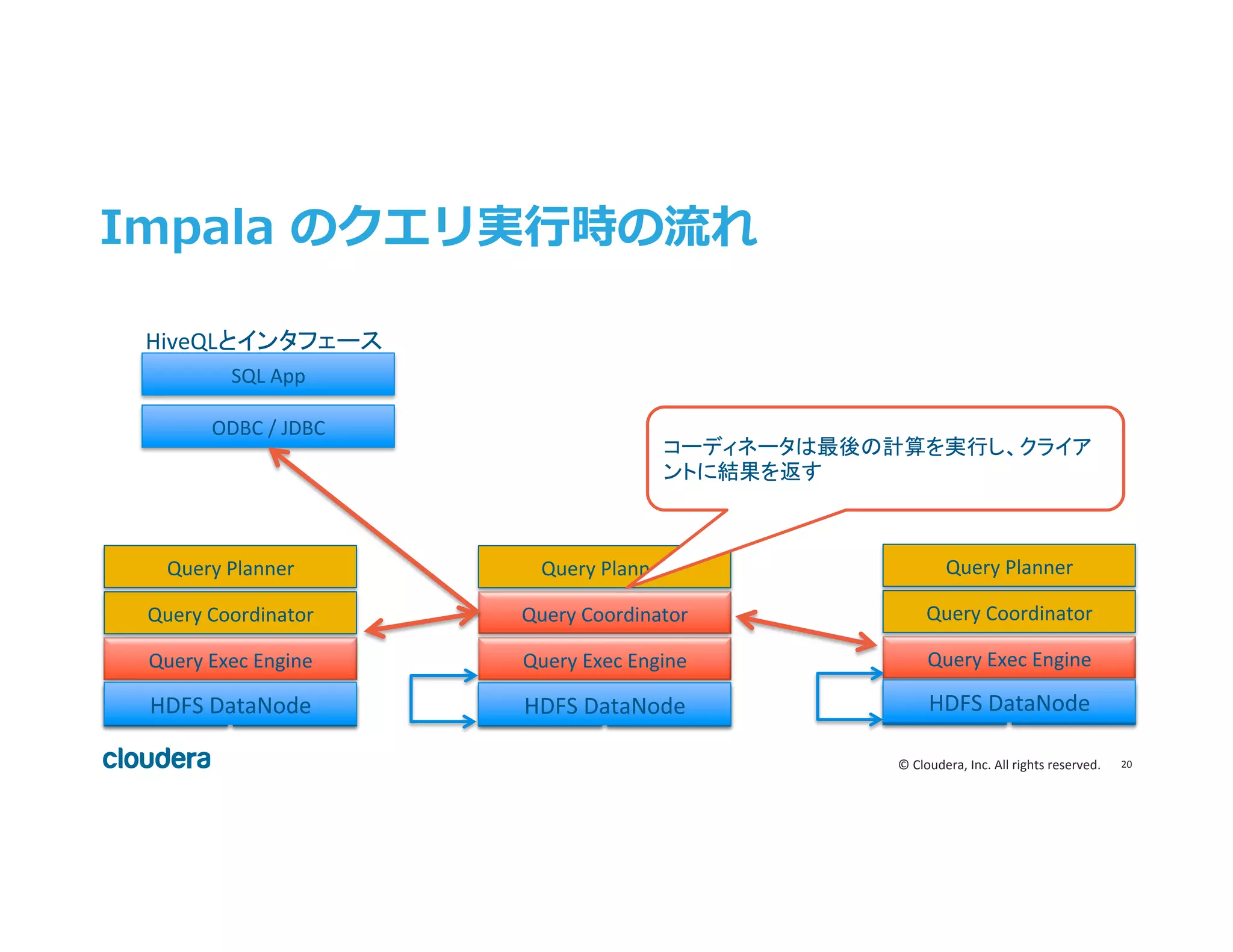
20 © Cloudera,
Inc. All rights reserved. Impala のクエリ実⾏行行時の流流れ HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase HDFS DN Query Exec Engine Query Coordinator Query Planner HBase ODBC / JDBC SQL App HiveQLとインタフェース コーディネータは最後の計算を実行し、クライア ントに結果を返す HDFS DataNode HDFS DataNode HDFS DataNode
21.
21 © Cloudera,
Inc. All rights reserved. クエリ実⾏行行時の処理理のポイント • 他のノードと処理の結果を交換する際にDiskに書き込まない • 高速性と耐障害性のトレードオフ • MapReduceであればDiskに記録しておくことでノード停止などの障害時、内部 的な再実行時使用する • Impalaはクエリ実行中に参加ノードが停止するとクエリが失敗する
22.
22 © Cloudera,
Inc. All rights reserved. 特徴的な機能と応⽤用 エンタープライズ用途を意識した機能と周辺技術
23.
23 © Cloudera,
Inc. All rights reserved. UDF (ユーザ定義関数) • UDF と UDAF(集約関数)をサポート • Impala専用の C++ UDF • Java で書かれた Hive UDF もサポート • Python UDF も開発中 • h>ps://github.com/cloudera/impyla
24.
24 © Cloudera,
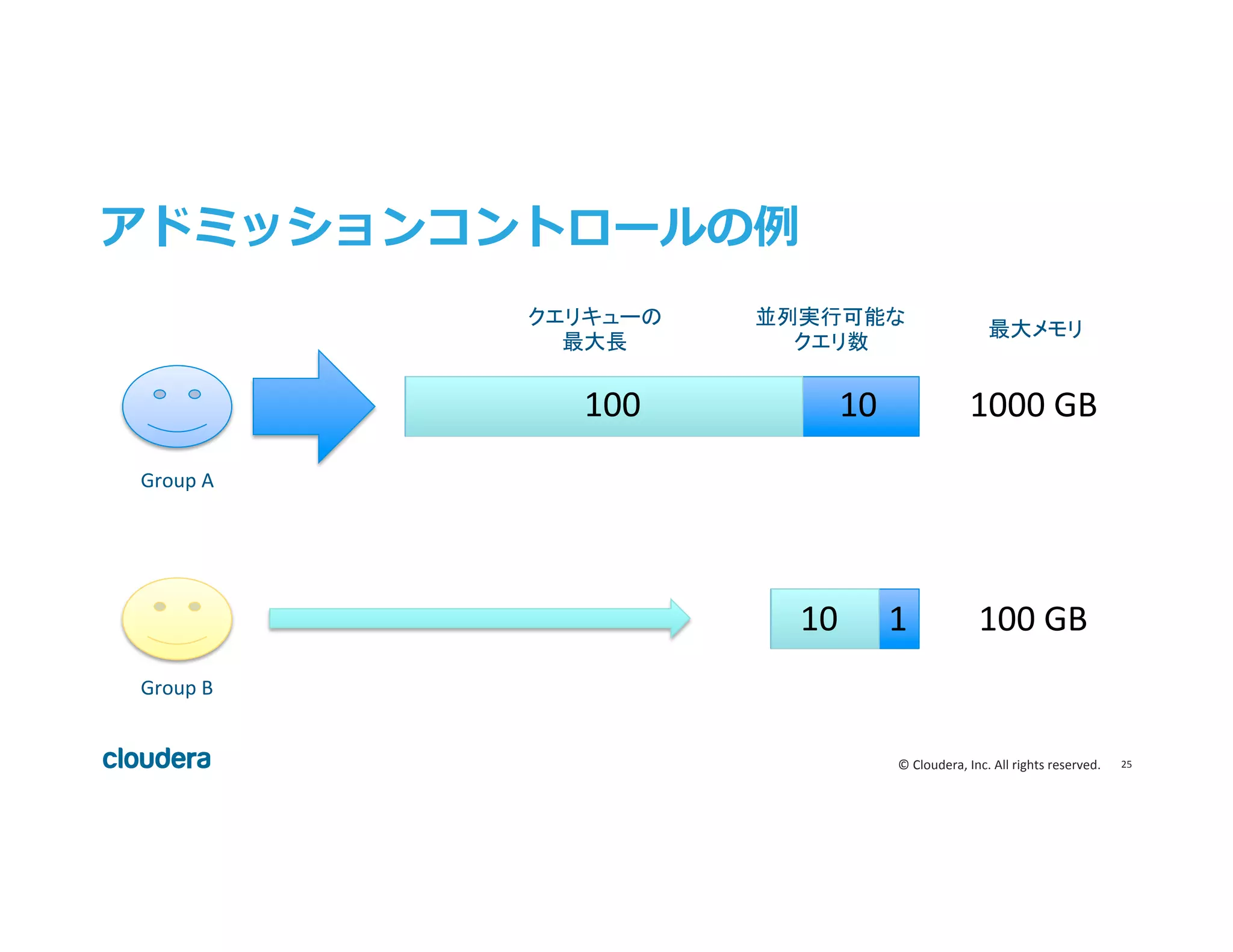
Inc. All rights reserved. アドミッションコントロール • 高速・軽量なリソース管理機構 • 並列ワークロードに対するリソースの過剰利用を避ける • 設定した限界値を超えたらクエリはキューイングされる
25.
25 © Cloudera,
Inc. All rights reserved. アドミッションコントロールの例例 並列実行可能な クエリ数 クエリキューの 最大長 100 10 10 1 最大メモリ 1000 GB 100 GB Group A Group B
26.
26 © Cloudera,
Inc. All rights reserved. Impalaにおけるセキュリティ • 認証(Authenecaeon) • Kerberos/LDAPによる認証 • 許可されたユーザのみが接続できるように制限する • 認可(Authorizaeon) • Sentryによる認可(HDFSのパーミッションとは別) • ユーザがアクセスできるデータの制御 • 監査(Audit) • Cloudera Navigator と連携して監査情報を管理
27.
27 © Cloudera,
Inc. All rights reserved. ストレージ • 圧縮/非圧縮で必要になる容量およびI/O 量が変わる I/Oは展開処理より時間がかかることが多い • 圧縮フォーマットによって展開にかかる時間が変わる bzip2は高圧縮だが、展開に時間がかかる • ファイルの形式でも圧縮効率が異なる 行指向: 通常の形式 列指向: 同形式のデータが続くため圧縮効率が良い
28.
28 © Cloudera,
Inc. All rights reserved. Parquet • Impalaとの親和性の高い列指向フォーマット • ヘッダ情報を元にクエリに必要な列のみを抽出してI/Oを行うことが可能 • Impalaではデフォルト圧縮形式としてで圧縮展開が高速なsnappyフォーマッ トが使用される • 基本的に行指向のデータを元に列指向に組替えるため作成に時間がかかる • データの更新はファイルの再作成となる • 更新が少なく読み込みが多い処理に向く
29.
29 © Cloudera,
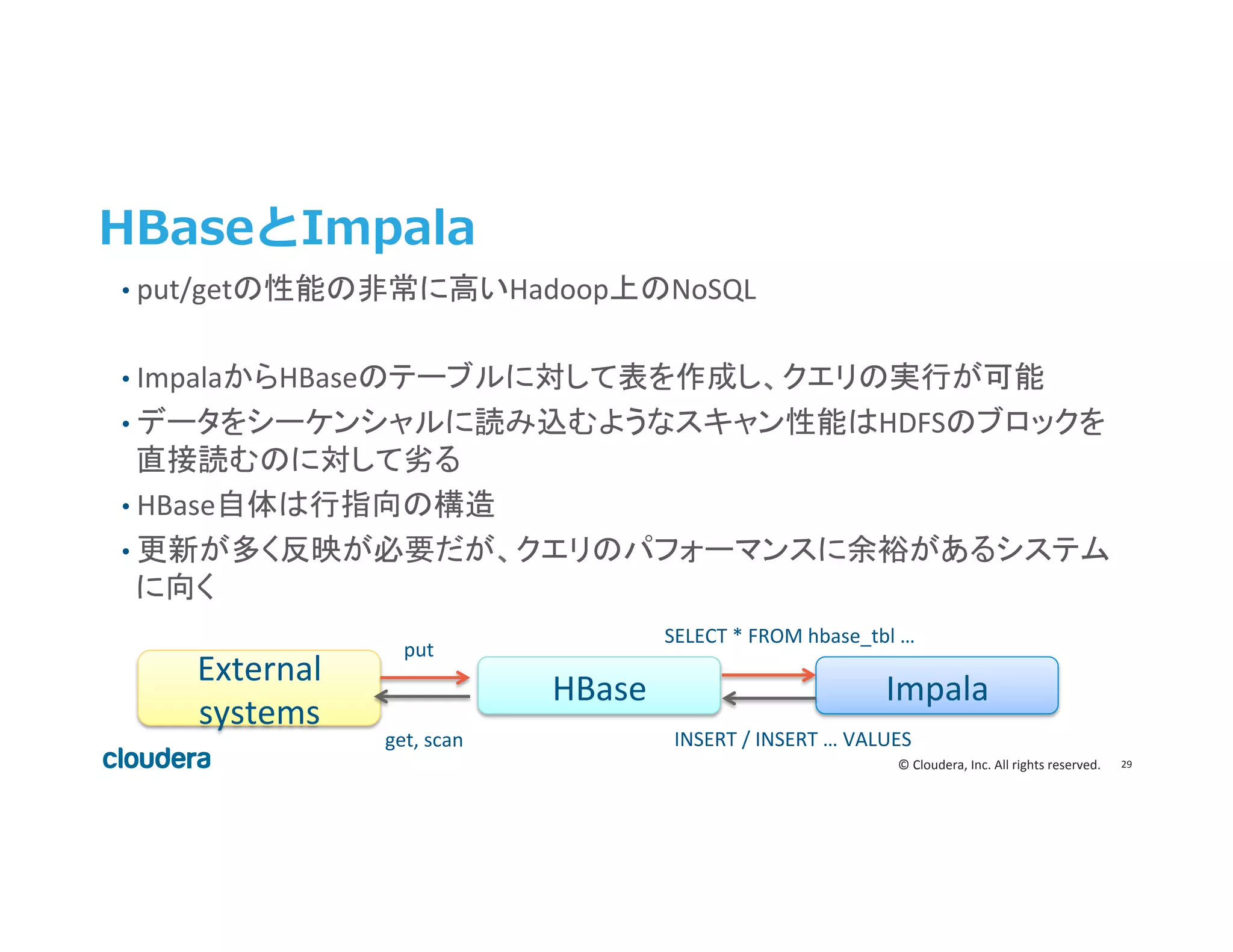
Inc. All rights reserved. HBaseとImpala Impala HBase External systems put SELECT * FROM hbase_tbl … INSERT / INSERT … VALUES get, scan • put/getの性能の非常に高いHadoop上のNoSQL • ImpalaからHBaseのテーブルに対して表を作成し、クエリの実行が可能 • データをシーケンシャルに読み込むようなスキャン性能はHDFSのブロックを 直接読むのに対して劣る • HBase自体は行指向の構造 • 更新が多く反映が必要だが、クエリのパフォーマンスに余裕があるシステム に向く
30.
30 © Cloudera,
Inc. All rights reserved. Kudu • 列指向ストレージサービス • ParquetがHDFS上に作成するファイルのフォーマットなのに対してKuduはスト レージサービス • 追加、更新、削除をリアルタイムに実施可能 • 分析とデータの更新を両方行うシステム向け ※CDH 5.4では未サポート
31.
31 © Cloudera,
Inc. All rights reserved. 2.0以降降の新機能
32.
32 © Cloudera,
Inc. All rights reserved. Impala 2.0(CDH5.2) • 安定性向上 • 結合処理にDisk使用可能(メモリに収まらない場合のDisk spill) • クエリ言語の拡張 • SQL 2003互換のWindow関数の導入(RANK, LAG等) • Where句内でのサブクエリ • 新しいデータ型(VARCHAR, CHAR) • 関数の追加(VAR_SAMP, VAR_POP等)
33.
33 © Cloudera,
Inc. All rights reserved. Impala 2.1(CDH5.3) • 安定性向上 • StateStoreのハートビートとメタ情報更新処理の分離 • メタデータ管理の利便性向上 • 統計情報の増分取得
34.
34 © Cloudera,
Inc. All rights reserved. Impala 2.2(CDH5.4) • ストレージサポートの拡充 • Amazon S3へのダイレクトアクセス(unsupported) • セキュリティ • Cloudera Navigatorとの連携によるカラムレベルの変遷の追跡
35.
35 © Cloudera,
Inc. All rights reserved. Roadmap
36.
36 © Cloudera,
Inc. All rights reserved. 2015年年中の実装が予定されている機能 • クエリ言語の拡張 • Nested type(列への配列などの格納) • ストレージサポートの拡充 • EMC Isilon サポート • 安定性の拡張 • 大規模かつ多ユーザ環境でのスケーラビリティの拡充
37.
37 © Cloudera,
Inc. All rights reserved. 2015/2016初旬の実装が予定されている機能 • クエリ言語の拡張 • 動的パーティションプルーニング • リソース管理 • LlamaによるYARNとのリソース管理の効率化
38.
38 © Cloudera,
Inc. All rights reserved. 2016年年の実装を⽬目標にしている機能 • パフォーマンス向上 • 20倍以上のパフォーマンス向上 (mulecore join/runemeコード生成/HW処理効率化) • インメモリカラムナフォーマット(nested type/UDFのパフォーマンス向上) • メタデータ管理の利便性向上 • 表のメタデータ/統計情報増分更新の自動化 • クエリ言語の拡張 • 一時表(途中経過のDisk Spill) • SQL表現の拡張
39.
39 © Cloudera,
Inc. All rights reserved. まとめ
40.
40 © Cloudera,
Inc. All rights reserved. Cloudera Impala • アドホッククエリに特化したHadoop環境のためのSQLエンジン • 様々なBI/分析ツールと連携可能 • エンタープライズ用途での使用を意図した機能や連携技術 • より安定、高速、かつ利便性の高いシステムを目指し開発が活発に進行中
41.
41 © Cloudera,
Inc. All rights reserved. Impalaを試す
42.
42 © Cloudera,
Inc. All rights reserved. Impalaを試す4つの⽅方法 • WebUI Hue のデモサイト • 手元で実行できるQuickStartVM • Cloud上でのトライアルクラスタ Cloudera Live • Cloudera Managerを使ってインストール
43.
43 © Cloudera,
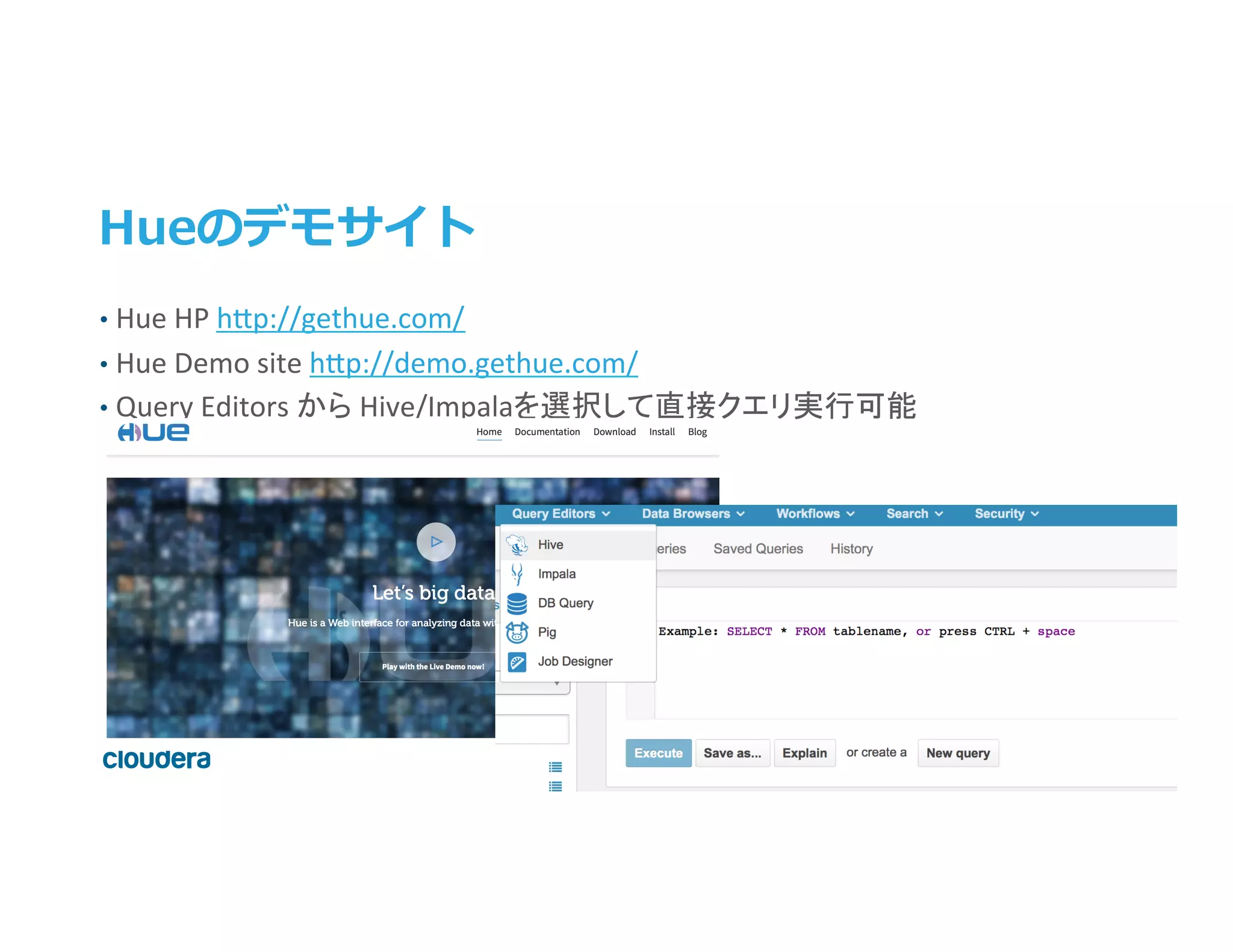
Inc. All rights reserved. Hueのデモサイト • Hue HP h>p://gethue.com/ • Hue Demo site h>p://demo.gethue.com/ • Query Editors から Hive/Impalaを選択して直接クエリ実行可能
44.
44 © Cloudera,
Inc. All rights reserved. QuickStartVM • Download site h>p://www.cloudera.com/content/www/en-‐us/downloads/quickstart_vms/5-‐4.html • シングルノードのVMでCDHの機能を一通り試すことができる • Cloudera Manager(default 無効)を使う場合は8-‐10GBのメモリが必要
45.
45 © Cloudera,
Inc. All rights reserved. Cloudera Live • Web site h>p://www.cloudera.com/content/www/en-‐us/get-‐started/cloudera-‐live.html • Cloud (AWS) 上に展開されるチュートリアル環境(m4.xlarge x 4) • Tableau/Zoomdata(それぞれm4.xlarge +1)と併せて60日間のトライアルを提供 • AWSのインスタンスは実費が必要
46.
46 © Cloudera,
Inc. All rights reserved. Cloudera Managerを使ってインストール • rootユーザでターミナルから下記を実行(TUIでのインストール) • 使用規約を承諾、Readmeも把握済みの場合はバッチでのインストールも可 • 本番環境へのインストールではOSパッケージからのインストールが推奨 $ curl -‐O h>p://archive.cloudera.com/cm5/installer/latest/cloudera-‐manager-‐installer.bin $ chmod 755 cloudera-‐manager-‐installer.bin $ sudo ./cloudera-‐manager-‐installer.bin $ sudo ./cloudera-‐manager-‐installer.bin -‐-‐i-‐agree-‐to-‐all-‐licenses -‐-‐noprompt -‐-‐noreadme
47.
47 © Cloudera,
Inc. All rights reserved. Cloudera Managerでクラスタ構築 2 3 インストールする ロールを割り当てる Cloudera Manager が指定したCDHコン ポーネントをインストールする 自動でホストにロールを割り当てるの で、必要があれば変更する 1 ノードを探す クラスタに組み込むホストの ホスト名を入力
48.
48 © Cloudera,
Inc. All rights reserved. その他
49.
49 © Cloudera,
Inc. All rights reserved. Impalaの技術情報 • Document h>p://www.cloudera.com/content/www/en-‐us/documentaeon/enterprise/ latest/topics/impala.html Impalaを試したあと本格的に検討するにあたっては一読を推奨(英語) • Engineer Blog • h>p://blog.cloudera.com/ Cloudera のエンジニアリングチームによる技術Blog. Impala以外の情報も含め て最新の技術情報が随時提供される(英語)
50.
50 © Cloudera,
Inc. All rights reserved. コミュニティへようこそ • CDH ユーザ メーリングリスト(⽇日本語) cdh-‐‑‒user-‐‑‒jp@cloudera.org Impalaの質問についてはこちら • Cloudera コミュニティ(英語) http://community.cloudera.com/ 登録するとトレーニング10%ディスカウント!
51.
51 © Cloudera,
Inc. All rights reserved. 宣伝 • Hadoopはどのように動くのか ─並列・分散システム技術から読み解くHadoop処理系の設計と実装 h>p://gihyo.jp/admin/serial/01/how_hadoop_works gihyo.jp で連載されている上記の連載にImpalaのパフォーマンスに関わる動作 に焦点をあてた記事を執筆しています。2015年12月-‐2016年1月頃の掲載にな りますのでどうぞお楽しみに。
52.
52 © Cloudera,
Inc. All rights reserved. エンタープライズセールス 大規模システムに関わる営業ができ る人歓迎 セールスエンジニア 技術の価値を伝えることに興味があ る人歓迎 We are hiring! career-‐jp@cloudera.com
53.
Thank you.
Download